INFORMATION
サービス
KandaSearch ではじめる Apache Solr 入門
はじめに
この度、株式会社ロンウイットからKandaSeach1.1がリリースされ、それをいち早く使う機会があったのでその使用レビューを書いてみたいと思う。 KandaSearchの中核はApache Solrであるが使用してみてApche Solrをより簡単に使用できるなといった感想を持った。 その前にApache Solrをまだ使用したことがない人にApache Solrについて簡単に紹介したいと思う。
全文検索サーバーApache Solr
Apache Solr(以下Solr)は全文検索を行うためのサーバーソフトである。全文検索とはデータ登録時にあらかじめ付けておいたキーワードやハッシュタグに頼ることなく、登録した文書中に出てくる単語で検索できる機能である。
例えば、リレーショナルデータベースに何らかのデータ(文書、ドキュメント)を登録した場合、通常その文書の検索にはその文書と紐づいたキーワードやカテゴリなどを検索して目的の文書にたどり着くことになる。 それに対し全文検索を使用したデータベースの場合はその登録文書中の単語で検索することが可能である。RDBでもlike文を使用し検索できるよと思った方がいるかもしれないがスピードが全然違う。like文はデータ全てをなめて検索するのに対し、全文検索ではあらかじめ索引を作っておきその索引から目的の文書にたどり着く。 ある本で、”コンピュータ”という言葉が出ているページを探すのに、内容すべて読んで”コンピュータ”という単語が出てきたページに付箋を付けていく場合と、索引を見てそこからページを特定する場合の違いを考えてみて欲しい。これと同様である。
実はコンピュータを使用している人はこの全文検索の検索技術にはすごくお世話になっているはずである。そうGoogleである。 Googleの検索方法はまさにこの全文検索を使用している。試しにGoogleで”コンピュータ”を検索すると約4億2千万のホームページがたちどころにヒットしその時間はわずか0.86秒である。
情報化社会においては、莫大なデータをキーワード付けすることなどなく簡単に登録しかつ簡単に素早く検索する全文検索は絶対的に必要な技術である。例えば会社の文書をあらかじめ全文検索サーバーに登録しておいてテレワークで自宅から検索を行い目的の文書を見つけるなどという事が可能になる。 その他全文検索では同義語の検索や全角半角大文字小文字を区別したりしなかったりの検索などRDBでは行えないような柔軟な検索が可能である。
ではGoogleで良いではないかと思われる向きもいるかもしれない。しかしGoogleは企業内の検索には対応していない。まさか自社内の文書をGoogleに公開するわけにもいかない。そこでSolrの登場である。SolrはApacheプロジェクト内で作成されている全文検索サーバーソフトであり誰もが自由に使用できる。しかしオープンソース・ソフトウェアであるが故か、御多分に洩れずサーバー構築の敷居が高い。
KandaSearchではそんな敷居を低くし誰でもがSolrを簡単に使用できるようにする。いくつかの質問に答えていくだけでサーバー構築ができるので手軽に全文検索を始めてみたいという向きにはピッタリである。SolrCloudの構築もスタンドアロンと同様いくつかの質問に答えていくだけで良い。なお、SolrCloudについては、一番最後のセクションで述べることとし、まずは、KandaSearchを使ったスタンドアロンSolrによるサーバー構築からサンプルデータのインデクシングと検索までを順に説明させていただく。
