INFORMATION
テクノロジ
Lucene/Solr Revolution 2016 その3
10月13日、14日の日程でUSマサチューセッツ州ボストンで開催されたLucene/Solr Revolution2016の2日目に参加したセッションの内容をレポート致します。
(記事:中山久司)
セッションレポート
聴講したセッションをいくつか簡単にレポートします。
発表スライドやビデオは追って公開される予定です。
Friday, October 14 • 9:10am – 9:40am Using Solr to Activate Data
COMMVAULT社はデータセンターのバックアップ・リカバリでガートナー評価が世界トップの企業で(IBMやEMCよりかなり高評価)ビックデータを扱う米国大手企業です。
開発部門のトップRajivKottomtharayilがSolr関連製品のデモを含めた説明を実施しました。
FusionはミニSolrを各ユーザーのクライアントPCにのせ、サーバー連携して6年分溜まった25GBのメールでも簡単に検索できるというソリューションのデモでした。
クライアントに載せるという発想が新鮮で、デモがあるのでわかりやすかったです。
Edge driveは セキュリティを含めたコンテンツにアクセスできるクラウドストレージで、検索はすべてSolrで行います。 edit,share,tagができるUIを備えていました。Dropboxも検索にSolrを利用していますが、競合かもしれません。
Friday, October 14 • 9:30am – 10:15am Challenges and Thrills of Enterprise Search, Cathy Polinsky, Salesforce

2日目のキーノート・スピーチはSalesforceの検索担当SVP、Cathy Polinksyです。
Salesforceはご存知のように世界第4位のソフトウェア企業でメインはCRMクラウドサービスですが、Solrを利用する検索部分のサイズは以下です。
Friday, October 14 • 10:30am – 11:10am Building and running a Solr-as-a-Service for IBM Watson
イスラエルのIBM研究所に所属するLucene/Solrコミッター Shai Ereraが 高可用性やバージョンアップを考慮したSolrサービスの構成について1000台以上を利用したクラスタの経験を披露しました。
IBMではクラウドベースでSolrが多く使われ以下の課題にチャレンジしています。本番稼働後2年経過した現在のサービスは以下です。
クラウドベースの環境は自動化されて手が出せない部分でフラストレーションもあるが、手間が省けて嬉しいことが多いとのことでした。
Friday, October 14 • 11:20am – 12:00pm Challenges of e-commerce product search and the case study of the Home Depot enterprise search
アメリカ最大の住宅リフォーム小売チェーンであるザ・ホーム・デポのECサイトを構築したSenthil MuruganとRongkai ZhaoがOracle Endecaの拡張性に限界を感じてSolrに移行した経緯と経験を話してくれました。
Zhaoがパラメータチューニングについて、Muruganがビジネス・ルールエンジン について解説しました。
Friday, October 14 • 1:10pm – 1:50pm Customizing Ranking Models in Solr to improve relevance for Enterprise Search
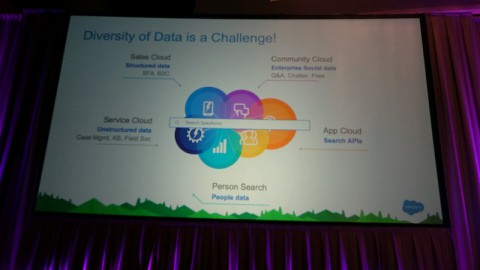
キーノートでSVPが話した内容の技術詳細をSalesforceのSearch Relevance Teamに所属するAmmar HarrisとJoeZeimanがSolrのランキングモデルについて話しました。
SalesforceではLucene標準のtf-idfとブーストデシジョンツリーのようなより複雑なモデルを組み合わせて使用しています。いろいろなランキングモデルを試しながら評価し、よりよい結果となるよう進化させているようです。
ちなみにロンウイットでもお客様と共に最適なランキングを行うために同様の試みをコンサルティングサービスにて実施することがあります。
Friday, October 14 • 2:50pm – 3:30pm Using Apache Solr for Images As Big Data: A Case Study
ビックデータの興味深いトピックとして、画像検索があります。Solr,Spark,HadoopなどApacheの技術が使われることも多い分野ですが、シンプルな利用例を聞くことができました。
Friday, October 14 • 4:00pm – 3:30pm closing kyenote
主催のLucidWork創業者でCTO,ApacheコミッタのGrant Ingersollが元気に再登壇。ビックデータではなく、パーソナルデータ、データはあなたのものと考えることで技術指向のみでなく利活用、ビジネスの方向にも指向しようという話から始まりました。
ペタバイトやQPSなどデータ量のハンドリングの話はエンジニアとしてありますが、何が便利か、何の役に立つかはAskMarketing!でいいのかという問いかけです。(参加者がオープンソース系コアプログラマから一般的エンジニアに拡がっていることも意識しているかもしれません)更にスクリーンにロボットも登場させて、音声などのデータもハンドリングできるより便利なシステムに検索を進化させて行こうという方向性の話があり、もちろん最後に参加者やイベント裏方への感謝の言葉を述べて来年又会おうということですべてのプログラムが締まりました。
全体の感想
IBM,Microsoft,Salesforceといった著名企業のSolr大規模利用事例が実装者から聞けるのがこのカンファレンスに参加するメリットです。
日本から参加されているAmazon、Yahoo、楽天の若きエンジニアの皆さんから伺った話では、日本の各社も技術面では同等以上のようで頼もしいです。
私見ではレガシィな業界の標準的日本企業は2年以上遅れている印象ですが、弊社もお客様のSolr大規模活用を推進すべく微力ならがお手伝いできればと思います。

INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!