INFORMATION
テクノロジ
Apache ManifoldCF -データベースのクロール-
今回はApache ManifoldCFのデータベースのクロールをご説明します。
ManifoldCFの管理画面から設定を行い、実際にクロールを実行して動作を確認します。
この特長は、企業内のデータベースサーバで情報共有しているデータを検索するケースに適しています。たとえば、顧客情報や保守サポート情報など、日々履歴情報が積み上がる情報をデータベースで管理しているとします。このようなケースでは、過去の顧客データを参照したり、ユーザの過去履歴を参照する場面があり、検索が必要になってきます。しかし、データベースサーバによる検索ではパフォーマンスに限界がある場合があります。そこで検索に特化しているSolrを利用することで、より早い検索を実現することができます。ここでSolrとデータベースの間でデータを中継することができるManifoldCFを利用します。
そして、ジョブで各種項目を設定し、実行することでクロールが実行されます。
今回は、各コネクタを次のように設定します。
ファイルサーバをクロールしてデータをSolrに渡すという流れです。
1. ManifoldCFの管理画面を表示します。
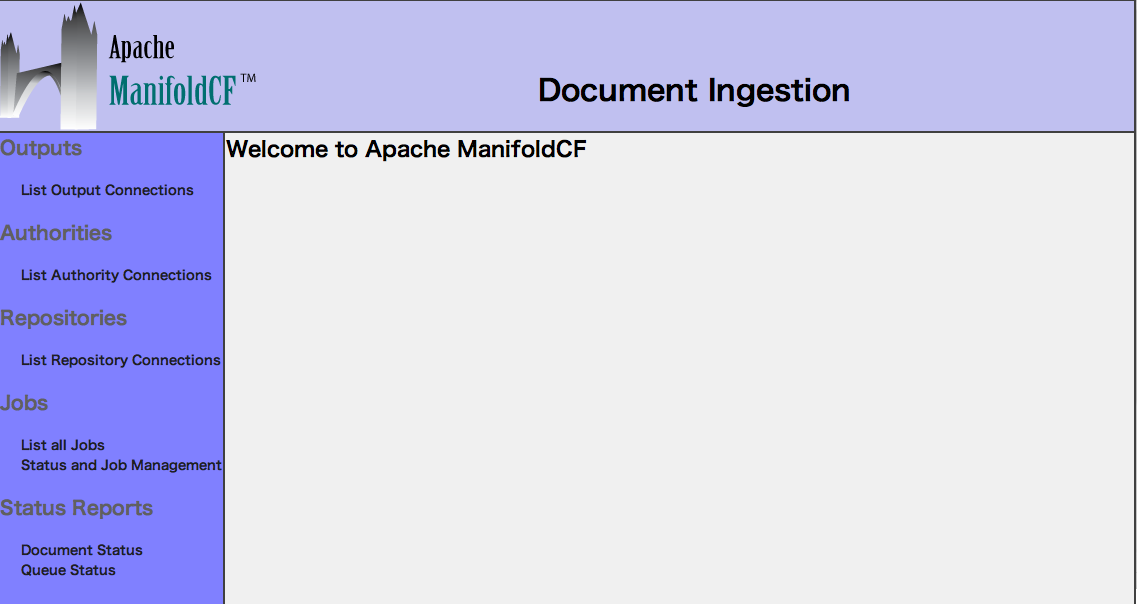
2. List Output Connectionsを選択し、コネクションをAddします。
Nameに「Solr」(任意)を入力し、Typeに「Solr」を選択します。
Continueボタンを押してSolrに関する詳細設定が表示されますが
デフォルトのままで動作するので、変更しません。
最後にSaveボタンを押します。
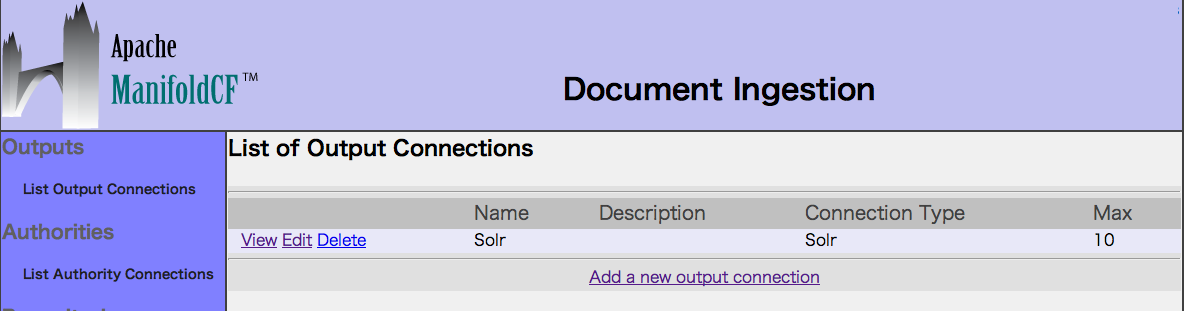
3. List Authority Connectionsを選択し、コネクションをAddします。
Nameに「Null」(任意)を入力し、Typeに「Null」を選択します。
最後にSaveボタンを押します。
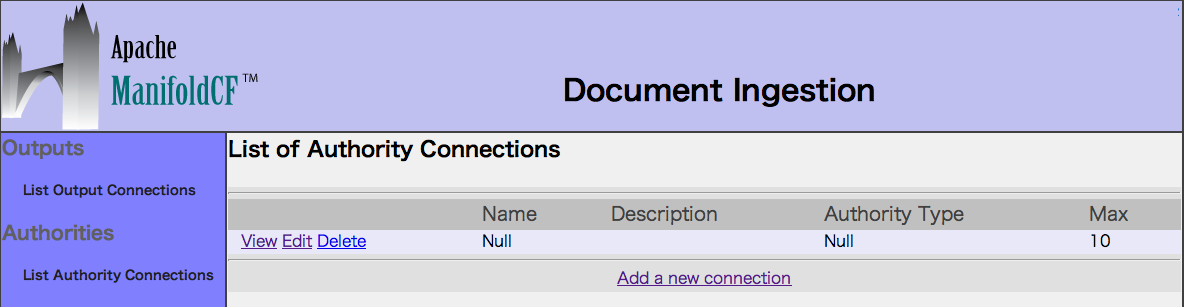
4. List Repository Connectionsを選択し、コネクションをAddします。
Nameに「JDBC」(任意)を入力し、
Typeに「JDBC」を選択し、Authorityに「Null」を選択します。