KandaSearch上で全文検索サーバーを構築する
構築には、アカウント登録、プロジェクト作成、インスタンス作成、コレクション作成と言った手順を踏む。アカウント登録については説明の必要はないだろうが、プロジェクト、インスタンス、コレクションについては多少説明が必要であると思われる。
まずプロジェクトはメンバーとインスタンスをまとめた1つの単位である。メンバーやインスタンスをプロジェクト単位で管理できるので企業ユースで使用するには最適であろう。プロジェクトによりメンバーを分けることができるので、アクセスする人の違いによりプロジェクトは別のものにした方がよいと思われる。なおメンバーの種類としては管理者、(一般)ユーザの二種類がある。メンバーの追加の仕方は後述する。
次にインスタンスだが、この単位でSolrへのアクセス(データ登録やSolr管理画面による検索等)の可否をIPアドレスの指定により分けることができる。同じプロジェクトで本番環境やテスト環境などを区別したい場合などに重宝すると思われる。
そしてコレクションだがこれがRDBで言うテーブルにあたる。例えば商品カタログや購買情報などである。
なお、プロジェクト、インスタンス、コレクションとも複数設定可能である。
アカウント登録
それでは実際にKandaSearchを使用して簡単な検索を行うまでを紹介したいと思う。今回はトライアルという事で「一週間無料でお試し」を使用してみる。 まず、KanadaSearchのURL
にアクセスする。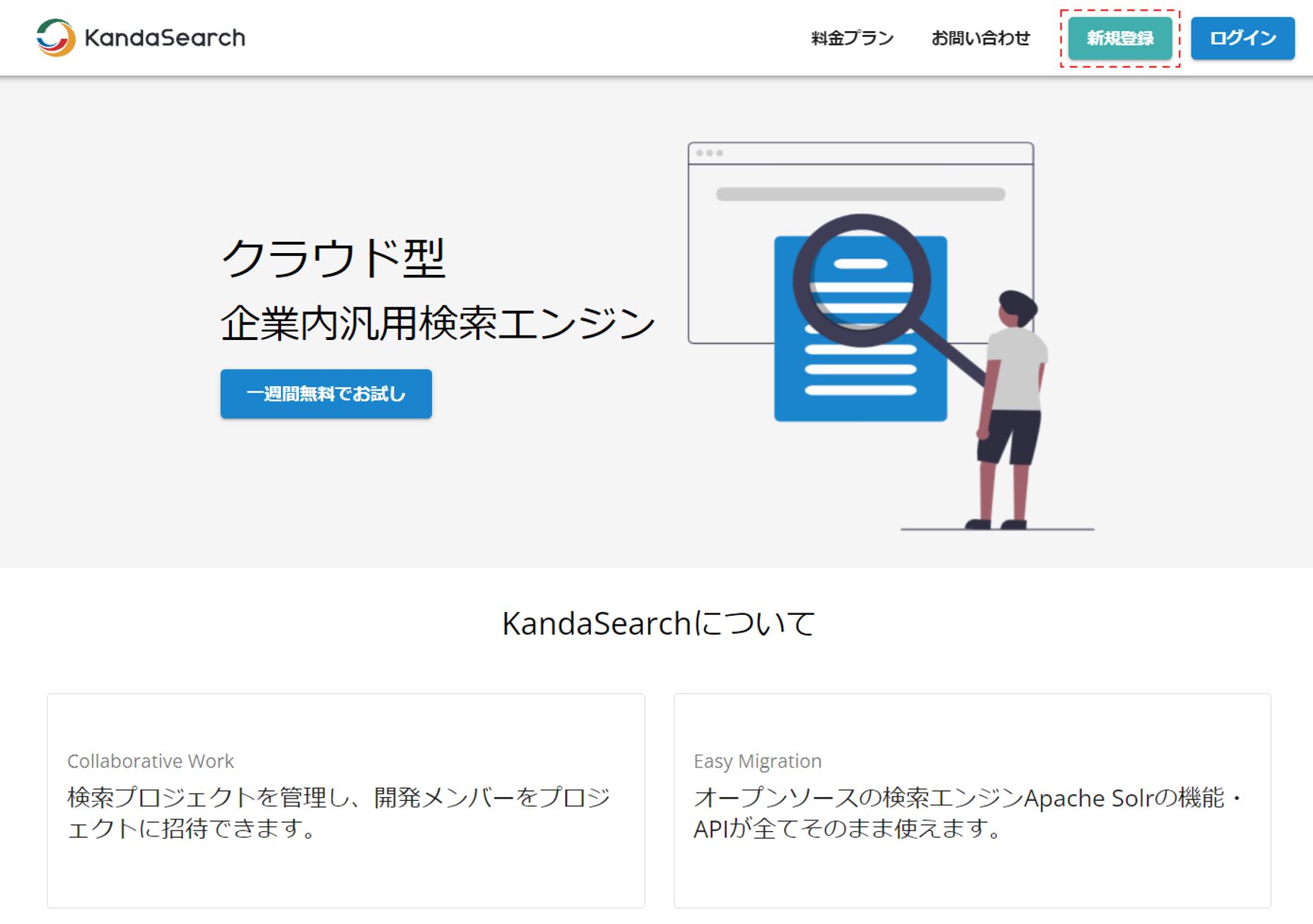
上段の「新規登録」をクリックする。
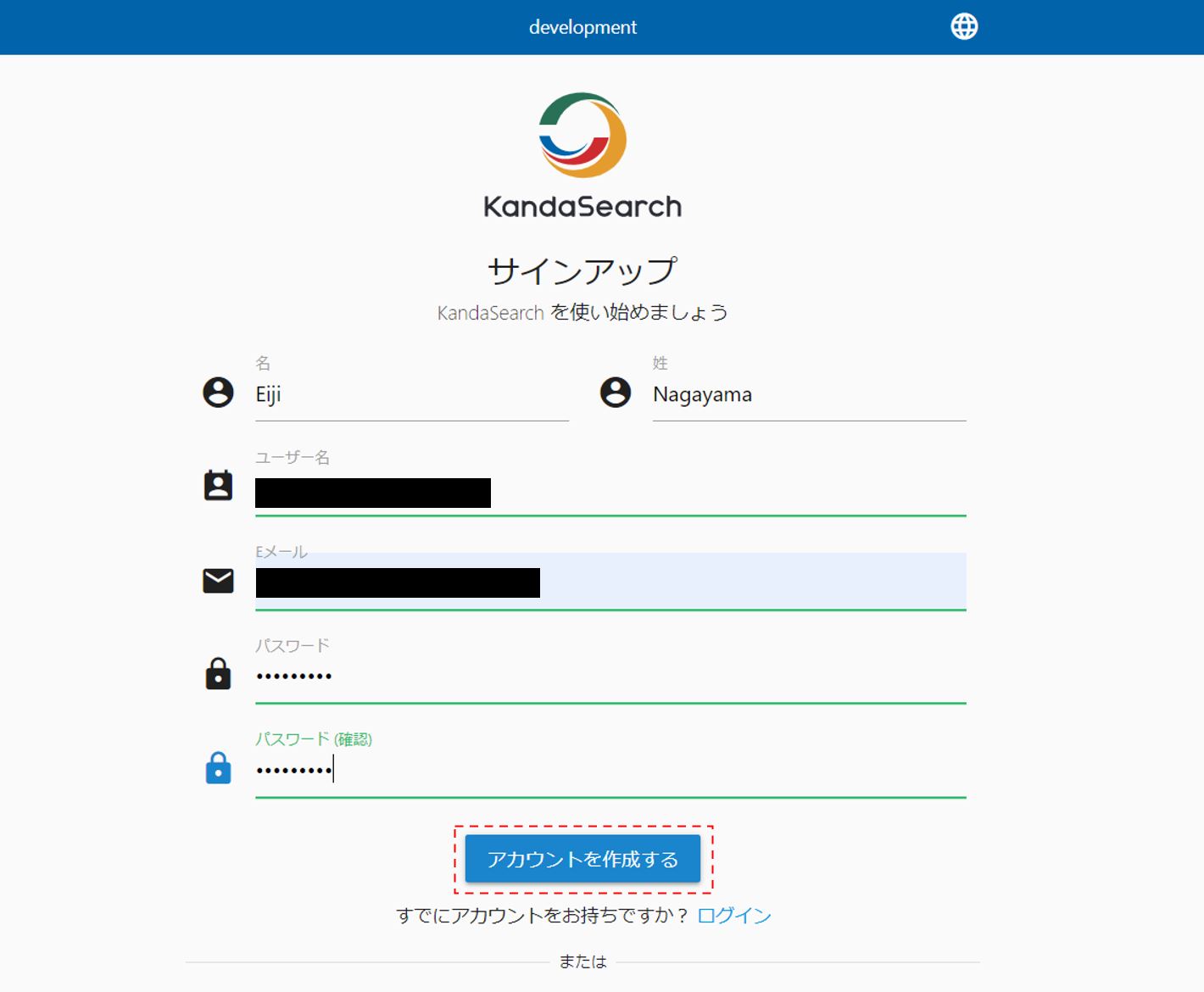
項目を入力し、「アカウントを作成」をクリックすると利用規約画面になる。なお、KandaSearchはソーシャルログインにも対応している。(記事執筆時点ではGOOGLE,GITHUB,GITLAB,TWITTERの4つ)
利用規約を一番下迄スクロールすると「同意する」がクリックできるようになるので「同意する」をクリックすると、確認メールを送信した旨が表示される。
確認メールを送信した旨が表示されたら、Eメールを開き、メール上の「メールアドレスの確認」をクリックしログインする。
プロジェクト作成
ログイン直後の初期画面では”プロジェクトが存在しません”というメッセージが表示される。まずはプロジェクトを作成する。画面上の「プロジェクトを作成する」をクリックする。
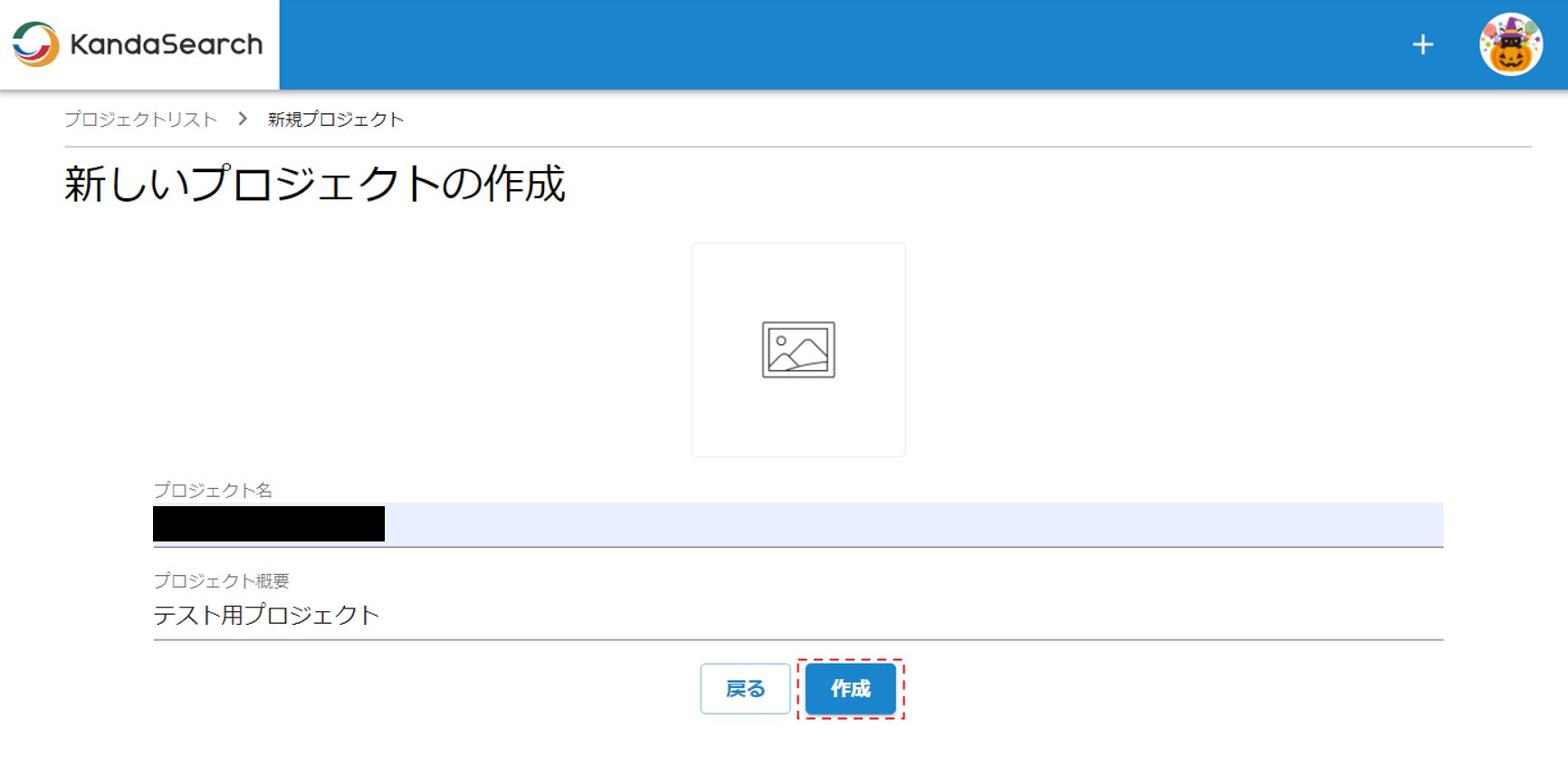
プロジェクト名と概要を入力し「作成」をクリックするとプロジェクトのオーバービュー画面が表示される。プロジェクトのオーバービュー画面の左側のメニューバーにはオーバービュー、メンバー、お支払い情報設定、サポート、設定といった項目があることに注意。
またプロジェクト作成直後には”インスタンスが存在しません”というメッセージが表示される。 次にインスタンスを作成する。画面上の「新しいインスタンス」をクリックする。
インスタンス作成
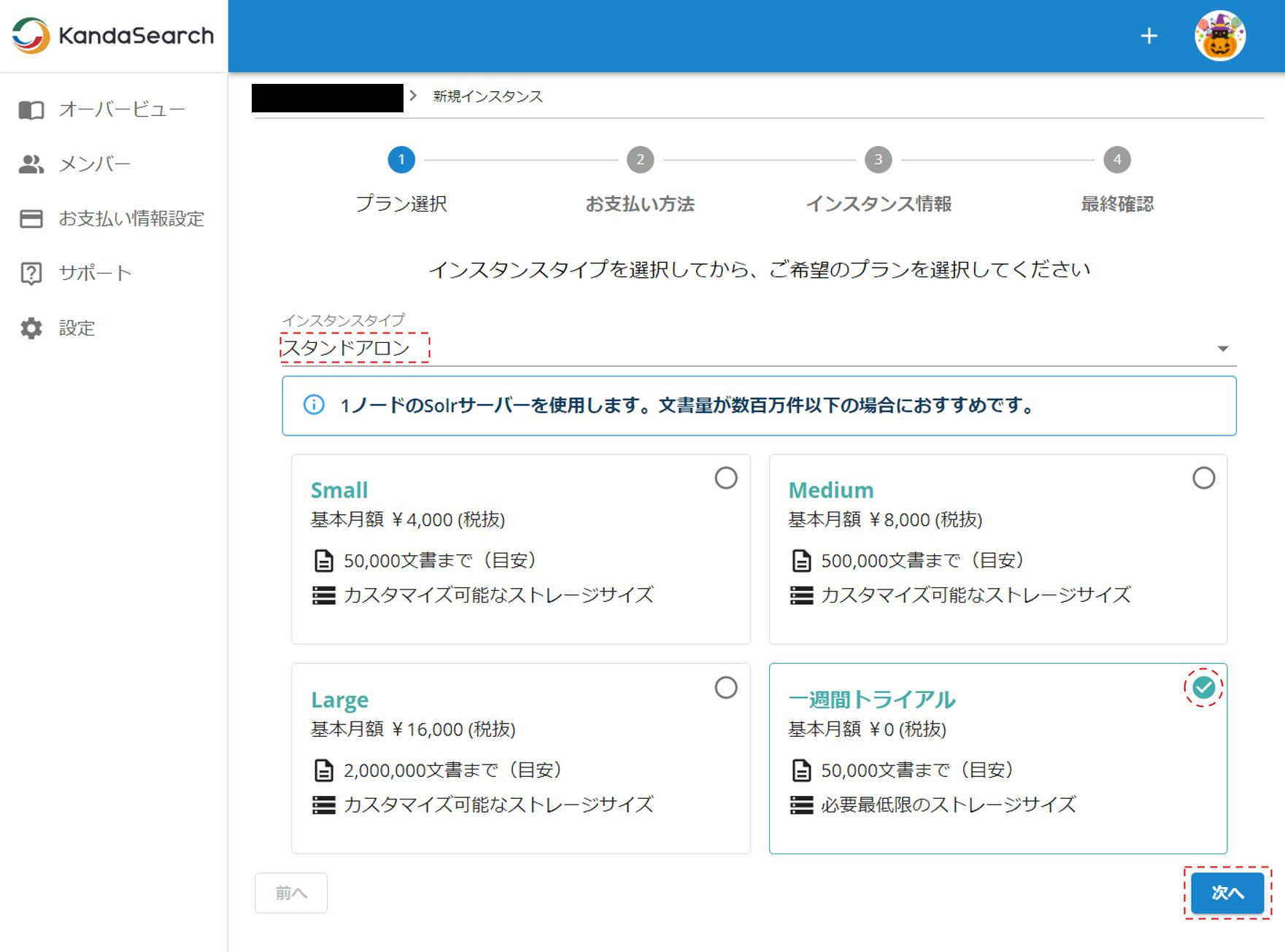
プラン選択画面が表示されたら。インスタンスタイプに「スタンドアロン」を選択し、一週間トライアルをチェックして「次へ」をクリックする。
