INFORMATION
テクノロジ
類義語検索と類義語ハイライト(Solr 6.4.1編)
溝口 泰史 著
はじめに
GoogleやMicrosoft Bingなどで検索を行う場合、検索結果の中に自身が入力した検索ワードがわかるようにその部分を太字にしたり、背景色を変えるなどする工夫が見られます。これをハイライトと呼びます。
また、一般的な検索エンジンに求められる機能として、類義語検索というものがあります。これは、検索ワードとは異なるが類義語(あるいはシノニム)として定義されたワードを含むドキュメントを検索結果として返すことにより、検索結果の再現率を向上させること期待をしてのものです。
弊社が扱っているApache Solrにおいても、当然ハイライト機能を利用することができ、類義語検索を行うことができますが、これらの2つを組み合わせた場合にハイライトの位置がずれるという問題があることが知られていました。
Solr 6.4.0ではこの問題に対応する新機能が追加されました。 本稿では追加された新機能と従来の機能の振る舞いを比較しつつ、適切な検索結果を得られ、検索結果に対して適切なハイライトを行うための設定内容について検討します。
目次
- SynonymGraphFilterとSynonymFilter
- 検証環境:managed-schemaの設定とサンプルデータ
- (インデクシング時) JapaneseTokenizer + SynonymFilter
- (インデクシング時) JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter
- (クエリ時) JapaneseTokenizer + SynonymGraphFilter
- (インデクシング、クエリ時) JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter
- 中間まとめ(SynonymFilterとSynonymGraphFilterの比較、SynonymGraphFilterをどのタイミングで利用するか)
- JaSynonymTokenizer
- NGramSynonymTokenizer
- 最終まとめ
SynonymGraphFilterとSynonymFilter
Solrでは従来から類義語フィルタとしてSynonymFilterが利用されていました。SynonymFilterは類義語が複数の語(トークン)からなる複合語の場合、トークンのオフセットを元に実施されるハイライトの位置がずれてしまうという問題がありました。
このようなハイライトのずれは、TokenizerとSynonymFilterとの間に適切なTokenFilterを挟むことで軽減することが可能ではありましたが、原因がSynonymFilterが類義語展開を行う際に算出する類義語のトークンのオフセット値の誤りであるため、問題の根本的な解決はできない状態にありました。
これに対して先述の通り、Solr 6.4.0では類義語検索時にハイライトのずれが生じていた問題に対して、SynonymGraphFilterという類義語フィルタを追加することで問題の解決を試みています。 (参考ページ)
簡単にSynonymFilterとSynonymGraphFilterについてご説明します。 双方とも引数の類義語辞書を読み取り、インデクシングされるドキュメントや発行されたクエリの内容に対して、類義語の置き換えや展開を行うことが本質的な機能です。 以下で以降の項で利用されている類義語の展開(シノニム展開)の機能についての比較を行います。
機能比較のため、本稿で利用する実験データの一部を例示します。
- 首相でございます
- 首相,総理,総理大臣,内閣総理大臣
SynonymFilterにおいて、上記ドキュメントをシノニム展開すると、以下のようになります。(トークンの後ろの[1:0,2]などは、ポジションが1,開始オフセットが0,終了オフセットが2であることを示しています。)
#content:首相でございます |首相[1:0,2]|で [2:2,3]|ござい[3:3,6]|ます |内閣[1:0,2]|総理[2:2,3]|大臣 [3:3,6]| |総理[1:0,2]|大臣[2:3,3]| |総理[1:0,2]|
一方、SynonymGraphFilter + FlattenGraphFilterにおいて、上記ドキュメントをシノニム展開すると、以下のようになります。
#content:首相でございます |首相[1:0,2]| |で[4:2,3]|ござい|ます |内閣[1:0,2]|総理[2:0,2]|大臣[3:0,2]| |総理[1:0,2]|大臣[2:0,2]| |総理[1:0,2]|
この時、SynonymGraphFilterでシノニム展開された後のドキュメントは、ポジションだけに着目すると以下のような図で表現することができます。
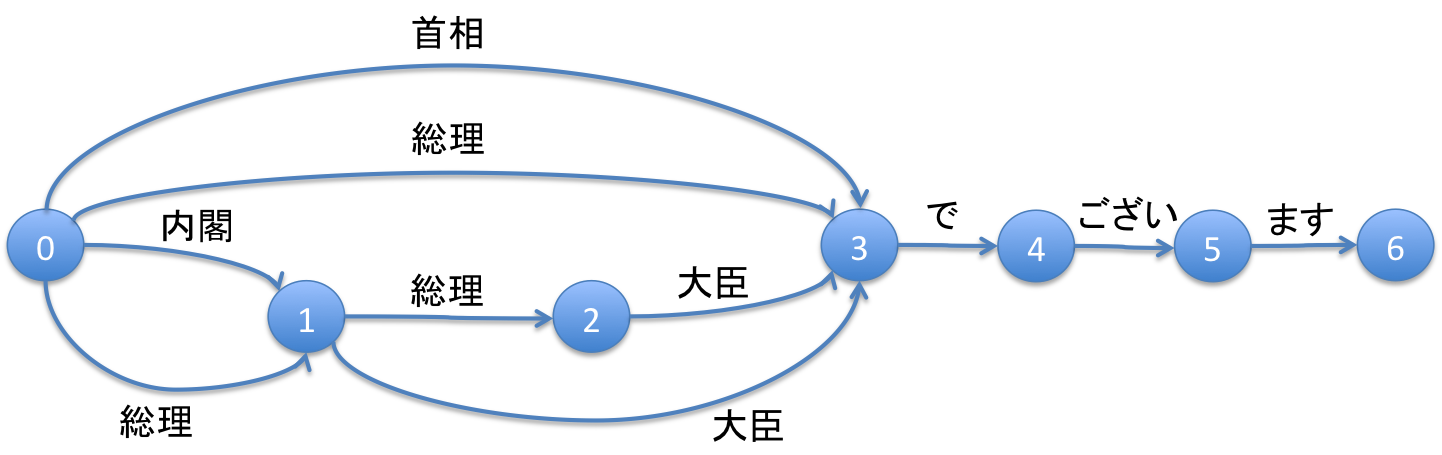
ここで、丸の中の数字は、丸から生えた矢印に対応するトークンのポジションの値から1を引いたものになっています。このように同じ意味の文章を上記のような一枚の図で表現したものをグラフ(Graph)と読んでいます。
この記事ではSynonymFilter及びSynonymGraphFilterの性能を類義語検索、類義語のハイライトに絞り、過去の弊社の記事の内容をなぞる形で比較していきます。
検証環境:managed-schemaの設定とサンプルデータ
- Solr 6.4.1
- managed-schemaに検証用フィールドタイプを設定
- autoGeneratePhraseQueries=trueにして自動フレーズクエリ生成して検索するようにしています。
- JapaneseTokenizerはnormalモードにしています。searchモードでは複合語の細かい単語分割と同時に複合語のオリジナルトークンをシノニムとして自動生成する機能を持っているので、SynonymFilterと併用ができません。
- SynonymFilter、SynonymGraphFilterはシノニム展開(expand=true)させる設定にしています。
- SynonymFilterはクエリ側でシノニム展開すると、MultiPhraseQuery(複雑なクエリ検索式)が生成されて、本来ヒットすべきものが最悪ヒットできないという問題が知られているため、今回の検証ではクエリ側でSynonymFilterは利用しません。