Continueボタンを押し、Database Typeタブで「Postgre SQL」を選択し、
ServerタブとCredentialsタブでデータベースの接続情報を登録します。
最後にSaveボタンを押します。
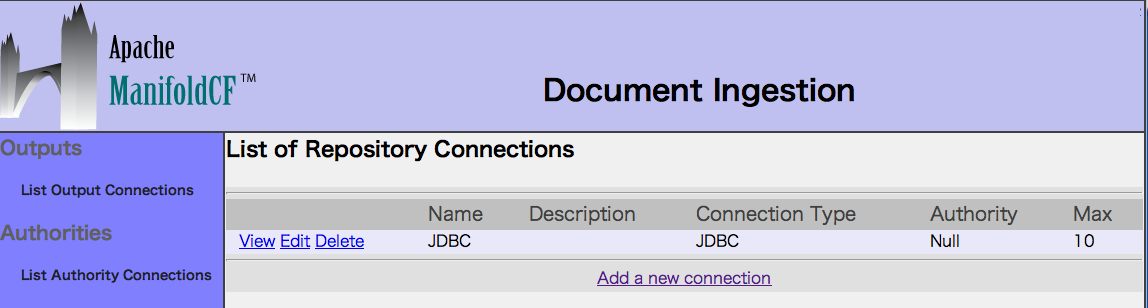
5. List all Jobsを選択し、ジョブをAddします。
Connectionタブで、登録済みコネクションを指定します。
Outputに「Solr」、Repositoryに「JDBC」を選択します。
Continueボタンを押してジョブに関する詳細設定が表示されますが
ここでは、Queriesタブで指定したクエリを確認し変更せずにAddします。
最後にSaveボタンを押します。
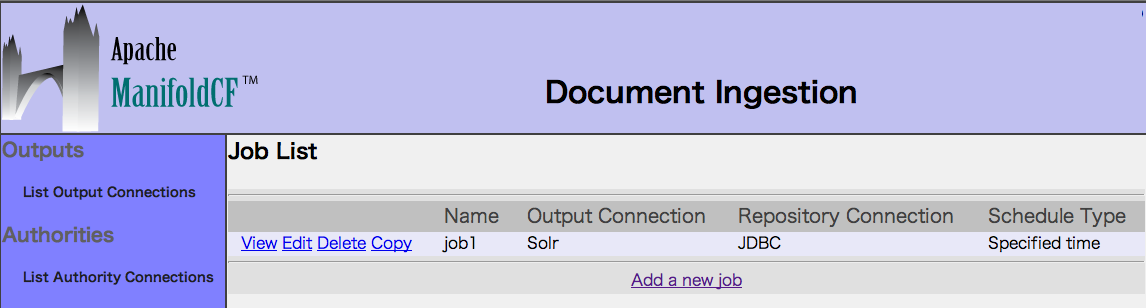
6. Status and Job Managementを選択します。
登録済みジョブのStartをクリックして、クロールを実行します。
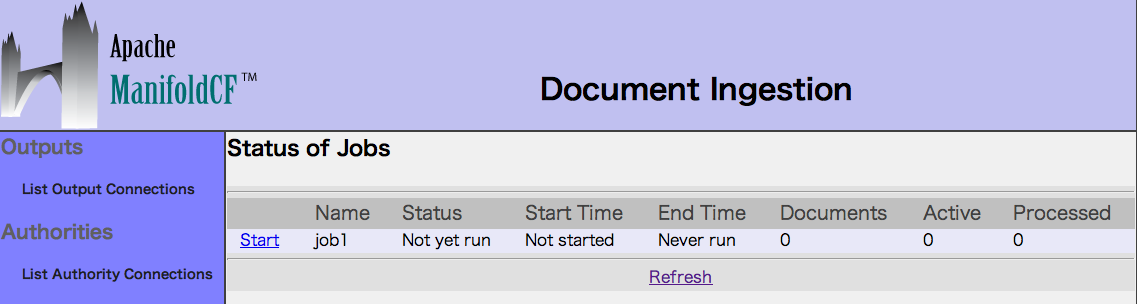
Refreshをクリックするとでジョブの経過を確認することができます。
ステータスにDoneが表示されるとクロールのジョブが終了したことになります。
7. SimpleHistoryを選択します。
レポジトリを選択してContinueボタンを押します。
ジョブの開始終了、ドキュメントのアクセスとSolrへの投入状況など
クロール履歴を確認することができます。
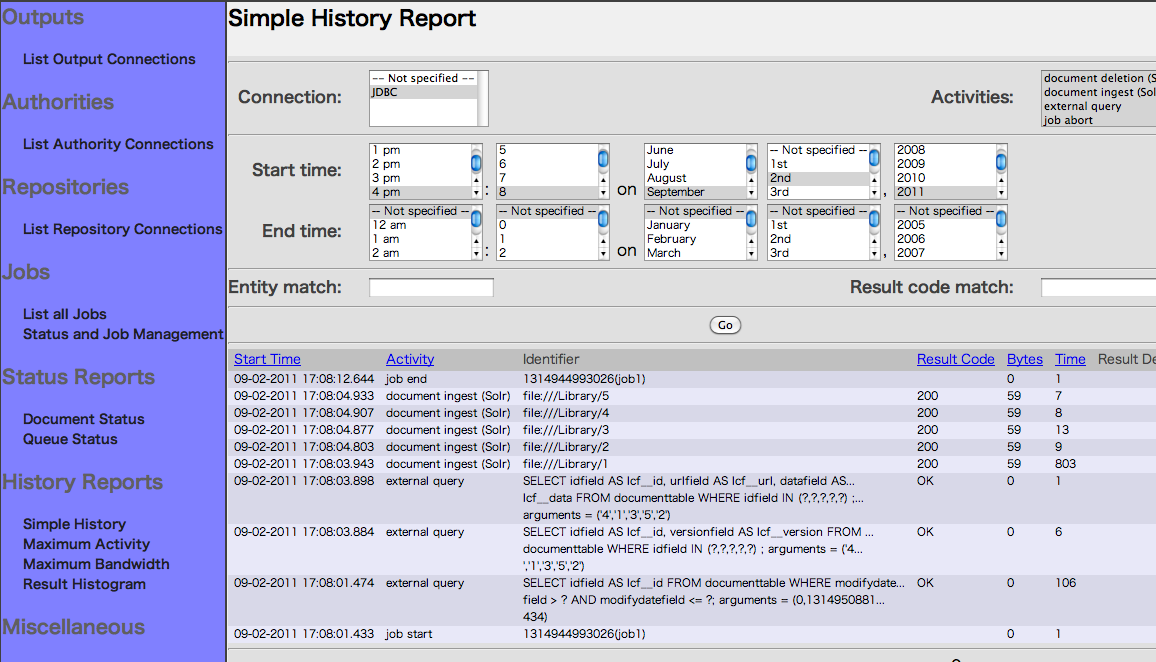
すでに前述までの過程でインデクシングが完了しています。
ここでは、検索を行って内容を確認します。
1. Solrの管理画面を表示します。
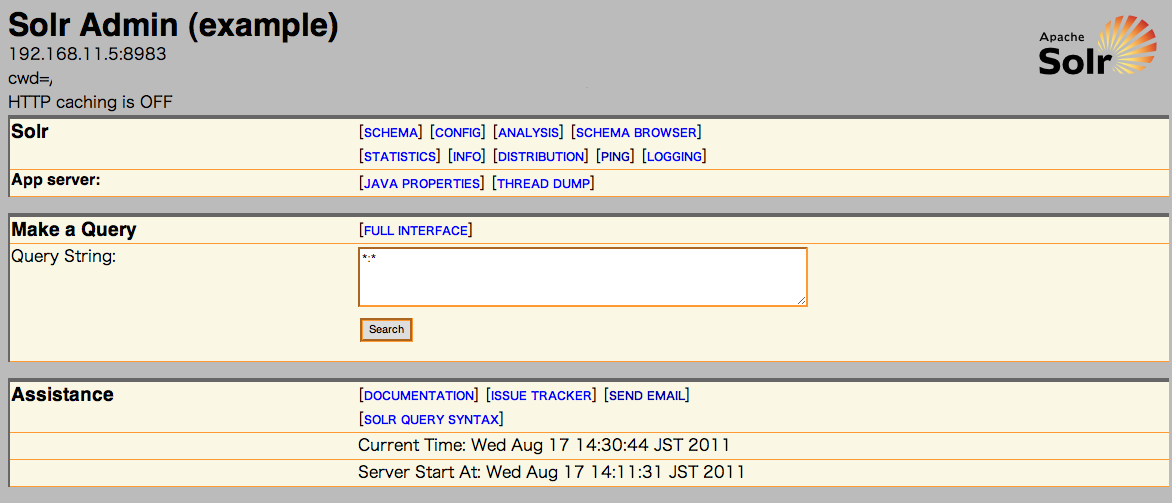
2. 画面中央のsearchボタンを押します。
検索結果が返ってきます。
textフィールドにデータベースのコンテンツが登録されていることを確認します。

以上で、ManifoldCFでデータベースのクロールを行って、Solrでの検索結果を確認しました。
SolrではDataImportHamdlerの機能があり、Solr単体で今回のようなデータベースのクロールをすることが可能です。ManifoldCFと比較して多様な設定をすることが可能ですが、その反面、設定を慎重に定義したり、スケジュールを手で組んだりする作業が必要となります。