お支払方法では、そのまま「次へ」をクリックする。
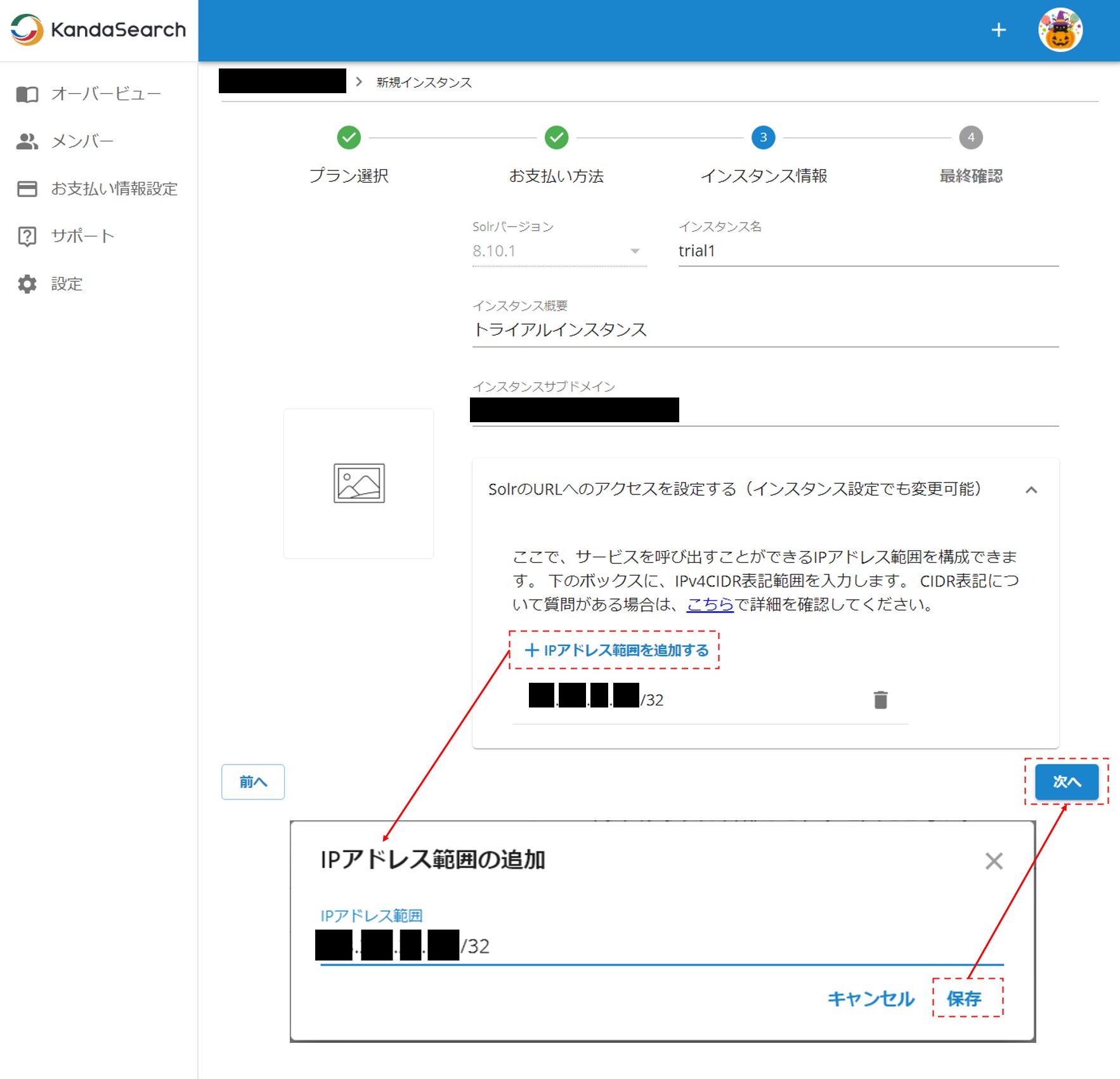
インスタンス情報ではインスタンス名とインスタンス概要を入力する。インスタンスサブドメインは自動生成で良いであろう。
なお、Solrバージョンは、トライアル版だとその時点の最新が強制的に選ばれるため8.10.1(執筆時時点の2021年10月での最新)が強制的に選択されているが、有料インスタンスはバージョンを選ぶことができる。
次にインスタンスに接続するために接続元のIPアドレスを入力する。接続元IPアドレスの登録をしなければデータ登録をしたりSolr管理画面を開くことができない。 「+IPアドレス範囲を追加する」をクリックする。 なお、この作業はインスタンス作成後に、インスタンスオーバービュー画面の左側メニューバーの設定から行うこともできる。
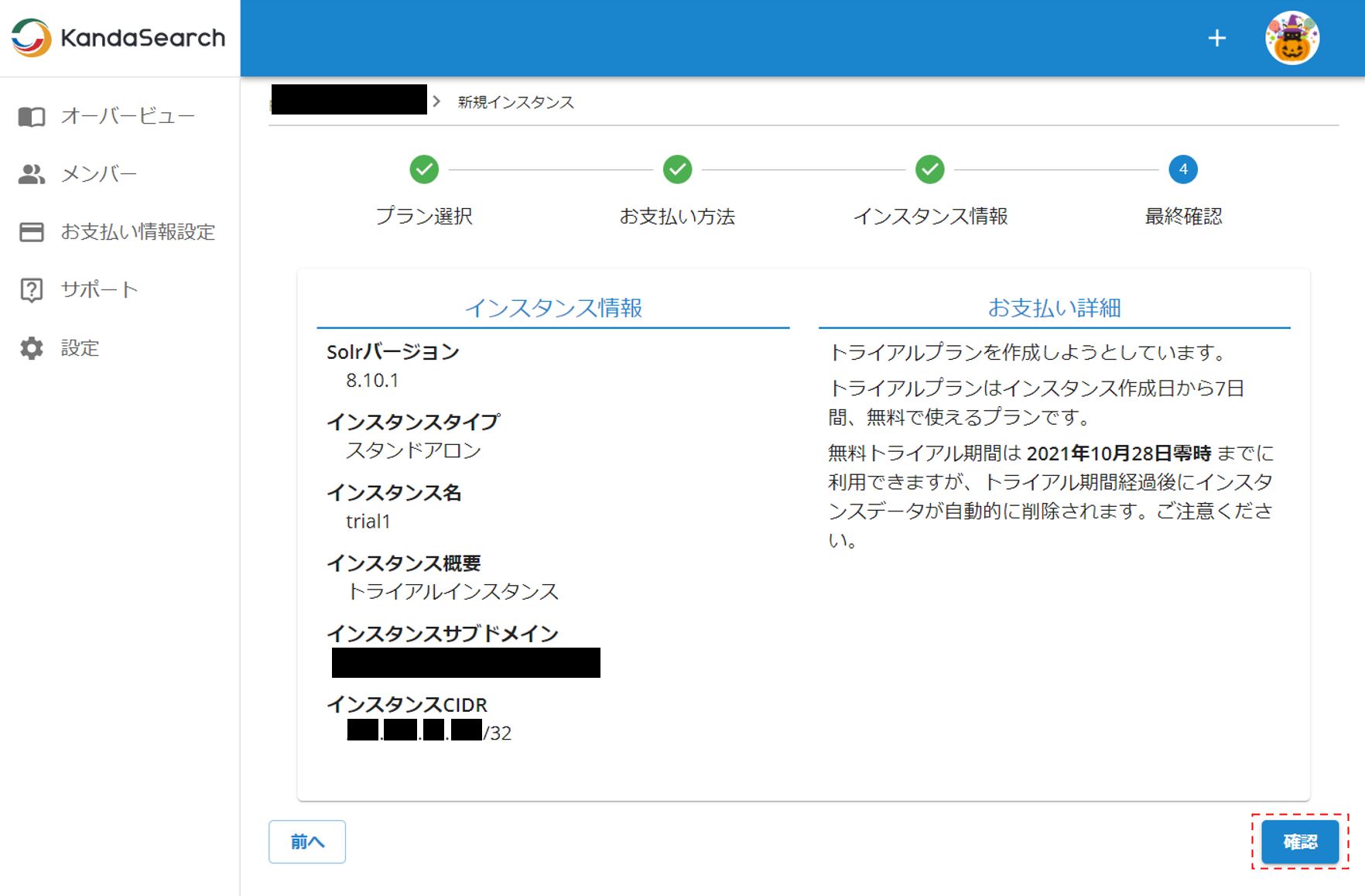
最終確認画面で確認をし誤りがなければ「確認」をクリックする。これによりインスタンスが追加される。但し起動するには多少時間がかかる。
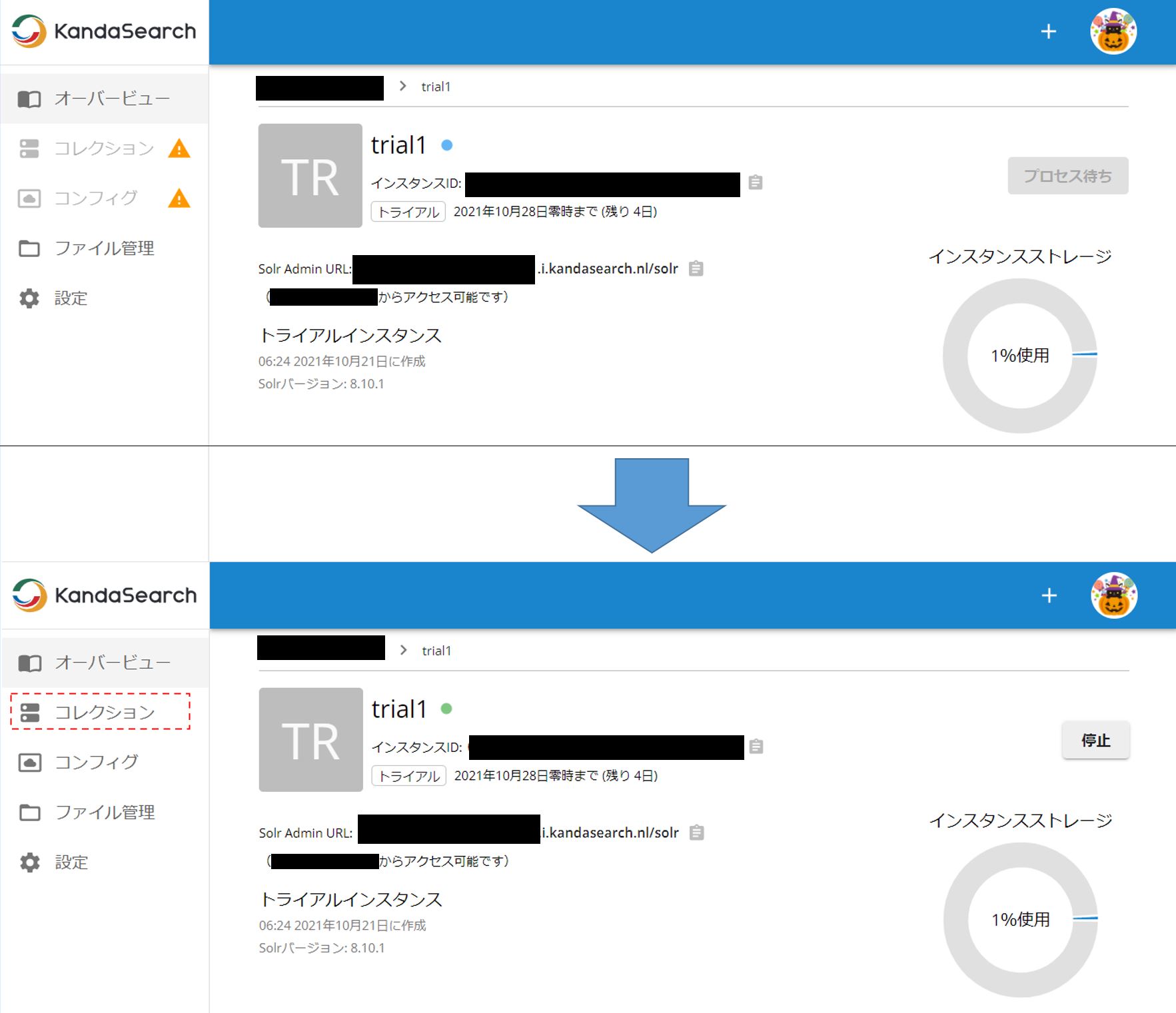
インスタンス名(ここではtrial1)の右の青い丸印がグリーンになったら起動したということである。 なお、Solr Admin URL は、Solr管理画面を開いたりデータを登録する際に使用されるURLである。インスタンス情報で許可したIPからしかアクセスできないとは言え、むやみに教えない方がよいであろう。 また、この画面がインスタンスのオーバービュー画面になる。左側のメニューバーがプロジェクトのオーバービュー画面のメニューとは異なり、オーバービュー、コレクション、コンフィグ、ファイル管理、設定となっていることに注意。
インスタンスが起動したら、次にコレクションの設定に移る。それでは、左側メニューバーの「コレクション」をクリックする。
コレクション作成
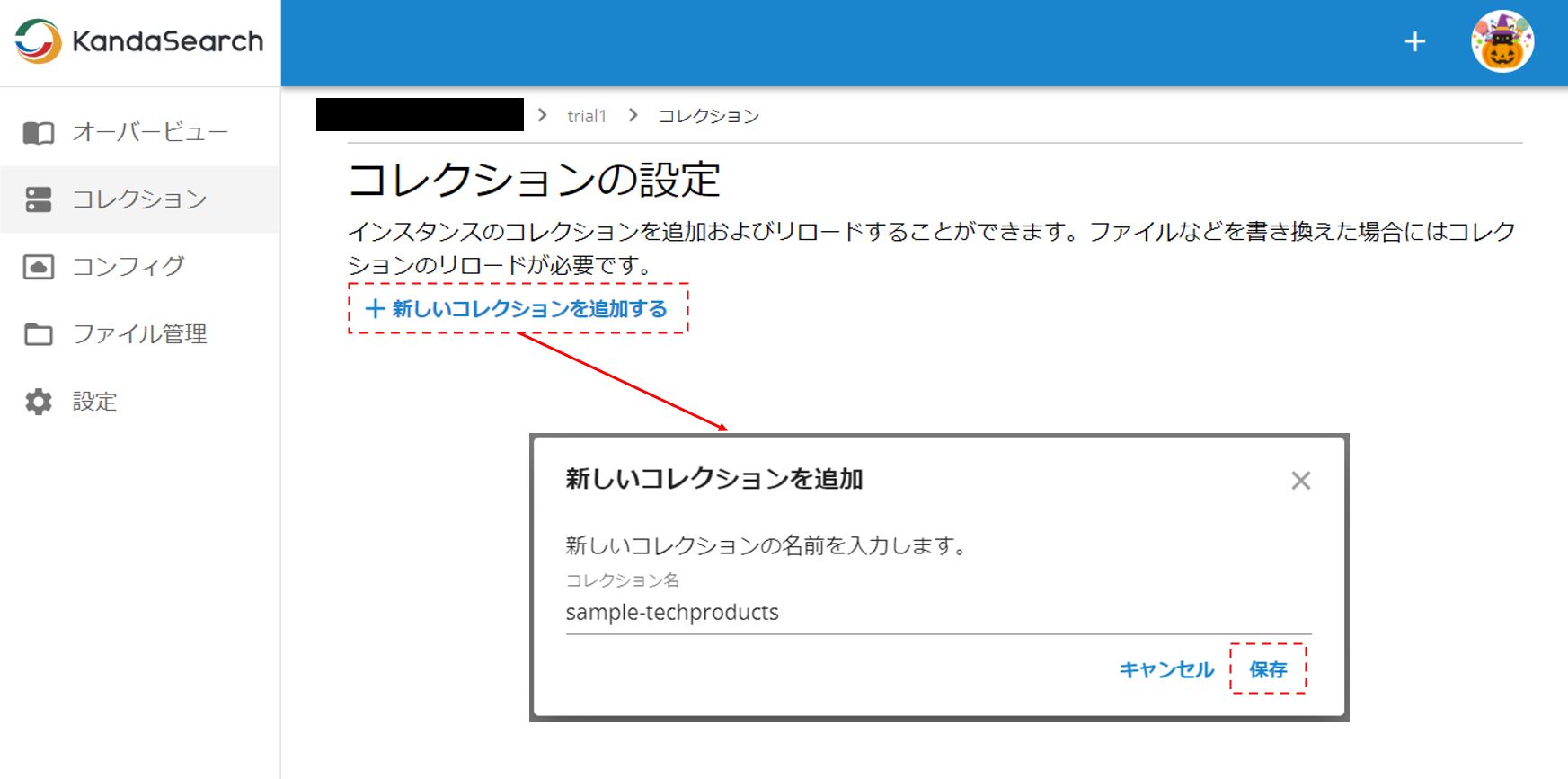
「新しいコレクションを追加」をクリックし、適当なコレクション名を入力し「保存」をクリックする。
コレクションが追加される。 追加されたコレクションはSolrに付属しているsample_techproductsと同じ形式(schema)になっている。 sample_techproductsはsolr-8.10.1の場合は、 solr-8.10.1\server\solr\configsets\sample_techproducts_configs\confにサンプルとして付属しており、solr-8.10.1\example\exampledocs内のサンプルドキュメントを以下で登録することができる。
linuxの場合
ここで、URLはSolr Admin URLである。(●●●●●●●●●●.i.kandasearch.comの部分を正しい自分のURLに置き換えて試して欲しい。)
postを利用できないWindows環境の場合には以下となる。
以下は正しくデータ登録できた時の実行ログである。(筆者の環境は8.10.0で行った)
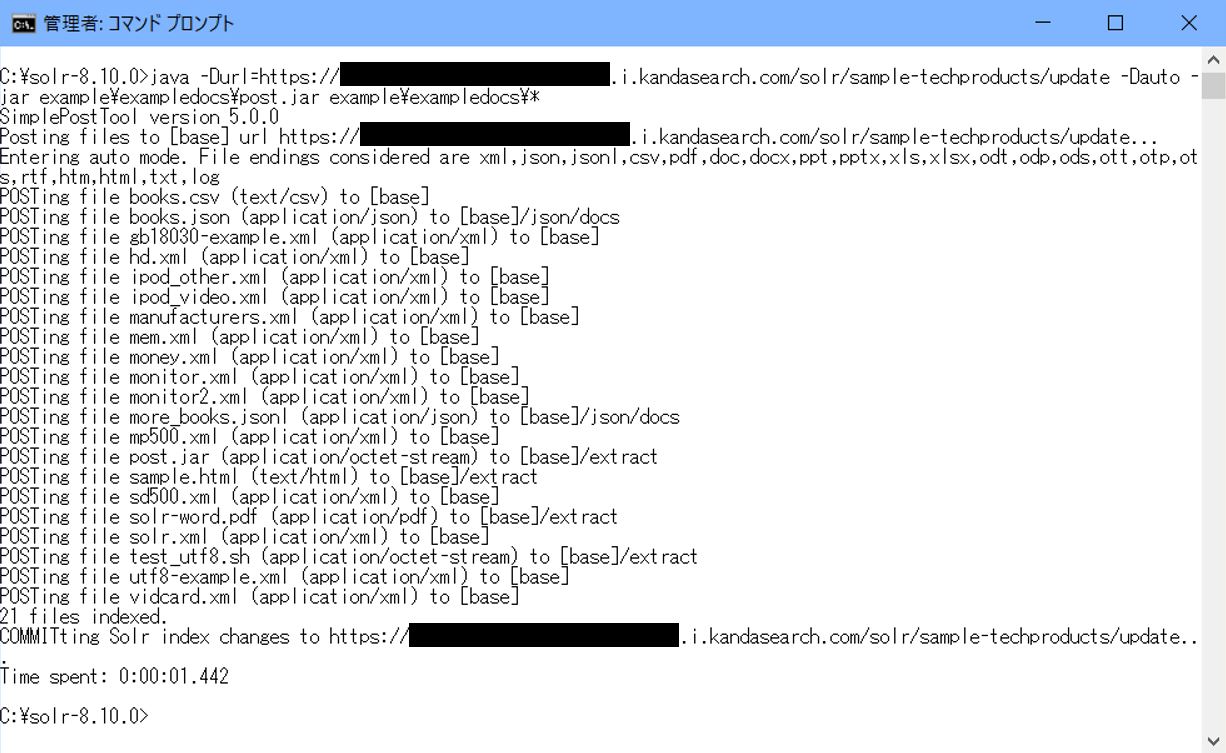
(注)データ登録はあらかじめ設定したIPアドレスからでなくては行うことができない。また、データ登録だけでなくSolr管理画面を開くこともできないので注意して欲しい。