- FlattenGraphFilterは、インデクシング時のみSynonymGraphFilterの直後に配置することが強く推奨されています。FlattenGraphFilterを利用することにより、SynonymGraphFilterでシノニム展開されたのみでは検索にヒットしない項目がヒットするようになります。
- managed-schemaにフィールドとコピーフィールドを設定
- FastVectorHighlighter(略称:FVH)を使用するために、3つのterm*属性をtrueとして追加設定しています。ハイライトでは、Ngramの単語分割でもハイライトができ、検索リクエストのqパラメータで定義した単語についてフレーズまとまり単位でハイライトができ、しかも高速にハイライトできるFastVectorHighlighterを採用します。デフォルトSolrハイライタは、FVHのこれらの特徴を持っていないので使用しません。
- ユーザー辞書
- userdict_ja.txtを登録していますが、空ファイルです。
- 類義語辞書
- synonyms_ja.txtを用意して次の類義語を登録します。
- 1行で複数の単語の類義語を定義できるカンマ区切り形式を採用します。片方向形式は採用しません。理由は、クエリ時にのみシノニム展開をする場合、片方向形式ではヒットしないことがあるためです。
- インデクシングデータ
- SolrのbinディレクトリにあるpostでSolrにポストします。
- idとcontentフィールドだけ用意して、あとはcopyFieldを使って、あらかじめ準備された各フィールドタイプの転置索引を作るようにしています。
- 検証のための検索リクエスト
- ブラウザのURL窓に直接打ってリクエストします。
- solrとselectの間はsolrのコア/コレクション名です。ここでは “SynonymGraphFilter” という名前のコアを準備して検証しています。
- qパラメータの検索キーワードは、「首相」、「総理」、「内閣総理大臣」、「総理大臣」、「内閣」、「大臣」などの単語を入れて検索させます。
- df(デフォルトサーチフィールド)で各フィールドタイプの転置索引を検索するようにフィールド指定します。dfフィールドがそのままハイライトフィールドになるので、hl.flは指定しません。
- FVHを発動させ、検索リクエストを投げると、返却されるXMLのhighlightingセクションに強調の<b>タグを付けられたcontentフィールドが返却されます。
各種フィールドタイプ
| text_ja_i_sf | (インデクシング時) JapaneseTokenizer + SynonymFilterを使用 |
| text_ja_i_sgf | (インデクシング時) JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilterを使用 |
| text_ja_q_sgf | (クエリ時) JapaneseTokenizer + SynonymGraphFilterを使用 |
| text_ja_iq_sgf | (インデクシング、クエリ時) JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter(インデクシング時のみ)を使用 |
| text_ja_i_sgf_nofgf | 【参考】(インデクシング時) JapaneseTokenizer + SynonymGraphFilterを使用 |
<fieldType name="text_ja_i_sf" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
<filter class="solr.SynonymFilterFactory"
tokenizerFactory.mode="normal"
expand="true"
ignoreCase="true"
synonyms="synonyms_ja.txt"
tokenizerFactory="solr.JapaneseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
</analyzer>
</fieldType>
<fieldType name="text_ja_i_sgf" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
<filter class="solr.SynonymGraphFilterFactory"
tokenizerFactory.mode="normal"
expand="true"
ignoreCase="true"
synonyms="synonyms_ja.txt"
tokenizerFactory="solr.JapaneseTokenizerFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
</analyzer>
</fieldType>
<fieldType name="text_ja_q_sgf" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
<filter class="solr.SynonymGraphFilterFactory"
tokenizerFactory.mode="normal"
expand="true"
ignoreCase="true"
synonyms="synonyms_ja.txt"
tokenizerFactory="solr.JapaneseTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ja_iq_sgf" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
<filter class="solr.SynonymGraphFilterFactory"
tokenizerFactory.mode="normal"
expand="true"
ignoreCase="true"
synonyms="synonyms_ja.txt"
tokenizerFactory="solr.JapaneseTokenizerFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="normal"
userDictionary="userdict_ja.txt"/>