しかし、ManifoldCFを利用すれば、上記のような作業をスキップすることができ、
一回設定することでほぼ自動的にクロールすることができます。
ManifoldCFの管理画面から設定を行い、実際にクロールを実行して動作を確認します。
データベース接続によるクロールの特長
ManifoldCFでは、データベースに接続して、クロールすることができます。対応しているデータベースは、PostgreSQL、SQL Server、Oracle、Sybaseです。JDBC経由でデータベースにアクセスし、テーブルまたはビューからコンテンツデータを取得し、Solrに渡すことができます。テーブルの行追加、行更新を管理しながらSolrに渡すべきコンテンツデータを判断できます。また1ジョブにつきセキュリティを設定することも可能です。この特長は、企業内のデータベースサーバで情報共有しているデータを検索するケースに適しています。たとえば、顧客情報や保守サポート情報など、日々履歴情報が積み上がる情報をデータベースで管理しているとします。このようなケースでは、過去の顧客データを参照したり、ユーザの過去履歴を参照する場面があり、検索が必要になってきます。しかし、データベースサーバによる検索ではパフォーマンスに限界がある場合があります。そこで検索に特化しているSolrを利用することで、より早い検索を実現することができます。ここでSolrとデータベースの間でデータを中継することができるManifoldCFを利用します。
準備
- 「Apache ManifoldCF -セットアップ-」に記載されているセットアップ作業を実施します。
- 今回の例では、接続するデータベースはPostgreSQLです。PostgreSQLで、次のようなテーブルまたはビューを用意します。
 列名とデータ型を以下と同じにします。1行が1ドキュメントとします。
ビュー名 documenttable
idfield VARCHAR → テーブルまたはビューのPrimaryKey。
versionfield VARCHAR → 行更新でリビジョンが変わる列。
urlfield VARCHAR → Solrでユニークキーになる列。URIである必要がある。