Solr管理画面を使って検索をしてみる
データ登録が出来たら、そのデータをSolr管理画面を使って検索してみる。Solr Admin URLをブラウザのアドレスバーに直接入力する。
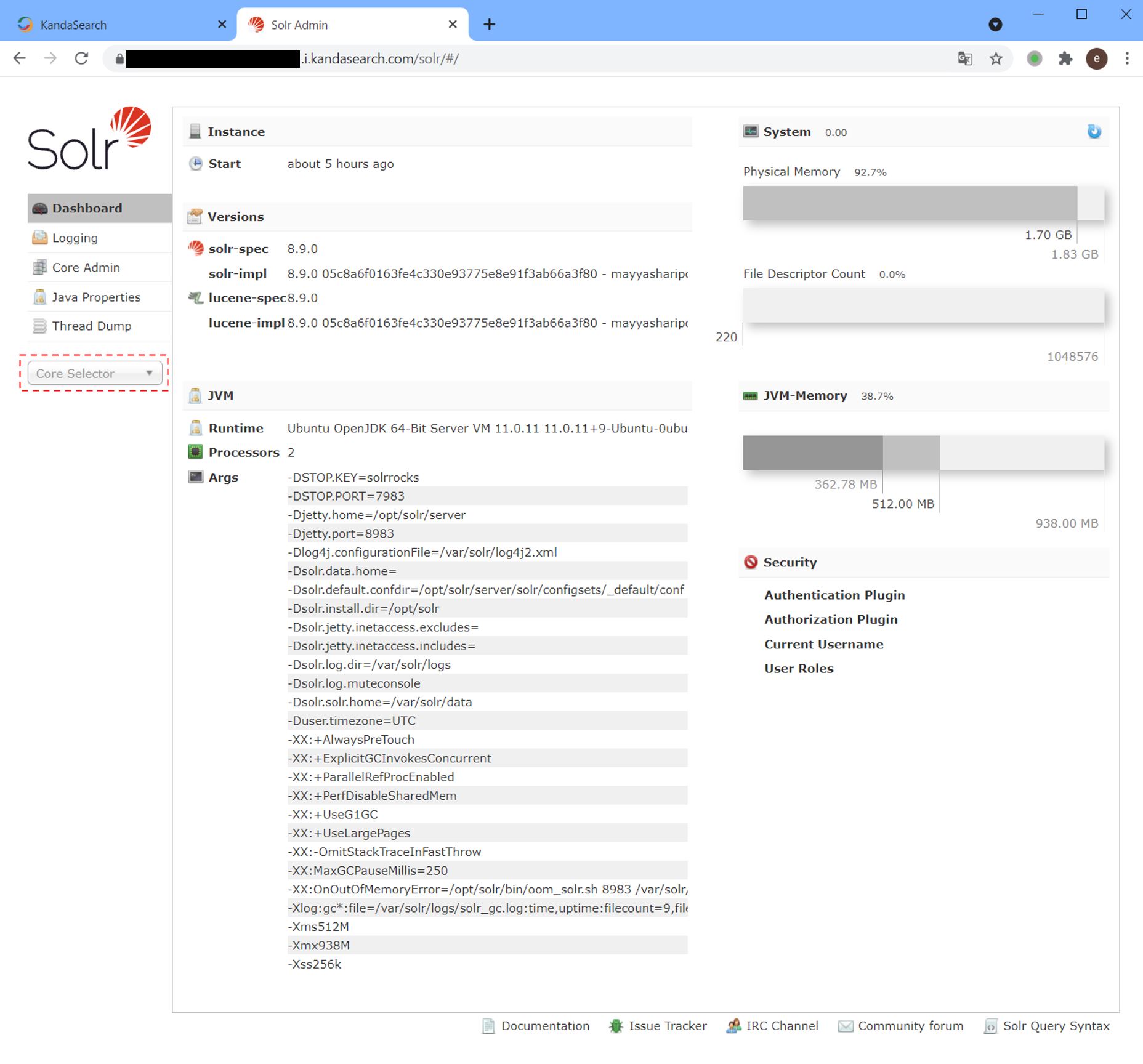
Solr管理画面が開いたら左側のメニューの「Core Selector」から作成したコレクションを選択する。ここではsample-techproductsを選択。
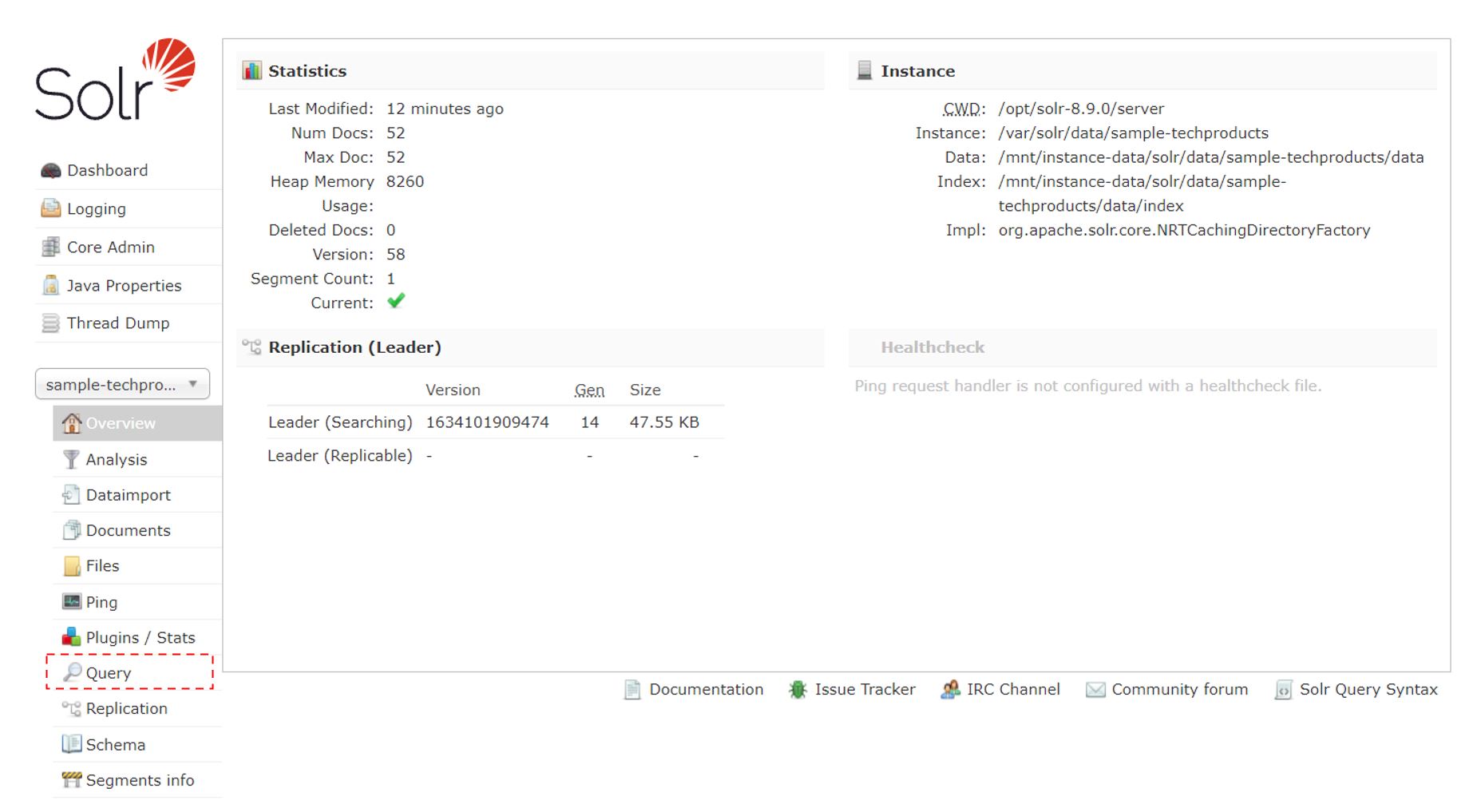
左側メニューの「query」をクリック。
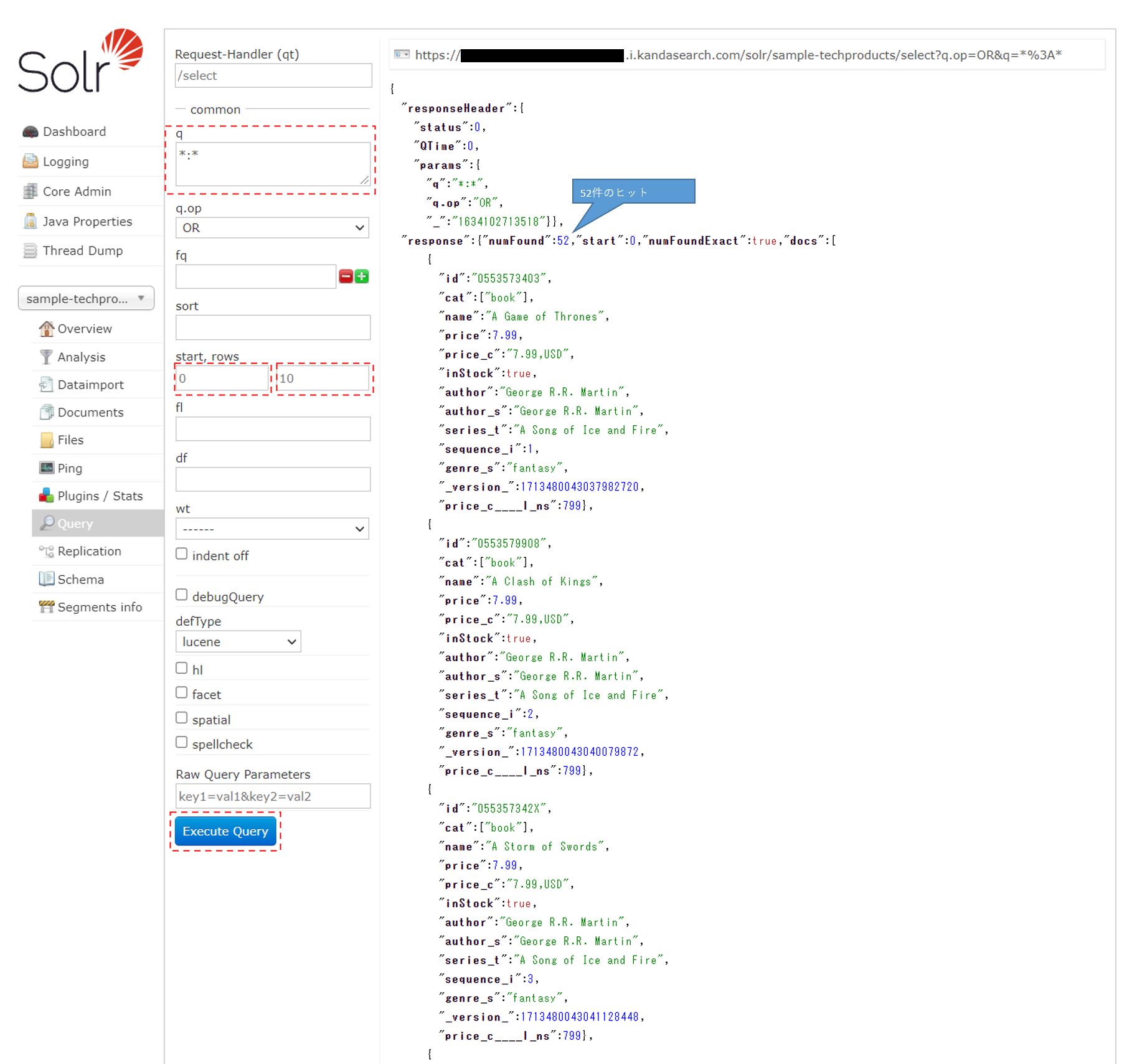
qに「*:*」(全件検索)が入っているのを確認して「Execute Query」をクリックすると登録したドキュメントが全件検索できる。52件の登録があることがわかる。
なお、画面をスクロールしても検索結果は10件しか表示されない。これを増やすにはrowsに大きな数を入れて検索すればよい。試しにrows=100として再検索してみて欲しい。今度は検索結果として52件ちゃんと表示されるはずである。しかし検索結果が10000件近い場合はどうであろう。rows=10000として全件をサーバーから返してもらうのは転送量が増えてネットワーク負荷が重くなる。なので、rowsは数十件くらいにしておいてページ送りするような方法で検索したほうが良い。
検索結果を順次返すための仕組みが、startである。startは検索結果の何番目から表示するのかを指定する。(一番目はstart=0である)
start=0,rows=10
start=10,rows=10
start=20,rows=10
・
・
・
とすることにより、検索結果が先頭から順次10件ずつ表示される。
検索結果を順次取得するために「Execute Query」をクリックし毎回再検索を行うことになるが、Solrの検索ではこの方法が通例となっている。
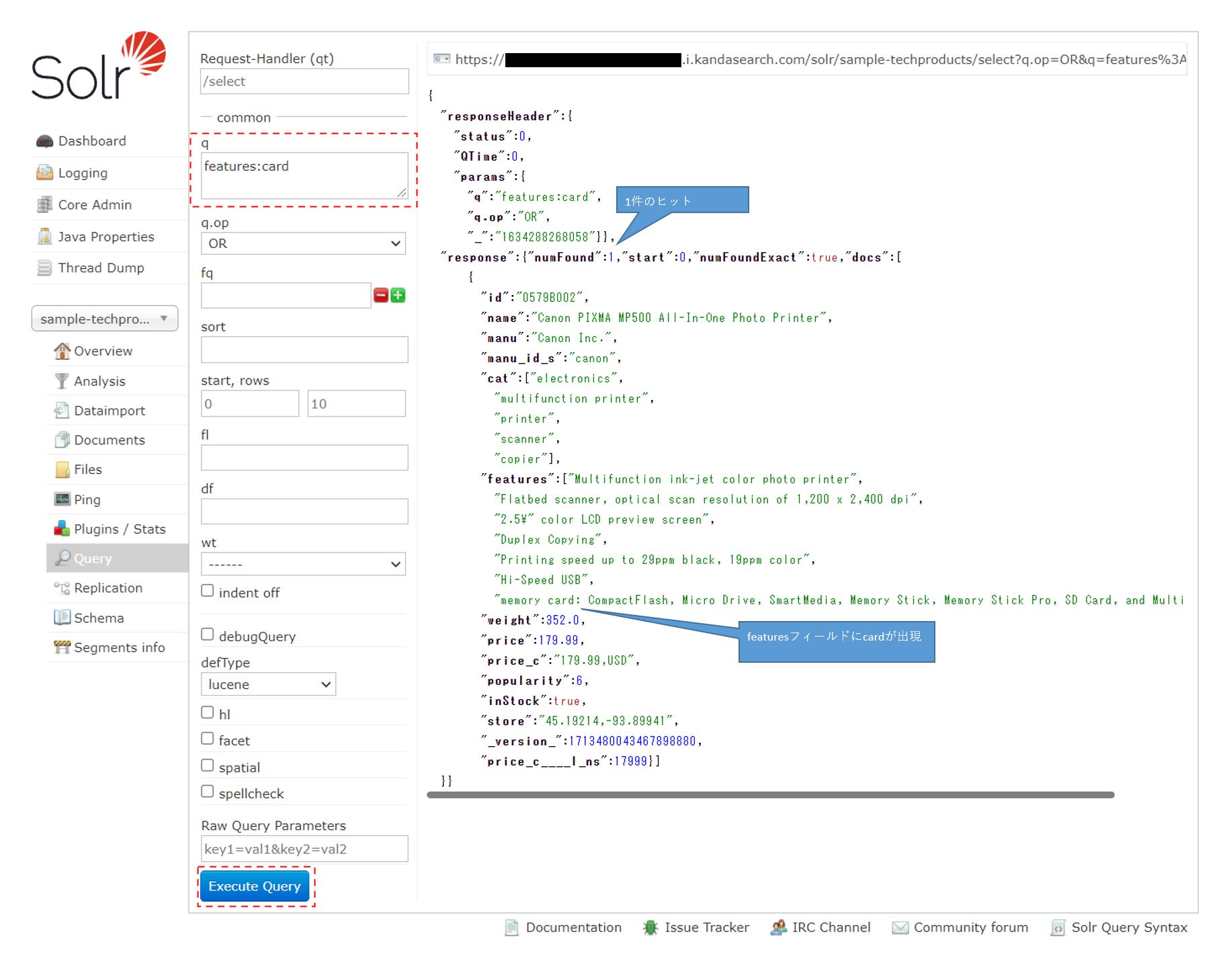
次にqに「features:card」を入力して「Execute Query」をクリックすると、featuresにcardが入っているレコードが1件だけヒットする。フィールドを指定しての検索方法である。
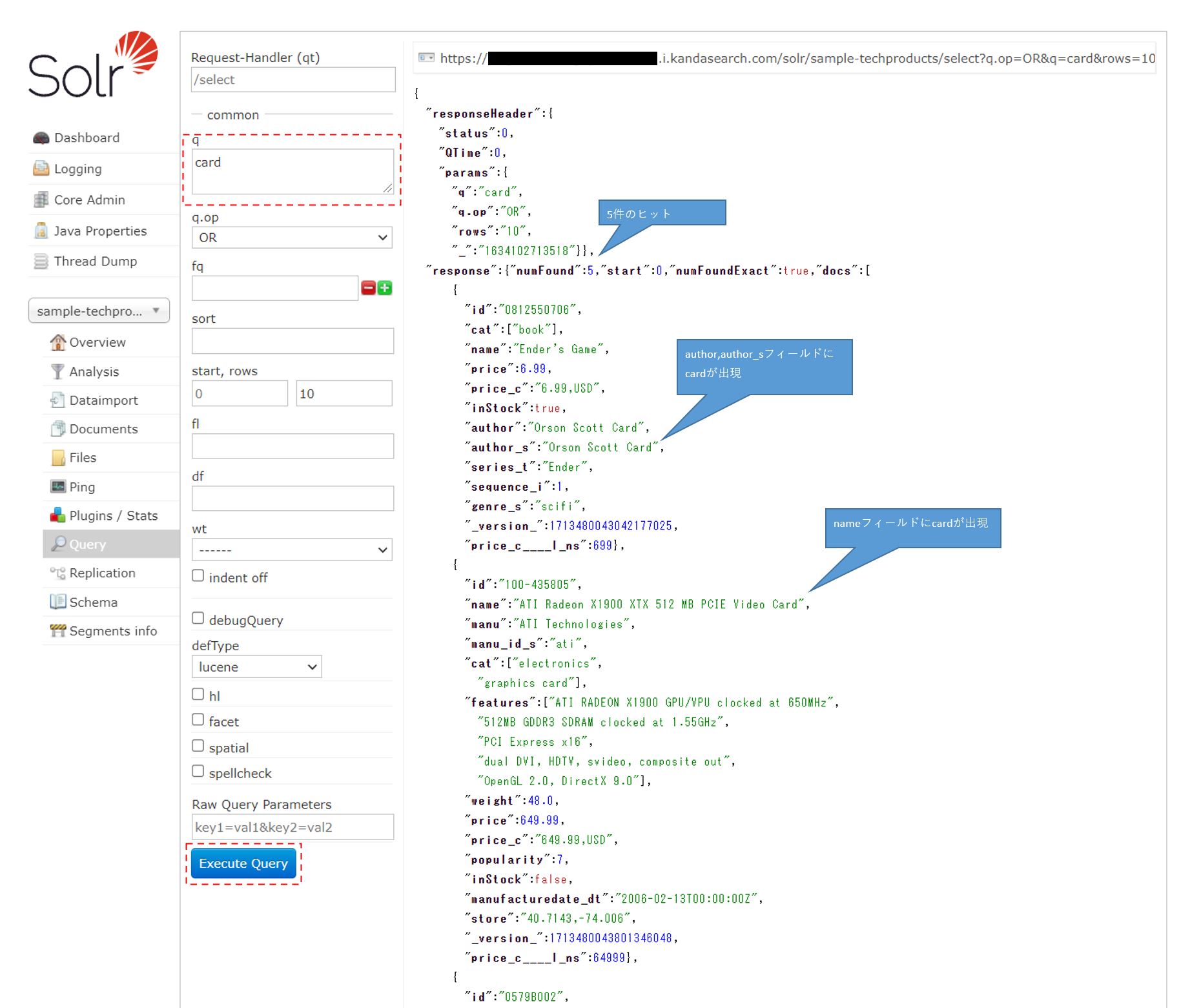
フィールドを指定せずにqに「card」だけを入力して「Execute Query」をクリックした場合はsample-techproductsではデフォルトでtextというフィールドが検索されるようになっている。すなわちqに「text:card」と入力したのと同じである。
textというフィールドは、以下のようにcat、name、manu、features、includes・・・というフィールドをコピーして作られたフィールドとなっている。
<copyField source=”name” dest=”text”/>
<copyField source=”manu” dest=”text”/>
<copyField source=”features” dest=”text”/>
<copyField source=”includes” dest=”text”/>
・
・
・
そしてsolrconfig.xmlで以下のようにデフォルト検索フィールドとしてtextフィールドが設定されている。
<lst name=”defaults”>