<filter class="solr.SynonymGraphFilterFactory"
tokenizerFactory.mode="normal"
expand="true"
ignoreCase="true"
synonyms="synonyms_ja.txt"
tokenizerFactory="solr.JapaneseTokenizerFactory"/>
</analyzer>
</fieldType>
<field name="text_ja_i_sf" type="text_ja_i_sf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true"/>
<field name="text_ja_i_sgf" type="text_ja_i_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true"/>
<field name="text_ja_q_sgf" type="text_ja_q_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true"/>
<field name="text_ja_iq_sgf" type="text_ja_iq_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true"/>
<field name="content" type="string" indexed="true" stored="true" required="false" multiValued="true" />
<copyField source="content" dest="text_ja_i_sf"/>
<copyField source="content" dest="text_ja_i_sgf"/>
<copyField source="content" dest="text_ja_q_sgf"/>
<copyField source="content" dest="text_ja_iq_sgf"/>
首相,総理,総理大臣,内閣総理大臣
<add> <doc> <field name="id">1</field> <field name="content">首相でございます</field> </doc> <doc> <field name="id">2</field> <field name="content">内閣総理大臣でございます</field> </doc> <doc> <field name="id">3</field> <field name="content">総理大臣でございます</field> </doc> <doc> <field name="id">4</field> <field name="content">総理でございます</field> </doc> <doc> <field name="id">5</field> <field name="content">大臣でございます</field> </doc> <doc> <field name="id">6</field> <field name="content">内閣でございます</field> </doc> </add>
http://localhost:8983/solr/SynonymGraphFilter/select?q=検索キーワード &fl=*,score &df=任意のフィールド名 &hl=on &hl.useFastVectorHighlighter=true &hl.tag.pre=<strong>&hl.tag.post=</strong>
(インデクシング時) JapaneseTokenizer + SynonymFilter
- 検索リクエスト
- 結果
- 解説
qパラメータに類義語の単語をセットして、類義語検索のヒットと類義語ハイライトを確認します。
#ケース1 「首相」 http://localhost:8983/solr/SynonymGraphFilter/select?q=首相&fl=id&df=text_ja_i_sf&hl=on&hl.useFastVectorHighlighter=true&hl.tag.pre=<strong>&hl.tag.post=</strong> #ケース2 q=総理 //他の条件は同じ #ケース3 q=内閣総理大臣 //他の条件は同じ #ケース4 q=総理大臣 //他の条件は同じ #ケース5 q=内閣 //他の条件は同じ #ケース6 q=大臣 //他の条件は同じ #ケース7 q=首相で //他の条件は同じ #ケース8 q=内閣総理大臣で //他の条件は同じ
| #ケース1 4件ヒットして、ハイライトができます。 | |
|---|---|
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース2 4件ヒットしますが、id:1,4がハイライトずれを起こします。また、id:3は「大臣」まで、id:2は「内閣」「大臣」もハイライトします。 | |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース3 4件ヒットしますが、id:2以外がハイライトずれを起こします。 | |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース4 4件ヒットしますが、id:3以外がハイライトずれを起こします。 | |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース5 5件ヒットし、id:2,6以外は検索ワードに関係のない単語がハイライトされます。 | |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| id:6 | 内閣でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース6 5件ヒットし、id:5以外は検索ワードに関係のない単語がハイライトされたり、ハイライトずれを起こします。 | |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| id:5 | 大臣でございます |
| #ケース7 2件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| #ケース8 1件ヒットし、ハイライトができます。 | |