datafield VARCHAR → Solrでコンテンツとなる列。
modifydatefield BIGINT → idfieldのタイムスタンプ列(今回は1固定)。
列名とデータ型を以下と同じにします。1行が1ドキュメントとします。
ビュー名 documenttable
idfield VARCHAR → テーブルまたはビューのPrimaryKey。
versionfield VARCHAR → 行更新でリビジョンが変わる列。
urlfield VARCHAR → Solrでユニークキーになる列。URIである必要がある。
datafield VARCHAR → Solrでコンテンツとなる列。
modifydatefield BIGINT → idfieldのタイムスタンプ列(今回は1固定)。
ManifoldCFの管理画面
各コネクタを指定してコネクションを作成し、コネクションをひとつのジョブにまとめます。そして、ジョブで各種項目を設定し、実行することでクロールが実行されます。
今回は、各コネクタを次のように設定します。
ファイルサーバをクロールしてデータをSolrに渡すという流れです。
- アウトプット → Solr
- オーソリティ → Null
- レポジトリ → JDBC
1. ManifoldCFの管理画面を表示します。
http://localhost:8345/mcf-crawler-ui
2. List Output Connectionsを選択し、コネクションをAddします。
Nameに「Solr」(任意)を入力し、Typeに「Solr」を選択します。
Continueボタンを押してSolrに関する詳細設定が表示されますが
デフォルトのままで動作するので、変更しません。
最後にSaveボタンを押します。
3. List Authority Connectionsを選択し、コネクションをAddします。
Nameに「Null」(任意)を入力し、Typeに「Null」を選択します。
最後にSaveボタンを押します。
4. List Repository Connectionsを選択し、コネクションをAddします。
Nameに「JDBC」(任意)を入力し、
Typeに「JDBC」を選択し、Authorityに「Null」を選択します。
Continueボタンを押し、Database Typeタブで「Postgre SQL」を選択し、