<str name=”df”>text</str>
</lst>
</initParams>
したがって、textを検索対象とするだけで各フィールドにわたっての横断検索がなされるような感じになる。
5件ヒットするが、ドキュメント中のどこかにcardが必ず出てきているはずである。
しかしながら、通常、textフィールドのような、全てのフィールド内容をくっつけたフィールドを設定することはない。では、複数のフィールドに渡る横断検索はどのようして行うのであろうか?
sample-techproductsでは、author,author_s,name,features,includes,catという項目に、それぞれ”card”というワードが存在する。
もし、sample-techproductがRDBのテーブルでありSQLを使って検索を行った場合は、検索SQLは以下のような感じになるであろう。
同様のことをSolrで行うには edismax というものを使う。Solr管理画面から試してみよう。
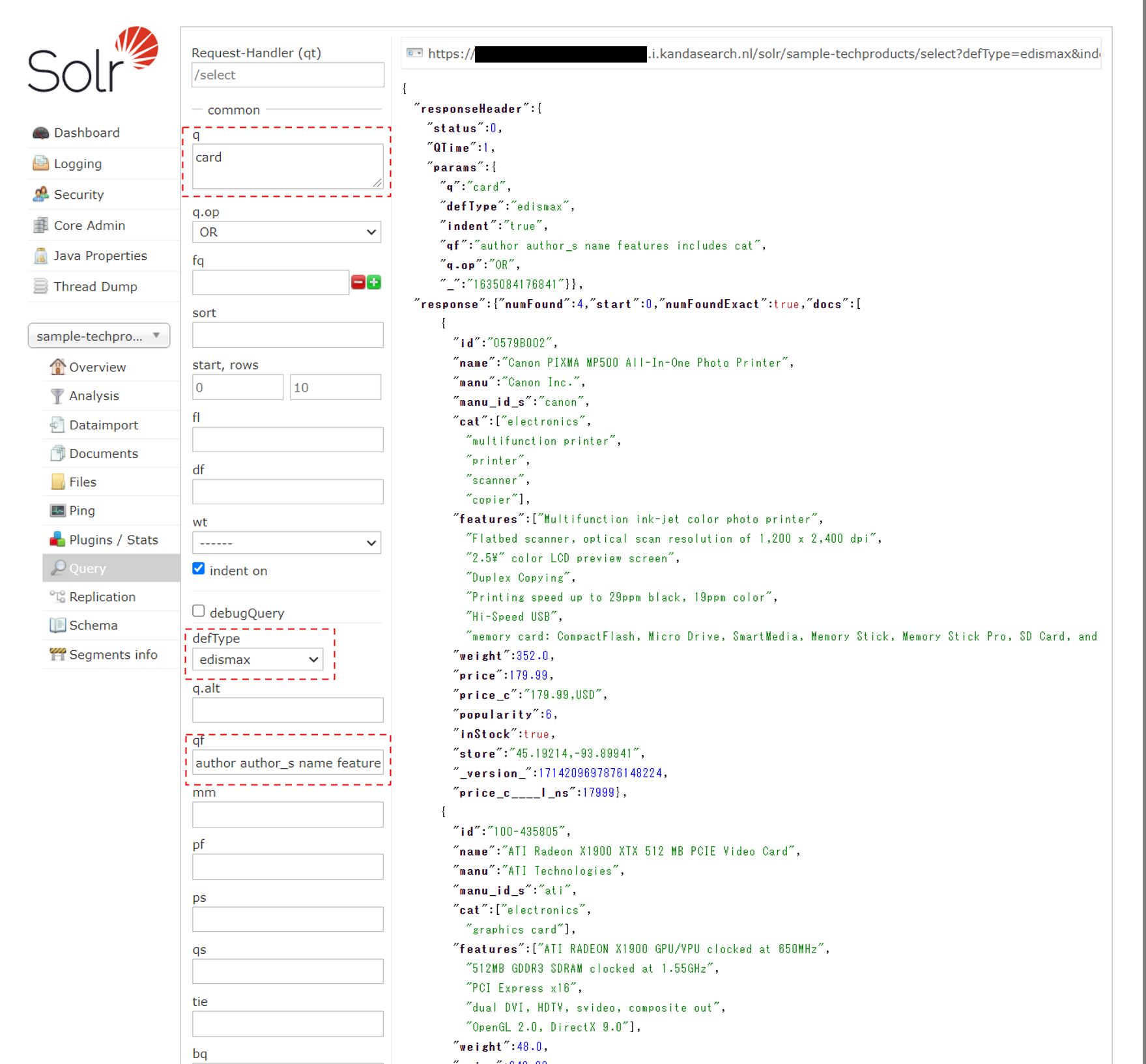
defTypeは、「edismax」を選択し、qfに「author author_s name features includes cat」を入力、あとはqに「card」を入力して「Execute Query」をクリックするだけで横断検索が走る。しかも、この検索方法は別ファイルに記述することもでき、その場合qに検索語を入れ「Execute Query」をクリックするだけで毎回横断検索が実行される。
ところで、読者諸君の中には検索されたドキュメント数が違うと思った方がいるかもしれない。先ほどtextフィールドの検索についての説明をしたが、その時のヒット数は5件であった。今回横断検索では1件検索されないドキュメントがある。そのドキュメントは以下である。
“name”:”ASUS Extreme N7800GTX/2DHTV (256 MB)”,
“manu”:”ASUS Computer Inc.”,
“manu_id_s”:”asus”,
“cat”:[“electronics”,
“graphics card”],
・
・
・
cat に、cardという単語が入っているがこれが検索に引っかかってこない。その理由は、索引の作成方法が違うからである。簡単に説明すると、先のtextフィールドによる索引の作られ方が一つの単語単位であるのに対し、catフィールドの場合は、複数の単語単位であるということである。
例を挙げると、textフィールドには以下のような内容が入り、これが単語に分割され索引が作られる。
作られた索引
| 索引語 | このidのドキュメントに存在 |
|---|---|
| 256 | EN7800GTX/2DHTV/256M |
| 256m | EN7800GTX/2DHTV/256M |
| 2dhtv | EN7800GTX/2DHTV/256M |
| asus | EN7800GTX/2DHTV/256M |
| card | EN7800GTX/2DHTV/256M |
| computer | EN7800GTX/2DHTV/256M |
| electronics | EN7800GTX/2DHTV/256M |
| en7800gtx | EN7800GTX/2DHTV/256M |
| extreme | EN7800GTX/2DHTV/256M |
