INFORMATION
テクノロジ
ApacheCon North America 2018に参加してきました(初日、2日目)
溝口 泰史 著
2018/9/24 – 27にカナダ・モントリオールで開かれたApacheCon North America 2018(以下、ACNA2018)に参加してきましたのでレポートいたします。

モントリオールでカンファレンスが開かれるにあたり、まずモントリオールという街を調べてみました。カナダでITと言えば、海外にはいつもBlackBerry Passportを持って行っているので、ウォータールー(ウォータールー大学、BlackBerry社、etc…)を思いますが、モントリオールも非常にITが盛んな土地ということでした。
例えば、空港に以下の画像のような市街に向かう交通手段の看板が置いてあり、ITが盛んそうな印象を受けました。ちなみに私はバスを使いました。

なお、モントリオールはケベック州に属するためフランス語圏ですが、英語も通じる土地で、地名(フランス語表記&フランス語読み)と料理名(空港のサブウェイのメニューはフランス語で書かれていました。。。)以外ではフランス語と併記されている英語を読むことでなんとか滞在することができました。
カンファレンスの会場は、Montreal Marriott Chateau Champlainというホテルで、ホテルの近くには歴史がありそうな英国教会の建物があり、市の中心地からは少し離れた落ち着いた場所でした。

ApacheConというカンファレンスについて説明すると、その名の通りApache Software Foundation(以下、ASF)自体の運営や、各プロジェクトに関するカンファレンスです。ASFのプロジェクトとは、有名なApache HTTP ServerやTomcatを始め、弊社で取り扱っているLucene/Solr、OpenNLP、Mahout、ビッグデータとは切っても切れないHadoop、Sparkなど、様々なものがあります。ASF自体についての詳しい話は、弊社代表の関口の記事に詳しいので、気になる方はそちらもご覧ください。
ACNA2018のプログラムの構成を見て面白いと思ったのは、ACNA2018にある程度の規模のASFのプロジェクトの個別のカンファレンスが包含されていたことです。 例えば初日から2日目まではTomcatとCloudStackのカンファレンスがACNA2018に包含される形で開催されていました。

2018/9/24(初日)
初日は主にCloudStack、Tomcatのセッションと、Sparkのワークショップが中心でした。私は午前午後ともにSparkのワークショップに参加しました。
Apache Spark and Scala – Morning Workshop

IBMの社員が担当するSparkのワークショップで、GraphXやSpark Streaming、SystemMLなどの機能に興味があったので参加しました。しかしながら、実際にはSparkの具体的なコンポーネントに触れるというよりは、Scalaの使い方とSparkのRDD/DataFrameの違い・使い分けまでの説明までが非常に長く、最後は駆け足で各コンポーネントの概要を説明する程度で終わってしまいました。
セッションの内容は、私個人としてはあまり深くはないと感じたものの、昨年参加したScale By The Bayのワークショップでも感じましたが、習熟度の違う大人数が参加するワークショップの進行の難しさを感じました。
ただ、資料にはSpark Streamingのサンプルコードなどがあり、Sparkの様々な機能の取っ掛かりとしてはとても良いセッションだったと思います。資料は以下のURLで公開(?)されているようなので、ScalaとSparkに興味のある人は試してみると良いかもしれません。
Learn How to Build End-to-End Apache Spark with Data at Rest, Streaming and Machine Learning
Apache Sparkを利用してストリーミングデータを処理する基盤のハンズオンで学べるというワークショップでしたが、環境の利用にクレジットカードの登録が必要ということでセキュリティの問題からアクティベートできず、1つの環境を参加者全員が共有し、ひたすら処理について説明を受けるというセッションでした。
以下にセッションで利用した環境を構築するための資料が公開されています。
https://github.com/azeltov/adb_workshop
想定しているサービスの全体像は、ECサイトの注文履歴や選択された商品の情報をApache Kafkaを介してストリーミングデータとしてSparkに入れて処理を行い、そのデータをデータストアに溜めて再利用したり、リアルタイムでのKPI分析に利用するというものでした。