| id:1 | 内閣総理大臣でございます |
前述の通りSynonymFilterでは以下のようにトークン(単語テキスト[ポジション:開始オフセット,終了オフセット])を生成します。
#content:首相でございます |首相[1:0,2]|で [2:2,3]|ござい[3:3,6]|ます |内閣[1:0,2]|総理[2:2,3]|大臣 [3:3,6]| |総理[1:0,2]|大臣[2:2,3]| |総理[1:0,2]| #content:内閣総理大臣でございます |首相[1:0,6] |で[4:6,7]|ござい|ます |内閣[1:0,2]|総理[2:2,4]|大臣[3:4,6]| |総理[1:0,2]|大臣[2:2,4]| |総理[1:0,6] |
ケース2の問題は、シノニム展開された「”総理”大臣」、「内閣”総理”大臣」がヒットし、それぞれを重ね合わせてハイライトしようとしてずれています。
ケース3,4の問題は、ヒットした「内閣総理大臣」、「総理大臣」のオフセットがそれぞれ0-6,0-4であり、この範囲をハイライトしようとしてずれています。
ケース5の問題は、シノニム展開された「”内閣”総理大臣」がヒットし、この範囲をハイライトしようとして、シノニム展開されたドキュメント(id:1-4)の0-2の部分をハイライトしています。
ケース6の問題は、シノニム展開された「内閣総理”大臣”」、「総理”大臣”」がヒットし、それぞれを重ね合わせてハイライトしようとしてずれています。
ケース7,8の問題は、「で」のオフセットがクエリの「で」のオフセットと一致するようなドキュメントのみがヒットすることが原因です。
上記から、インデクシング時にSynonymFilterを用いるのは、シングルトークンを類義語定義したときには効果を発揮しますが、複数トークンに分割されるような複合語を類義語として定義し、ハイライトを利用する場合には不向きです。
(インデクシング時) JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter
- 検索リクエスト
- 結果
- 解説
qパラメータに類義語の単語をセットして、類義語検索のヒットと類義語ハイライトを確認します。
#ケース1 「首相」 http://localhost:8983/solr/SynonymGraphFilter/select?q=首相&fl=id&df=text_ja_i_sgf&hl=on&hl.useFastVectorHighlighter=true&hl.tag.pre=<b>&hl.tag.post=</b> #ケース2 q=総理 //他の条件は同じ #ケース3 q=内閣総理大臣 //他の条件は同じ #ケース4 q=総理大臣 //他の条件は同じ #ケース5 q=内閣 //他の条件は同じ #ケース6 q=大臣 //他の条件は同じ #ケース7 q=首相で //他の条件は同じ #ケース8 q=内閣総理大臣で //他の条件は同じ
| #ケース1 4件ヒットして、ハイライトができます。 | |
|---|---|
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース2 4件ヒットして、ハイライトができますが、id:2,3は「総理」でハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース3 4件ヒットして、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース4 4件ヒットして、ハイライトができますが、id:2は「総理大臣」でハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース5 5件ヒットし、id:2,6以外は検索ワードに関係のない単語がハイライトされます。 | |
| id:6 | 内閣でございます |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース6 5件ヒットし、id:3,5以外は検索ワードに関係のない単語がハイライトされたり、ハイライトずれを起こします。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| id:5 | 大臣でございます |
| #ケース7 1件もヒットしません。 | |
| – | |
| #ケース8 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
SynonymGraphFilter + FlattenGraphFilterでは以下のようにトークン(単語テキスト[ポジション:開始オフセット,終了オフセット])を生成します。
#content:首相でございます |首相[1:0,2]| |で[4:2,3]|ござい|ます |内閣[1:0,2]|総理[2:0,2]|大臣[3:0,2]| |総理[1:0,2]|大臣[2:0,2]| |総理[1:0,2]| #content:内閣総理大臣でございます |首相[1:0,6] |で[4:6,7]|ござい|ます |内閣[1:0,2]|総理[2:2,4]|大臣[3:4,6]| |総理[1:0,2]|大臣[2:2,6] | |首相[1:0,6] |
ケース2と4の問題は、上記のようにシノニム展開された際に全てのシノニムの合計オフセットを揃えてしまうためにハイライトの範囲が広がってしまっています。
ケース5の問題は、SynonymFilterのケース5と同様で、シノニム展開されてインデクシングされた「内閣」がヒットし、この範囲をハイライトしようとして、シノニム展開されたドキュメント(id:1-4)の0-2の部分をハイライトしています。
ケース6の問題も、シノニム展開された際の「大臣」の「とオフセットに対応する単語がハイライトされてしまうことが原因です。
ケース7の問題は、クエリの「首相」(1)と「で」(2)のポジションと、インデクシングされたドキュメントの「首相」(1)と「で」(4)のポジションが異なるために検索にヒットしなくなっています。
ケース8は、ケース7と同様の現象が発生しますが、上記の例の通り「内閣」「総理」「大臣」「で」はシノニム展開された後もポジションが連続したトークンと認識されているため、シノニム展開されてこれらが収められている全てのドキュメントがヒットします。
インデクシング時にSynonymGraphFilter + FlattenGraphFilterを用いるのは、類義語展開したときにトークンのオフセットやポジションをずらしてしまうため、フレーズ検索ができなくなってしまう場合があります。