| graphics | EN7800GTX/2DHTV/256M |
| inc | EN7800GTX/2DHTV/256M |
| mb | EN7800GTX/2DHTV/256M |
| n7800gtx | EN7800GTX/2DHTV/256M |
cardで検索した場合、索引にcardが存在するので、”id”:”EN7800GTX/2DHTV/256M”のドキュメントに存在するということがわかる。
一方、横断検索の場合は、catフィールドを検索することになるが、catフィールドの索引の作られ方は以下となる。
| 索引語 | このidのドキュメントに存在 |
|---|---|
| electronics | EN7800GTX/2DHTV/256M |
| graphics card | EN7800GTX/2DHTV/256M |
索引に存在するのは、”graphics card”であり、”card”だけで検索しても引き当てることができない。これが、横断検索の場合に、”id”:”EN7800GTX/2DHTV/256M”のドキュメントが検索されない理由である。
プロジェクトへのメンバーの追加
プロジェクトへのメンバーの追加方法だが、プロジェクトのオーバービュー画面を開く。この画面を開くには以下の2つの方法がある。
一つは、KandaSearchのどの画面にもある左上のKandaSearchロゴをクリックする。プロジェクトリスト画面が表示されるのでプロジェクトを選択すればよい。
もう一つはパンくずリストが上部に表示されている画面ではプロジェクト名をクリックする。
KandaSearchロゴとパンくずリスト例(ここではプロジェクト名は黒塗りになっている){kind=link}
左側メニューバーの「メンバー」をクリック。
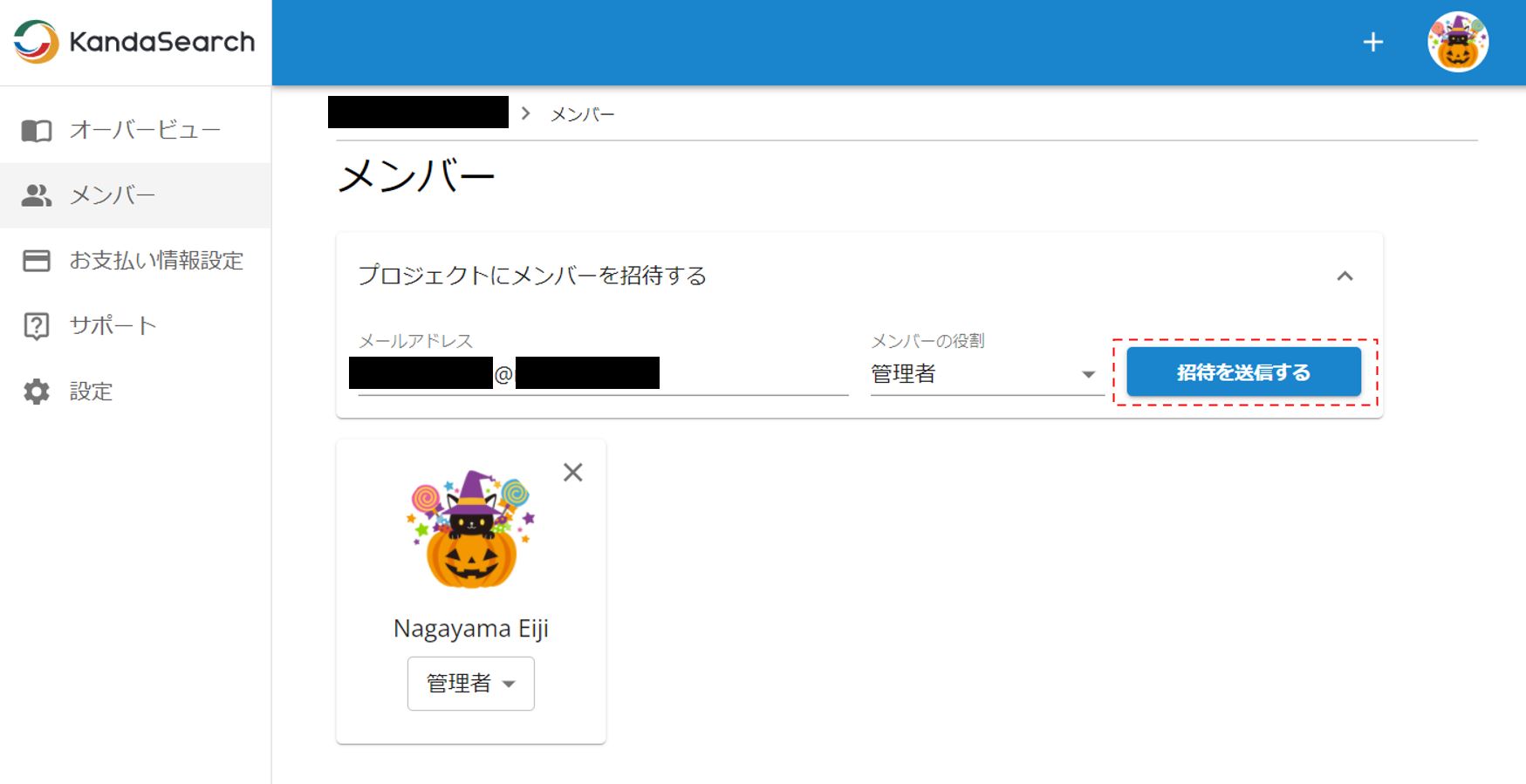
メンバーのメールアドレスを入力しメンバーの役割を選択したら、「招待を送信する」をクリック。メンバーに招待メールが送信される。
二要素認証
KandaSearchは二要素認証(2FA)にも対応している。企業内の重要書類が登録されるわけなので2FAに対応しているということはセキュリティ上心強い。
まずKandaSearchのどの画面にもある左上のアカウントロゴをクリックし、「アカウント設定」を選択する。
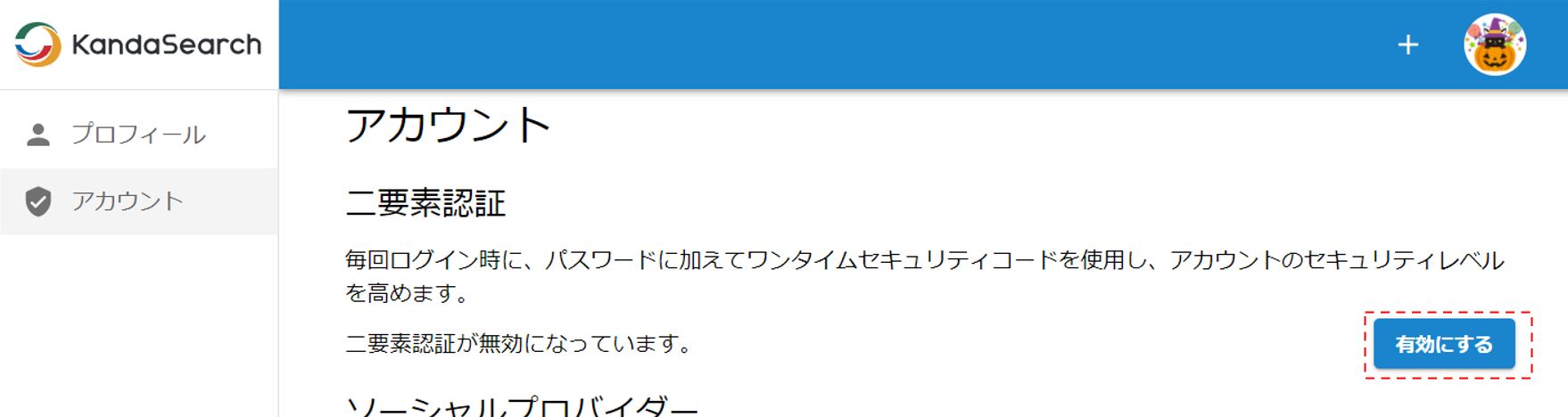
二要素認証の「有効にする」をクリック。
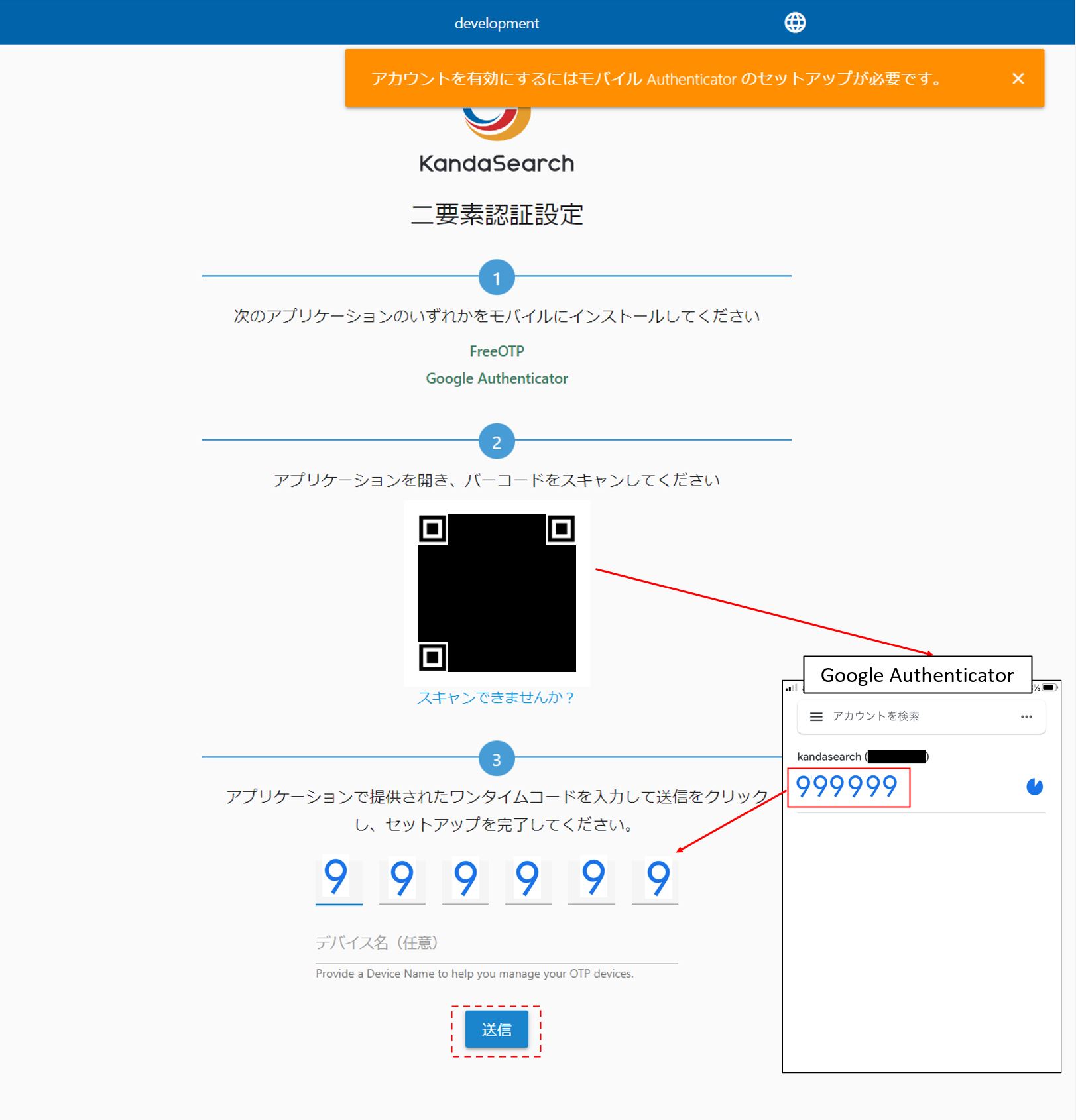
二要素認証の設定手順に従い設定を行う。なお、画面はGoogle Authenticatorをスマートホンにインストールしてワンタイムコードを入力した例である。これ以降ログインをする際にはGoogle Authenticatorに表示されるワンタイムコードの入力が必要となる。なお、QRコードを他人に教えると同様にスマートホンでワンタイムコードを生成されてしまうので、QRコードは教えてはいけない。
SolrCloud
記事の冒頭の方で述べたが、Solrのサーバー構成にはスタンドアロン構成とSolrCloud構成の二種類がある。
ここで、SolrCloudのCloudは、クラウド上で動くという意味ではない。KandaSearchのスタンドアロンSolrだってクラウド上で動いている。ではスタンドアロンSolrとSolrCloudの違いは何であろうか?答えを簡単に言うならSolrサーバーを構成するサーバーマシンの台数である。