環境を共用しているため、あまり自由度はありませんでしたが、ハンズオンで利用したDatabricks Workspaceは、パラメータは若干多いものの簡単にSparkの環境を構築でき、とても使いやすかったです。
Sparkの環境構築の時間を短くし、様々な解析を行いやすくするというのは、別のセッションでも言及されていましたが、今は世界の最先端の企業ではデータ解析自体の時間を短縮するだけでなく、データ解析の準備にかかる時間を短縮するということが肝要であると感じました。
2018/9/25(二日目)
State Of The Feather
ASFのディレクターであるBertrand Delacretazさんの講演でASF全体でこの1年にあったことを振り返るというセッションだったのですが、一年間の総括という側面よりも、ASFのこれまでのあゆみを掘り下げ、その強み(Community over Codeという理念、ベンダー中立性、シンプルな運営(コミュニティによる投票で方針が決定される)、法的保護)を見つめ直すというような内容でした。
個人的には、見にくいですが下の画像スライドの一番大きなグラフの通り、ASFにコントリビュートされたコードの行数の増え方が、(プロジェクトが増えているのもあるのでしょうが)近年になって加速していたのがとても興味深かったです。

また、別の日の講演でも話されていましたが、来年はASFの20周年に当たるとのことで、移り変わりの激しいIT業界において20年間に渡り上述の強みを維持し、OSSが勢いづいてきた今でも特定の企業に依存しないというプロジェクトの運営の基本部分を変えずに維持していることは、各コントリビューターが理念を理解していることの証左であると感じることができました。
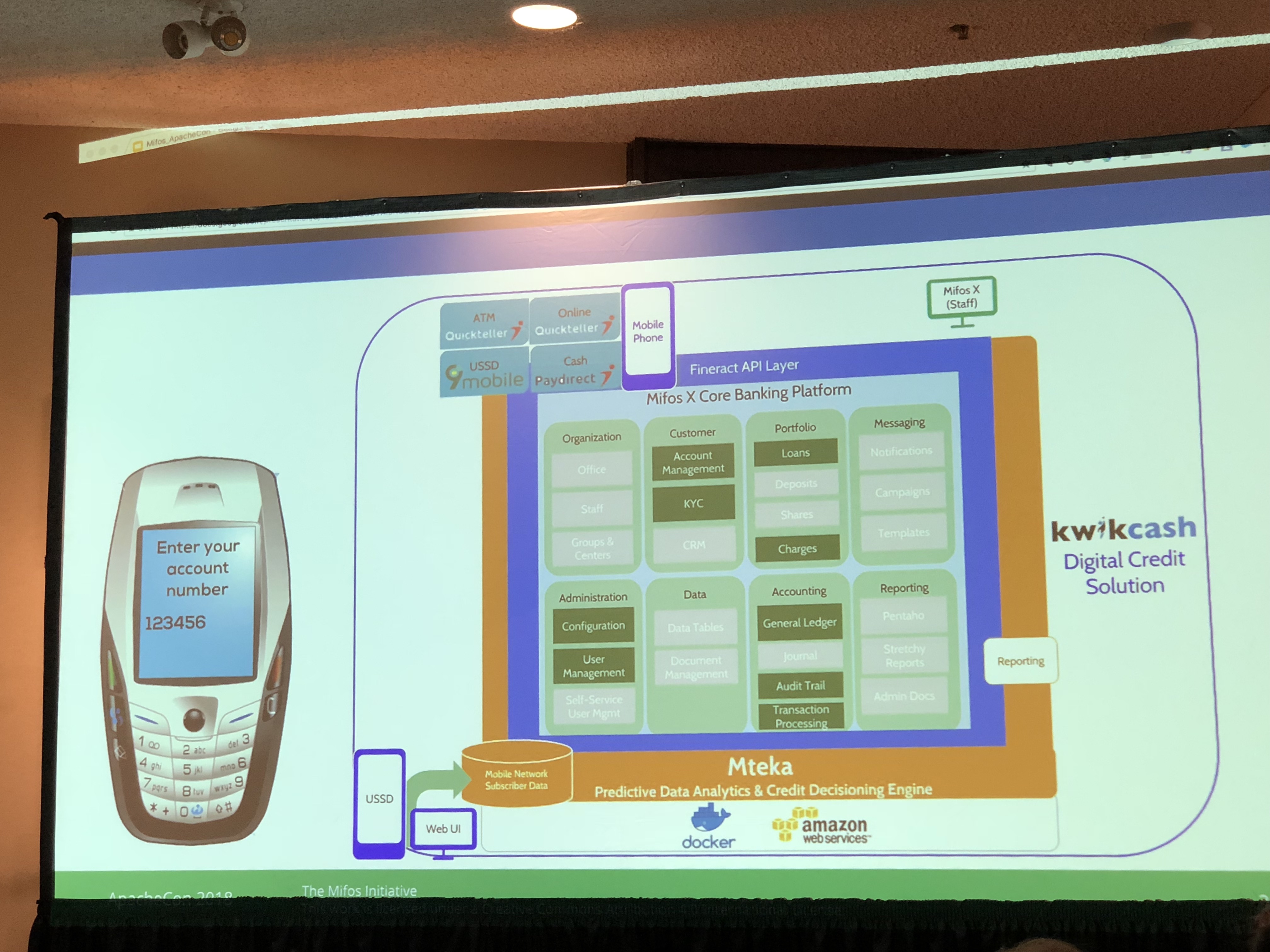
Banking on Open Source
Open Banking: Fueling Innovation on an Open Source Core Banking Platform
Apache Fineractはマイクロファイナンスの父であるムハンマド・ユヌスさんで知られるグラミン財団(Grameen Foundation)の成果物をベースにしており、金融系の機能をパッケージングしたフレームワークとのことです。
前者は基調講演で、アフリカなどの途上国において銀行口座を持たず、savings group(貯蓄グループ、日本で言うところの無尽のようなものかなと思いました。)や、joint liability groupと言うものを作っている人をソフトウェアの力で支援すると言う話でした。
後者はApache Fineractの成り立ちに触れるとともに、様々な国々への導入事例(メキシコ、インド、ナイジェリア、ドイツ)が中心の話でした。
Apacheプロジェクトの成果物は、今や一般の企業でも利用されるようになっていますが、それとは求められるサービスレベルの異なる金融系の業務システムまで手がけていることに驚きました。(完全にFineractで構築したり置き換えたりというものではなく、事例によってはUI/UXとビジネスロジックの一部分だけ利用という形であったりもしましたが。。。)
とはいえ、Apacheのプロジェクトの成果物が、部分的にではあっても非常に高い信頼性を求められる金融系サービスに利用されるものになっているということは、ASFのコミュニティ運営のあり方で十分な品質を担保できるという裏付けだと感じることができる、良いセッションでした。
Community culture, code quality and testability.