(クエリ時) JapaneseTokenizer + SynonymGraphFilter
- 検索リクエスト
- 結果
- 解説
qパラメータに類義語の単語をセットして、類義語検索のヒットと類義語ハイライトを確認します。
#ケース1 「首相」 http://localhost:8983/solr/SynonymGraphFilter/select?q=首相&fl=id&df=text_ja_q_sgf&hl=on&hl.useFastVectorHighlighter=true&hl.tag.pre=<b>&hl.tag.post=</b> #ケース2 q=総理 //他の条件は同じ #ケース3 q=内閣総理大臣 //他の条件は同じ #ケース4 q=総理大臣 //他の条件は同じ #ケース5 q=内閣 //他の条件は同じ #ケース6 q=大臣 //他の条件は同じ #ケース7 q=首相で //他の条件は同じ #ケース8 q=内閣総理大臣で //他の条件は同じ
| #ケース1 4件ヒットして、ハイライトができます。 | |
|---|---|
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| #ケース2 4件ヒットして、ハイライトができますが、id:2,3は「総理」の部分だけでハイライトされません。 | |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| #ケース3 4件ヒットして、ハイライトができます。 | |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| #ケース4 4件ヒットして、ハイライトができますが、id:2は「総理大臣」の部分だけでハイライトされません。 | |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:1 | 首相でございます |
| id:4 | 総理でございます |
| #ケース5 2件ヒットして、ハイライトができます。 | |
| id:6 | 内閣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース6 3件ヒットして、ハイライトができます。 | |
| id:5 | 大臣でございます |
| id:3 | 総理大臣でございます |
| id:2 | 内閣総理大臣でございます |
| #ケース7 4件ヒットし、ハイライトができます。 | |
| id:2 | 内閣総理大臣でございます |
| id:1 | 首相でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース8 4件ヒットし、ハイライトができます。 | |
| id:2 | 内閣総理大臣でございます |
| id:1 | 首相でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
ケース2,3の問題は、「総理」、「総理大臣」、「内閣総理大臣」が類義語として与えられているため、もっとも多くの連続するトークンがマッチするシノニムに対してハイライトが行われたためと考えられます。
SynonymGraphFilterをクエリ時に利用すると、シノニムに登録されている類義語のハイライトの範囲が広がる可能性がある以外は、ヒット件数、ハイライトの位置ともに良い結果が得られました。
(インデクシング時、クエリ時) JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter
- 検索リクエスト
- 結果
- 解説
qパラメータに類義語の単語をセットして、類義語検索のヒットと類義語ハイライトを確認します。
#ケース1 「首相」 http://localhost:8983/solr/SynonymGraphFilter/select?q=首相&fl=id&df=text_ja_iq_sgf&hl=on&hl.useFastVectorHighlighter=true&hl.tag.pre=<b>&hl.tag.post=</b> #ケース2 q=総理 //他の条件は同じ #ケース3 q=内閣総理大臣 //他の条件は同じ #ケース4 q=総理大臣 //他の条件は同じ #ケース5 q=内閣 //他の条件は同じ #ケース6 q=大臣 //他の条件は同じ #ケース7 q=首相で //他の条件は同じ #ケース8 q=内閣総理大臣で //他の条件は同じ
| #ケース1 4件ヒットして、ハイライトができます。 | |
|---|---|
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース2 4件ヒットして、ハイライトができますが、id:2,3は「総理」の部分だけでハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース3 4件ヒットして、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース4 4件ヒットして、ハイライトができますが、id:2は「総理大臣」の部分だけでハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース5 5件ヒットし、id:2,6以外は検索ワードに関係のない単語がハイライトされます。 | |
| id:6 | 内閣でございます |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース6 5件ヒットし、id:3,5以外は検索ワードに関係のない単語がハイライトされたり、ハイライトずれを起こします。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| id:5 | 大臣でございます |
| #ケース7 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース8 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
インデクシング時、クエリ時のみにSynonymGraphFilterを利用した場合が混合されたような結果になっています。
ケース5と6は、インデクシングの際にSynonymGraphFilterを利用した場合と同様に、シノニム展開されてインデックスに納められた「内閣」や「大臣」というトークンにヒットしてしまったために発生しています。