スタンドアロンSolrがサーバーマシン1台から構成されているのに対し、SolrCloudでは複数台のサーバーから構成される。インデックスファイルをいくつかのシャード(shard)に分割し、さらにサーバー間で多重化することにより、負荷分散したり、耐久性を上げる仕組みになっている。例えばこれにより、サーバーが1台落ちてもSolr全体では正常な動作が期待できる。またサーバー1台止めてサーバーメンテナンスを行うなどといったことが可能になる。企業業務でSolrを導入する場合にはこのSolrCloud構成が通例となっている。
但し、このSolrCloud構成によるSolr構築はスタンドアロンの比にならないくらいハードルが高い。サーバー複数台にSolrを導入しなくてはいけないのはもちろんの事、Solr以外にもApache ZooKeeperという分散システムで使用するサービスを複数台のサーバーに導入し、これら全部が矛盾なく動作するようにサーバー構築を行わなければならない。
KandaSearchではこのSolrCloudで構成されたSolrの構築を簡単に行える。しかも、スタンドアロン構成と同様一週間無料でお試しができる。
以下は、SolrCLoud構成とスタンドアロン構成との相違点、注意点である。
SolrCloud用に新規にプロジェクトを作成する
一週間無料でお試しができるのはプロジェクトにつき1つのインスタンスだけである。そこでSolrCloud用の新しいプロジェクトを作成する。作成方法はスタンドアロンの時と同様である。なお無料お試しを行わない場合は、スタンドアロンとSolrCloud両方のインスタンスを1つのプロジェクトに入れることは自由である。
SolrCloudのインスタンスを作成する
SolrCloud用のプロジェクトの中に、SolrCloudのインスタンスを作成する。スタンドアロンの時と同様、プロジェクトのオーバービュー画面から「新しいインスタンス」をクリックする。
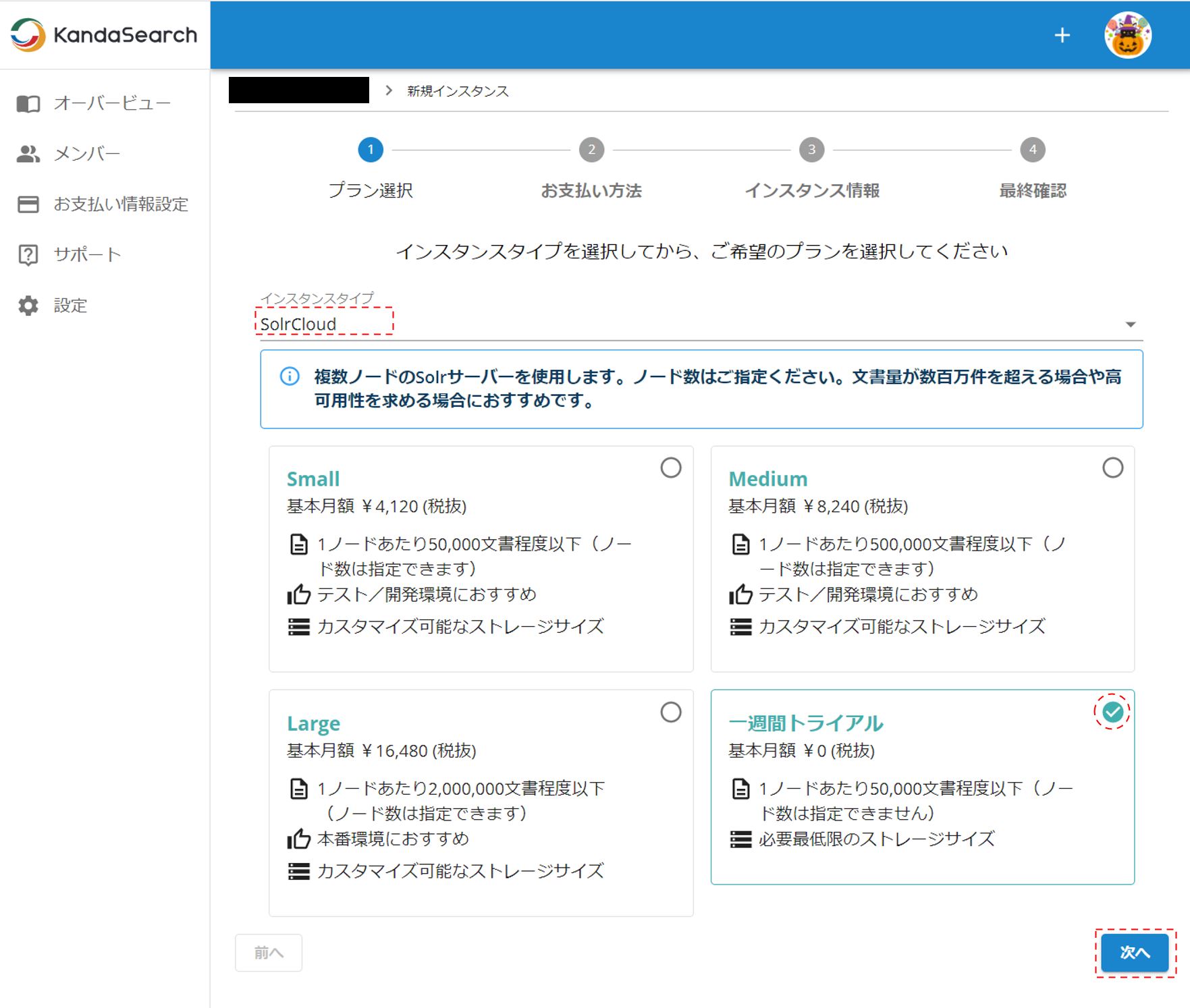
プラン選択では、インスタンスタイプはSolrCloudを選択し、一週間トライアルにチェックをして「次へ」をクリックする。
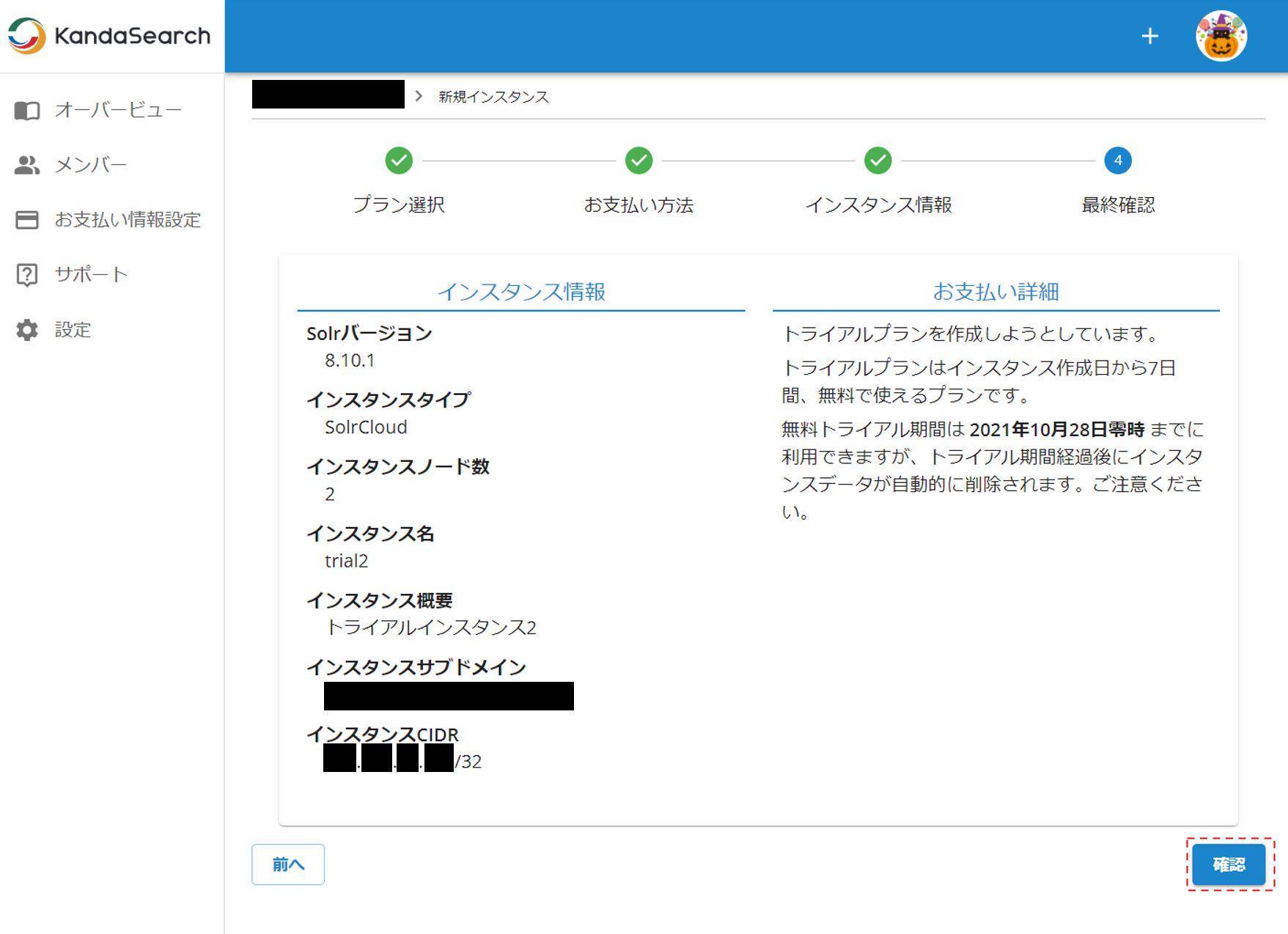
最終確認ではインスタンスノード数(サーバー台数)が2となっていることに注意。
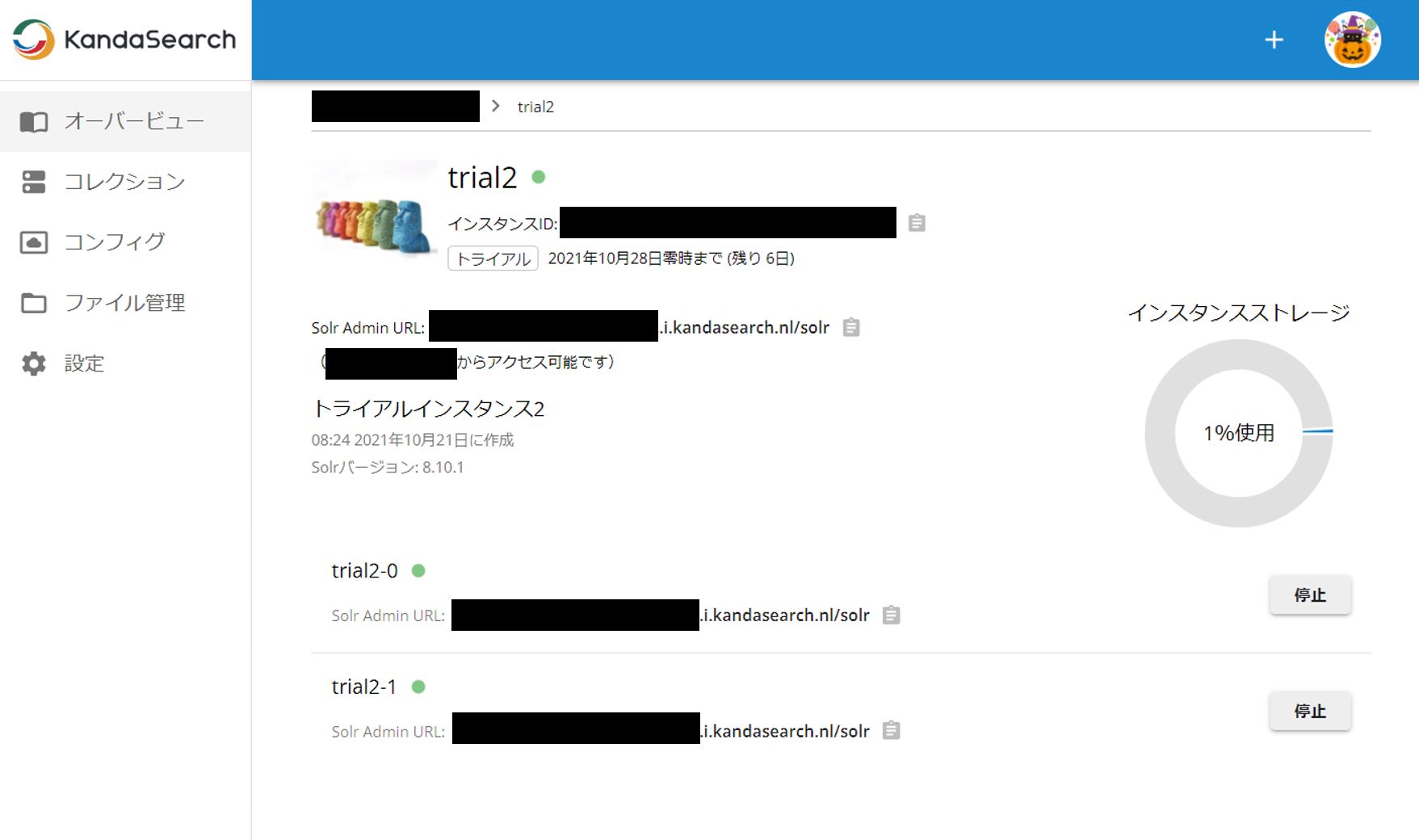
自動起動するがスタンドアロン構成の場合よりも時間がかかる。なお、余りにも時間がかかっている場合は、いったん別のページを表示し再度インスタンスのオーバービュー画面を表示すると状態がグリーン(起動)になっている場合がある。なお、画面上でtrial2-0、trial2-1となっているのが、SolrCloudを構成するインスタンスノード(サーバー)である。
なお、Solr Admin URLが、画面上3つある。通常は一番上のURLを使用すればよい。trial2-0、trial2-1それぞれの下にあるSolr Admin URLは、単一のサーバーに対するSolr Admin URLである。例えば何かの理由でtrial2-0だけにクエリを投げてみたい時などに使用できる。
SolrCloudのコレクションを設定する
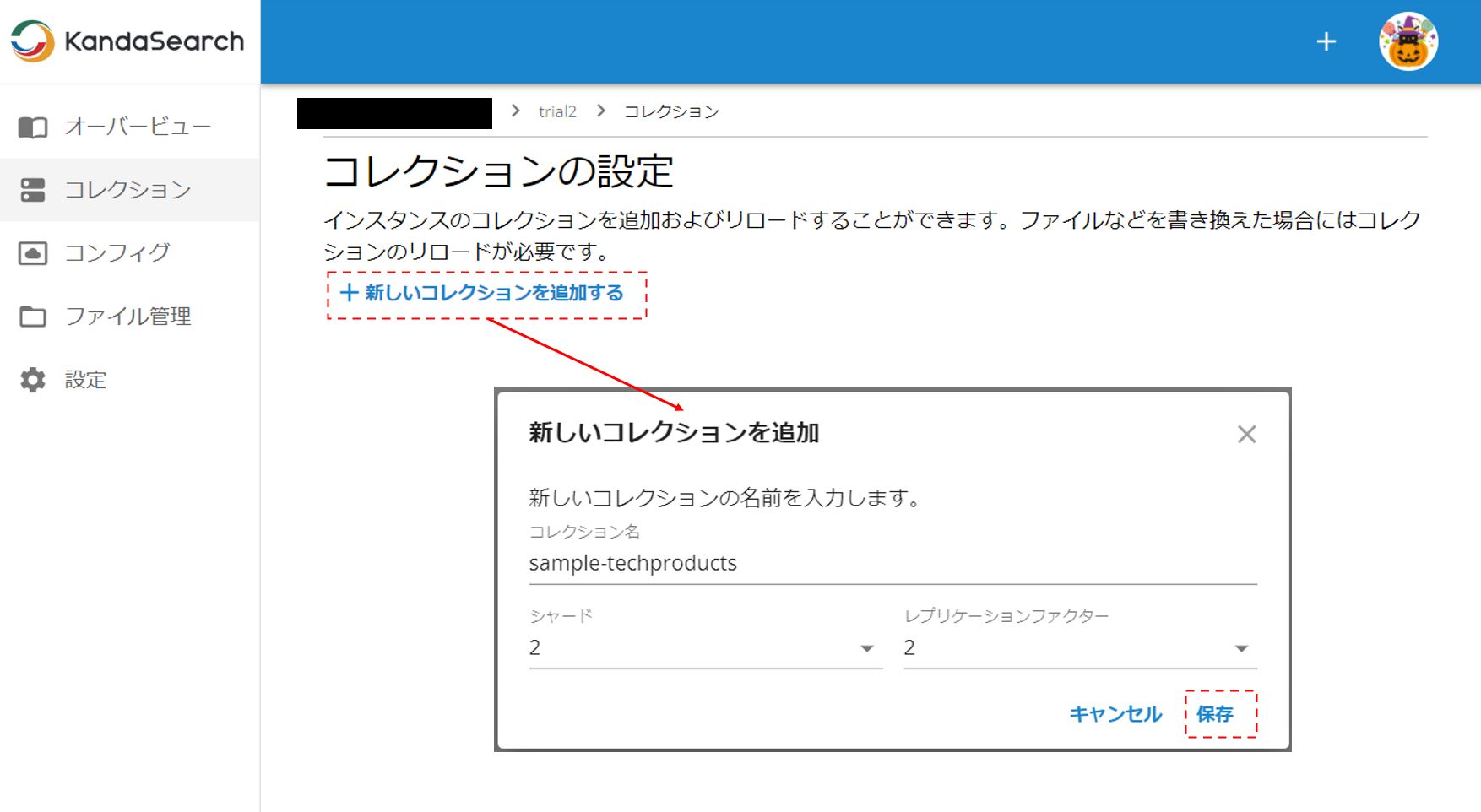