ServerタブとCredentialsタブでデータベースの接続情報を登録します。
最後にSaveボタンを押します。
5. List all Jobsを選択し、ジョブをAddします。
Connectionタブで、登録済みコネクションを指定します。
Outputに「Solr」、Repositoryに「JDBC」を選択します。
Continueボタンを押してジョブに関する詳細設定が表示されますが
ここでは、Queriesタブで指定したクエリを確認し変更せずにAddします。
最後にSaveボタンを押します。
6. Status and Job Managementを選択します。
登録済みジョブのStartをクリックして、クロールを実行します。
Refreshをクリックするとでジョブの経過を確認することができます。
ステータスにDoneが表示されるとクロールのジョブが終了したことになります。
7. SimpleHistoryを選択します。
レポジトリを選択してContinueボタンを押します。
ジョブの開始終了、ドキュメントのアクセスとSolrへの投入状況など
クロール履歴を確認することができます。
Solrの管理画面
SolrではManifoldCFから渡されてきたデータをインデクシングします。すでに前述までの過程でインデクシングが完了しています。
ここでは、検索を行って内容を確認します。
1. Solrの管理画面を表示します。
http://localhost:8983/solr/admin
2. 画面中央のsearchボタンを押します。
検索結果が返ってきます。
textフィールドにデータベースのコンテンツが登録されていることを確認します。
以上で、ManifoldCFでデータベースのクロールを行って、Solrでの検索結果を確認しました。
SolrではDataImportHamdlerの機能があり、Solr単体で今回のようなデータベースのクロールをすることが可能です。ManifoldCFと比較して多様な設定をすることが可能ですが、その反面、設定を慎重に定義したり、スケジュールを手で組んだりする作業が必要となります。
しかし、ManifoldCFを利用すれば、上記のような作業をスキップすることができ、
一回設定することでほぼ自動的にクロールすることができます。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!