一方で、ケース7のようにインデクシング時のみでSynonymGraphFilterを使った場合に比べ、フレーズクエリを正常に処理できるようになっています。
このことから、インデクシング・クエリ双方でSynonymGraphFilterを使う場合、インデクシングのみでSynonymGraphFilterを利用する場合に比べてフレーズクエリの処理ができるようになりますが、シノニム展開されたトークンが検索に引っかかってしまうという問題が残ります。
中間まとめ(SynonymFilterとSynonymGraphFilterの比較、SynonymGraphFilterをどのタイミングで利用するか)
ここまでの4つのケースで確認できたことを4点まとめます。
- インデクシング時にSynonymFilterを利用すると、ハイライトずれが発生する。
- インデクシング時にSynonymFilter, SynonymGraphFilterを利用すると、ドキュメントに含まれていない単語でもシノニム展開されている語であれば検索にヒットしてしまう。
- インデクシング時にSynonymFilter, SynonymGraphFilterを利用すると、フレーズ検索が正常に動作しないことがある。
- クエリ時のみにSynonymGraphFilterを利用すると、類義語検索、類義語ハイライト、類義語を含むフレーズクエリが概ね正常に動作する。
一旦今の時点での評価をしますと、以下の様な表が書けます。
| 使用パターン | 類義語検索 | 類義語ハイライト |
|---|---|---|
| (インデクシング時)JapaneseTokenizer + SynonymFilter | △ | ☓ |
| (インデクシング時)JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter | △ | ☓ |
| (クエリ時)JapaneseTokenizer + SynonymGraphFilter | ○ | ○ ※ |
| (インデクシング、クエリ時)JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter | △ | ○ ※ |
※ 類義語のハイライトにおいて、「総理、総理大臣、内閣総理大臣」のようにシノニムを登録した場合、「総理」で検索すると「総理大臣」、「内閣総理大臣」の範囲でハイライトされます。
上記から類義語検索、類義語ハイライトを両立させるためには、クエリ時のみSynonymGraphFilterを使うのがもっとも良さそうに思えます。
ここで、少し本筋からは逸れますが、クエリ時にSynonymGraphFilterを利用する場合、Solr内部のリクエストがどうなっているかを確認してみましょう。
- 検索リクエスト
クエリ時のSynonymGraphFilter実行のケース1のURLの最後にdebugQuery=trueをセットして実行。
http://localhost:8983/solr/SynonymGraphFilter/select?q=首相&fl=id&df=text_ja_iq_sgf&hl=on&hl.useFastVectorHighlighter=true&hl.tag.pre=<b>&hl.tag.post=</b>&debugQuery=true
得られた結果のparsedqueryの値に注目すると、GraphとGraphQueryという文字列が確認できます。
<str name="parsedquery"> GraphQuery(Graph(text_ja_iq_sgf:"総理 大臣", text_ja_iq_sgf:総理, text_ja_iq_sgf:"内閣 総理 大臣", text_ja_iq_sgf:首相, hasBoolean=false, hasPhrase=true)) </str>
LuceneのマニュアルのGraphQueryのページを読むと、”A query that wraps multiple sub-queries generated from a graph token stream.”とあり、GraphQueryの中に入っているものはSynonymGraphFilterでのシノニム展開により生成されたサブクエリであるとわかります。
JaSynonymTokenizer
ここからはロンウイットが提供しているサブスクリプション(以下、RCSSと記します。)独自の機能を利用して類義語検索と類義語ハイライトの動作を確認し、SynonymGraphFilterをクエリ時に利用した場合の振る舞いと比較します。
JaSynonymTokenizerは、IPAdic, JUMAN, UniDicの3つのOSS辞書をサポートしており、これらの辞書から自動で類義語を探しての類義語展開&ユーザー独自の類義語辞書での類義語展開に対応しています。
また、形態素解析器レベル(上記の検証で言えばJapaneseTokenizer)でシノニム出力を行いますので、SynonymFilter利用時に発生しやすいハイライトずれがおきにくいという特徴があります。
- 準備
- RCSSのコアのmanaged-schemaに検証用フィールドタイプを設定
- useSynonyms属性をtrueにして類義語サポートをonにし、synonyms属性でユーザ類義語辞書を指定します。
- dir属性は前述でコンパイルした辞書の場所を指定します(プレースホルダを使ってSolr起動時に指定します)。
- managed-schemaにフィールドとコピーフィールドを設定
- RCSSの起動
- RCSS上にコアを作り、データをインデクシングします。
# 弊社のサブスクリプションのダウンロードページからRCSS 3.0.0(Solr 6.4.2を内包)ファイルを取得して解凍します。
$ tar xvzf RCSS-basic-3.0.0.tar.gz
# RCSSの中に検証用のコア設定をコピー & RCSSのJaSynonymTokenizerを含むライブラリを検証用のコアディレクトリにコピー
$ cd RCSS-basic-3.0.0
$ mkdir ${RCSS}/solr-home/SynonymGraphFilter
$ cp -pR ${coreDirectory}/SynonymGraphFilter/conf ${RCSS}/solr-home/SynonymGraphFilter/.