CloudstackのPMCメンバーの、テストに関する話でした。
ソフトウェアの開発においてテストは非常に大切なのですが、開発者やコミュニティは概ね保守的で、パッチを書くときでもコードにかかる変更を最小限に抑えようとする傾向があるということ(例:単純にif文を追加する、変更を局所的なものに抑えておく)です。そして、そういったパッチの積み重ねによってソースコードが読みづらく、テストが書きづらくなっていくという傾向があります。
セッション内では単体テスト・結合テストの2種類を取り上げ、テストの実行にかかる時間と実装にかかる時間を以下のように比較していました。
(その上個々のテストケースを保守しなければならない。。。)
上記のような背景はあるものの、結論としては追加でテストを書く必要性を説くのは大変だが、テストを書くことはソフトウェアの品質を向上させ、よりそのソフトウェアを(新しい利用者にとって)魅力的なものに変えていくことができるため、多くのテストを書いて積極的にリファクタリングをすることで、ソースコードの可読性を確保するようにした方が良いというものでした。
テストを追加するモチベーションとして利用者にとって魅力的なものにするためにソースコードを読みやすくするという点は、多くの開発者を集めてコミュニティを育てていく必要のあるOSSならではと感じる、面白いセッションであったと思います。
How Microsoft is learning to embrace the Apache Way with real time streaming
タイトルに惹かれて出席しました。他の参加者も気になったのか、私が出席したセッションでは珍しく、立ち見が出るほどの人が来ていました。
導入では、メッセージングサービスの歴史(プロトコルの乱立 -> IBMMQ -> JMS -> AMQP)に触れ、何故Apacheの成果物を利用しようとしたかという点(納期、品質、オープンな標準)を挙げていました。
そして、採用後の話として、Qpid/nifi/AVRO/kafkaとのコミュニティとの関わりの事例を挙げて振り返り、

セッションの早いうちでも触れられていたのですが、かつてのMicrosoftはCEOの有名な「Linuxはガン」発言などがあってOSSを敵視していたのですが、最近ではOSSに多くの貢献をする会社に変わっています。
上述の結びのページにもありますが、コミュニティがどの企業の色にも染まらないと言う方針がしっかりとしているOSSは、今後も多くのサービスで採用され、開発が継続するということを強く感じられるセッションでした。
長くなってきたので、3、4日目は次の記事に分割します。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!