$ cp -pR ${RCSS}/solr-home/basic/lib ${RCSS}/solr-home/SynonymGraphFilter/.
## (${RCSS}はダウンロードしてきたRCSSを展開してできたディレクトリです。)
## (${coreDirectory}はSolrのコアが格納されているディレクトリです。)
# Synonym辞書の展開
$ vi morpho-ipadic.properties
##以下の通り編集
morpho.syn.file=solr-home/SynonymGraphFilter/conf/synonyms_ja.txt
$ ./makedic.sh
## 引数としてipadic|juman|unidicのいずれかを指定することで、類義語辞書の元になるOSS辞書を指定できます。デフォルトはIPAdicです。
$ ls -l dic/out/ipadic/synonyms.dic
<fieldType name="text_ja_iq_jst" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="com.rondhuit.solr.analysis.morpho.JaSynonymTokenizerFactory"
dir="${RCSS}/dic/out/ipadic"
type="ipadic"
useSynonyms="true"
synonyms="synonyms_ja.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.rondhuit.solr.analysis.morpho.JaSynonymTokenizerFactory"
dir="${RCSS}/dic/out/ipadic"
type="ipadic"
useSynonyms="false"/>
</analyzer>
</fieldType>
<field name="text_ja_iq_jst" type="text_ja_iq_jst" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true"/> <copyField source="content" dest="text_ja_iq_jst"/>
$ cd ${RCSS}
$ LUSOLR/solr/bin/solr start
$ LUSOLR/solr/bin/solr create_core -c SynonymGraphFilter $ LUSOLR/solr/bin/post -c SynonymGraphFilter ~/testData.xml
そしてSolrで、検索します。
- 検索リクエストの実行
- 結果
- 解説
- 対応方法1:形態素解析フィールドとNgramフィールドの横断検索を行う。
- 対応方法2:類義語辞書に複合語を登録するときに、最小単位の単語も類義語として登録する。
- 準備
- RCSSのコアのmanaged-schemaに検証用フィールドタイプを設定
- n属性は、Gramの数値です(minGramSize=maxGramSize)。
- expand属性をインデクシング時にtrueにして、synonyms属性でユーザ類義語辞書を指定します。
- managed-schemaにフィールドとコピーフィールドを設定
- RCSSの再起動とデータの再登録
- 検索リクエストの実行
- 結果
- 解説
- クエリ時のみSynonymGraphFilterを利用する。
- JaSynonymTokenizer/NGramSynonymTokenizerを使って、類義語検索と類義語ハイライトを最適化する。
qパラメータに類義語の単語をセットして、類義語検索のヒットと類義語ハイライトを確認します。
#ケース1 「首相」 http://localhost:8983/solr/SynonymGraphFilter/select?q=首相&fl=id&df=text_ja_iq_jst&hl=on&hl.useFastVectorHighlighter=true&hl.tag.pre=<b>&hl.tag.post=</b> #ケース2 q=総理 //他の条件は同じ #ケース3 q=内閣総理大臣 //他の条件は同じ #ケース4 q=総理大臣 //他の条件は同じ #ケース5 q=内閣 //他の条件は同じ #ケース6 q=大臣 //他の条件は同じ #ケース7 q=首相で //他の条件は同じ #ケース8 q=内閣総理大臣で //他の条件は同じ
| #ケース1 4件ヒットして、ハイライトができます。 | |
|---|---|
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース2 4件ヒットして、ハイライトができますが、id:2,3は「総理」の部分だけでハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース3 4件ヒットして、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース4 4件ヒットして、ハイライトができますが、id:2は「総理大臣」の部分だけでハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース5 1件ヒットし、ハイライトされます。 | |
| id:6 | 内閣でございます |
| #ケース6 1件ヒットし、ハイライトされます。 | |
| id:5 | 大臣でございます |
| #ケース7 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース8 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
JaSynonymTokenizerでは以下のようにトークン(単語テキスト[ポジション:開始オフセット,終了オフセット])を生成します。
#content:首相でございます |首相[1:0,2] |で[2:2,3]|ござい|ます |内閣総理大臣[1:0,2]| |総理大臣[1:0,2] | |総理[1:0,2] | #content:内閣総理大臣でございます |首相[1:0,6] |で[2:6,7]|ござい|ます |内閣総理大臣[1:0,6]| |総理大臣[1:0,6] | |首相[1:0,6] |
ケース5と6は、インデクシング時に「内閣総理大臣」、「総理大臣」で一つのトークンとして扱われるために、「内閣」や「大臣」では検索にヒットしないことが原因です。
JaSynonymTokenizerでは、複数トークンからなるシノニムを分解せず一単語として展開するために、ケース5,6のような検索漏れが出てしまいます。これを防止するには以下の方法が有力です。
本稿の前に弊社が公開した記事の中にある方法です。この方法は未知語の検索漏れを防ぐ際にも有効です。
マイナス点は、autoGeneratePhraseQueryがfalseにするため、例えば「首相で」と検索した際に「で」が単体で検索ワードになるために、ゴミ単語の”ハイライト”が起きてしまう点です。
synonyms_ja.txtに「内閣」や「大臣」を追加します。想定しうる類義語候補を全部登録する対応となります。
首相,総理,総理大臣,内閣総理大臣,内閣,大臣
類義語辞書を修正したら辞書コンパイルをやりなおしして、Solrの再起動および再インデクシングが必要です。
マイナス点は、想定しうる全ての類義語とそれを構成する単語を書き出す必要があること、また、この方法では内閣=大臣=首相という誤った類義語の扱いをされてしまうため、検索実行時に不適切なドキュメントが上位に表示されないようにスコア計算を工夫する必要があります。
| #ケース1 4件ヒットして、ハイライトができます。 | |
|---|---|
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース2 4件ヒットして、ハイライトができますが、id:2,3は「総理」の部分だけでハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース3 4件ヒットして、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース4 4件ヒットして、ハイライトができますが、id:2は「総理大臣」の部分だけでハイライトされません。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース5 1件ヒットし、ハイライトされます。 | |
| id:6 | 内閣でございます |
| #ケース6 1件ヒットし、ハイライトされます。 | |
| id:5 | 大臣でございます |
| #ケース7 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
| #ケース8 4件ヒットし、ハイライトができます。 | |
| id:1 | 首相でございます |
| id:2 | 内閣総理大臣でございます |
| id:3 | 総理大臣でございます |
| id:4 | 総理でございます |
NGramSynonymTokenizerでは以下のようにトークン(単語テキスト[ポジション:開始オフセット,終了オフセット])を生成します。
#content:首相でございます |首相[1:0,2] |で[2:2,3]|でご|ござ|ざい|いま|ます |内閣総理大臣[1:0,2]| |総理大臣[1:0,2] | |総理[1:0,2] | #content:内閣総理大臣でございます |首相[1:0,6] |で[2:6,7]|でご|ござ|ざい|いま|ます |内閣総理大臣[1:0,6]| |総理大臣[1:0,6] | |首相[1:0,6] |
ケース5と6は、JaSynonymFilterと同様にインデクシング時に「内閣総理大臣」、「総理大臣」で一つのトークンとして扱われるために、「内閣」や「大臣」では検索にヒットしないことが原因です。
NGramSynonymTokenizerでは、複数トークンからなるシノニムを分解せず一単語として展開するために、ケース5,6のような検索漏れが出てしまいます。これを防止するには、JaSynonymTokenizerの項で記載した対応を実施することが有力です。
最終まとめ
類義語検索と類義語ハイライトを実現するためには、
全体的な評価をしますと、以下の様な表が書けます。
| 使用パターン | 類義語検索 | 類義語ハイライト |
|---|---|---|
| (インデクシング時)JapaneseTokenizer + SynonymFilter | △ | ☓ |
| (インデクシング時)JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter | △ | ○ |
| (クエリ時)JapaneseTokenizer + SynonymGraphFilter | ○ | ○ ※2 |
| (インデクシング、クエリ時)JapaneseTokenizer + SynonymGraphFilter + FlattenGraphFilter | △ | ○ |
| JaSynonymTokenizer | ○ ※1 | ○ ※2 |
| NGramSynonymTokenizer | ○ ※1 | ○ ※2 |
※1 類義語が複合語の場合の最小単位の単語検索はできませんが、最小単位の単語も類義語辞書に含めれば類義語検索のヒット漏れが防げるので○としています。
※2 類義語のハイライトにおいて、「総理、総理大臣、内閣総理大臣」のようにシノニムを登録した場合、「総理」で検索すると「総理大臣」、「内閣総理大臣」の範囲でハイライトされます。
注意点として、SynonymGraphFilterをクエリ時利用する場合、クエリが発行されるたびにシノニム展開をするため、検索レスポンスに影響を与える可能性があるということです。検索の再現率・適合率と性能のバランスを考慮して適切な類義語処理の構成をご検討ください。
本記事がお客様の業務に少しでもお役に立てば幸いです。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!