SolrCloudのコレクション設定もスタンドアロン構成とほとんど変わらないが、シャード(shard)とレプリケーションファクター(ReplicationFactor)を指定する必要がある。
シャードとはインデックスデータを分割したかけらの事であり、インデックスはここで指定したシャードの数に分割される。例えばシャードに2を指定した場合はインデックスデータはあるアルゴリズムにより2つに分割される。
また、レプリケーションファクターとはそのシャードを、複製を含めいくつ持つかということを意味する。よってレプリケーションファクターに1を指定した場合には複製は作られずオリジナルのシャードのみが存在するということになる。
例として、シャード=2、レプリケーションファクター=2を指定した場合のSolrCloud構成を以下のSolr管理画面をもって説明する。
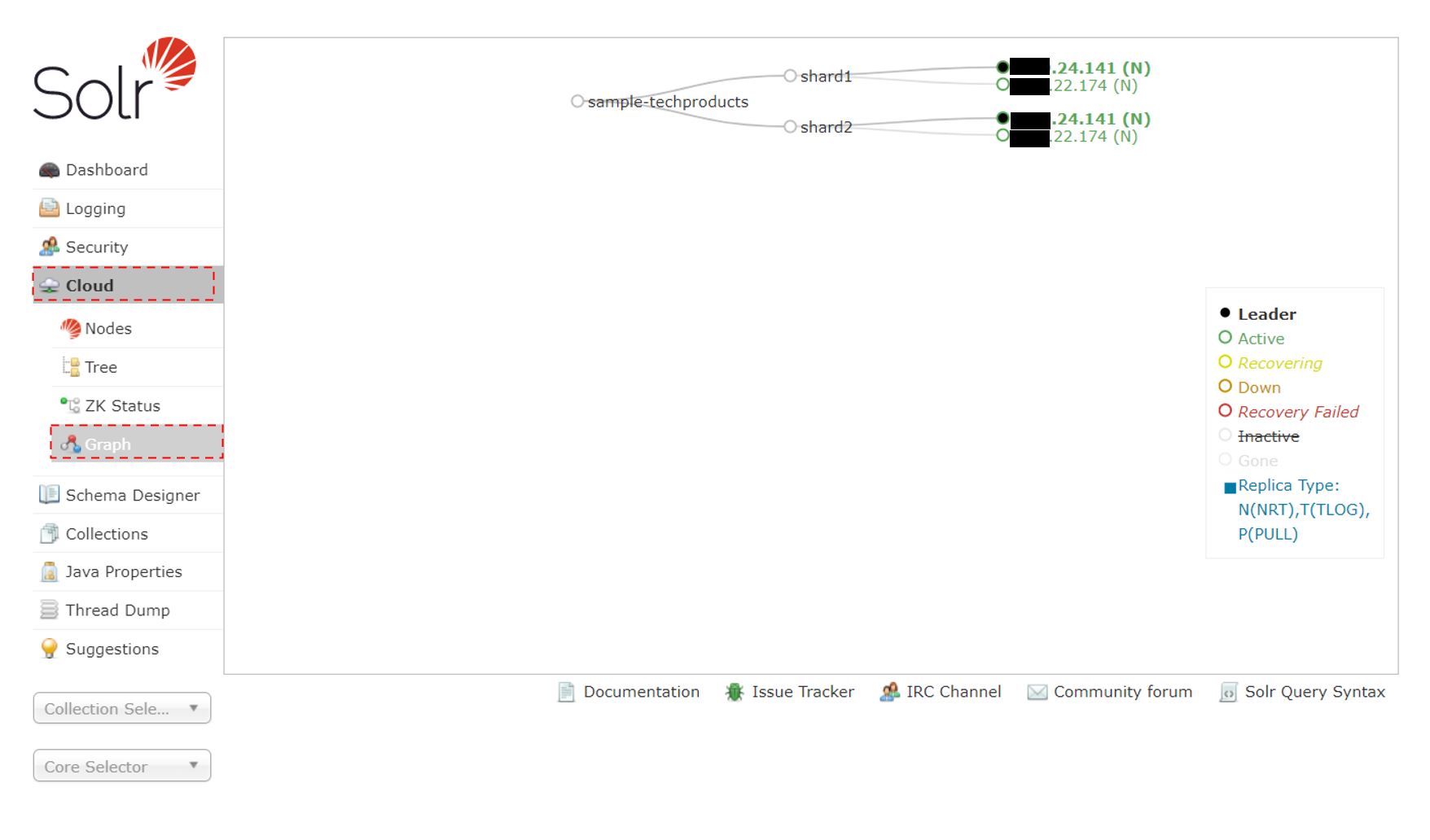
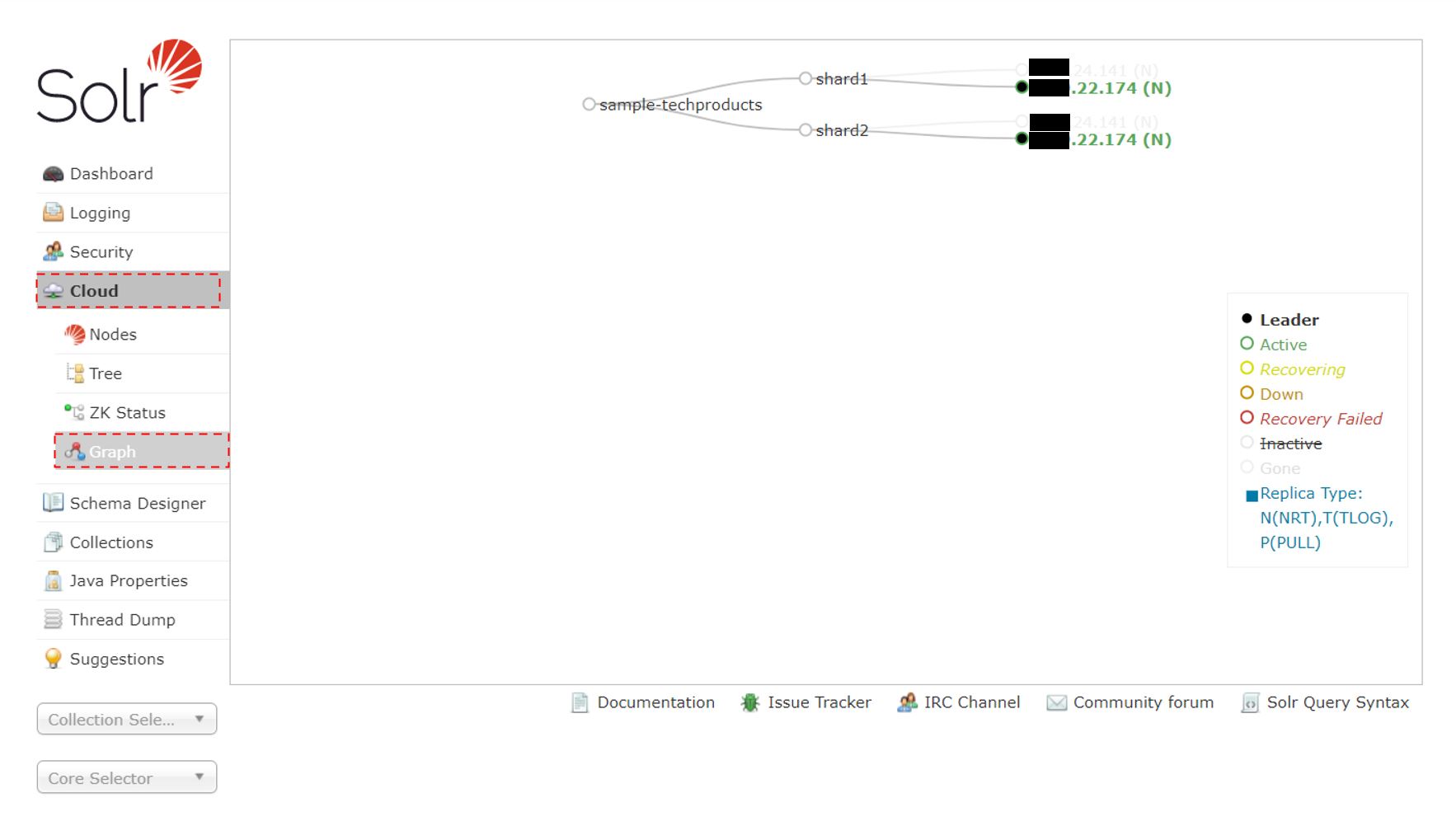
SolrCloud構成の場合は、Solr管理画面がスタンドアロン構成と異なり、左のサイドメニューバーに、”Cloud” という項目が存在する。この中にSolrCloudについての情報が色々とまとめられている。例えば”Graph” というメニュー項目を選ぶと、現在のSolrCloudの状態が図で表示される。
これによると、sample-techproductsコレクションは、2つのシャードから構成され、それぞれのshard数はレプリケーションファクターで指定した数となっている。つまりshard1は、●.●.24.141のサーバーと●.●.22.174のサーバーに(計2つ=レプリケーションファクターの数だけ)存在し、shard2も、●.●.24.141のサーバーと●.●.22.174のサーバーに(計2つ=レプリケーションファクターの数だけ)存在することがわかる。これにより一方のサーバーがダウンしても、もう片方のサーバーが生きていれば、shard1とshard2の組み合わせは存在するので、正常検索が可能であることを示している。
もし、シャードもレプリケーションファクターも共に3を指定した場合には、SolrCloud構成ではサーバーが2台ダウンしても正常検索が可能であり、高可用性、信頼性が期待できる。 但し、トライアルのSolrCloudはSmallプランのノード数2固定なので、シャードとレプリケーションファクターは最大2までしか選べないので注意して欲しい。SolrCloudの構成サーバーを止めての検索
SolrCloudのデータ登録や検索は、基本的にスタンドアロン構成の場合に準じる。スタンドアロンの時と同様の操作を行えば、何ら迷うことはないであろう。そこで今回はSolrCloudを構成しているサーバーをわざと1台止めてみて、検索が正しく行えるかを試してみる。
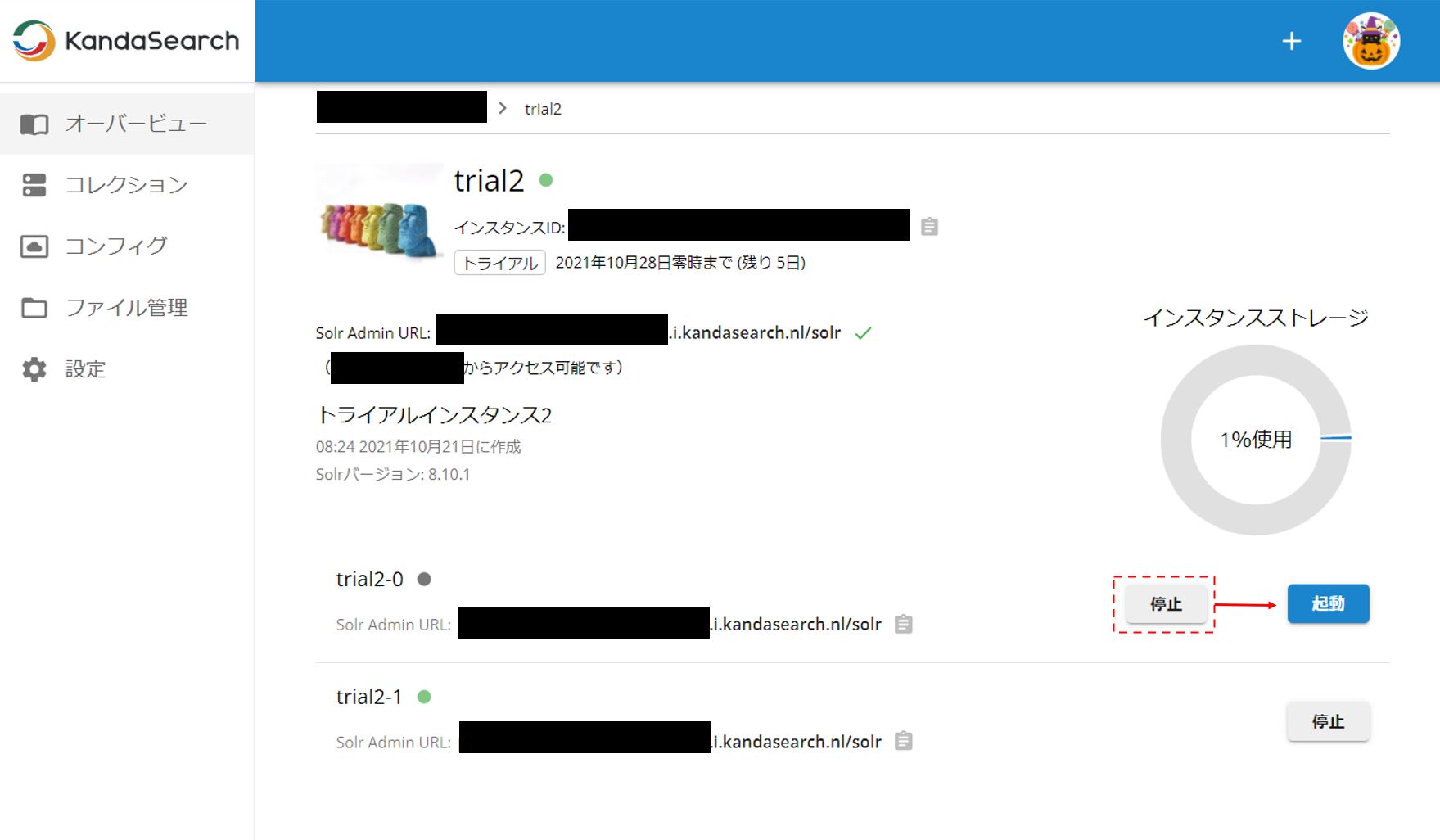
上記は、trial2-0を停止したときの画面である。「停止」をクリックするとtrial2-0の横の●がグレイになり、「停止」が「起動」に変わるので停止したことが確認できる。なお、Solr Admin URLは画面の一番上のものを使用する。(この画面では緑チェックが付いている)
Solr Admin URLをブラウザのアドレスに入れSolr管理画面よりCloudの状態図を表示したのが上の画面である。●.●.24.141のサーバーが灰色で表示され停止しているのが確認できる。 この画面と比較して欲しい。
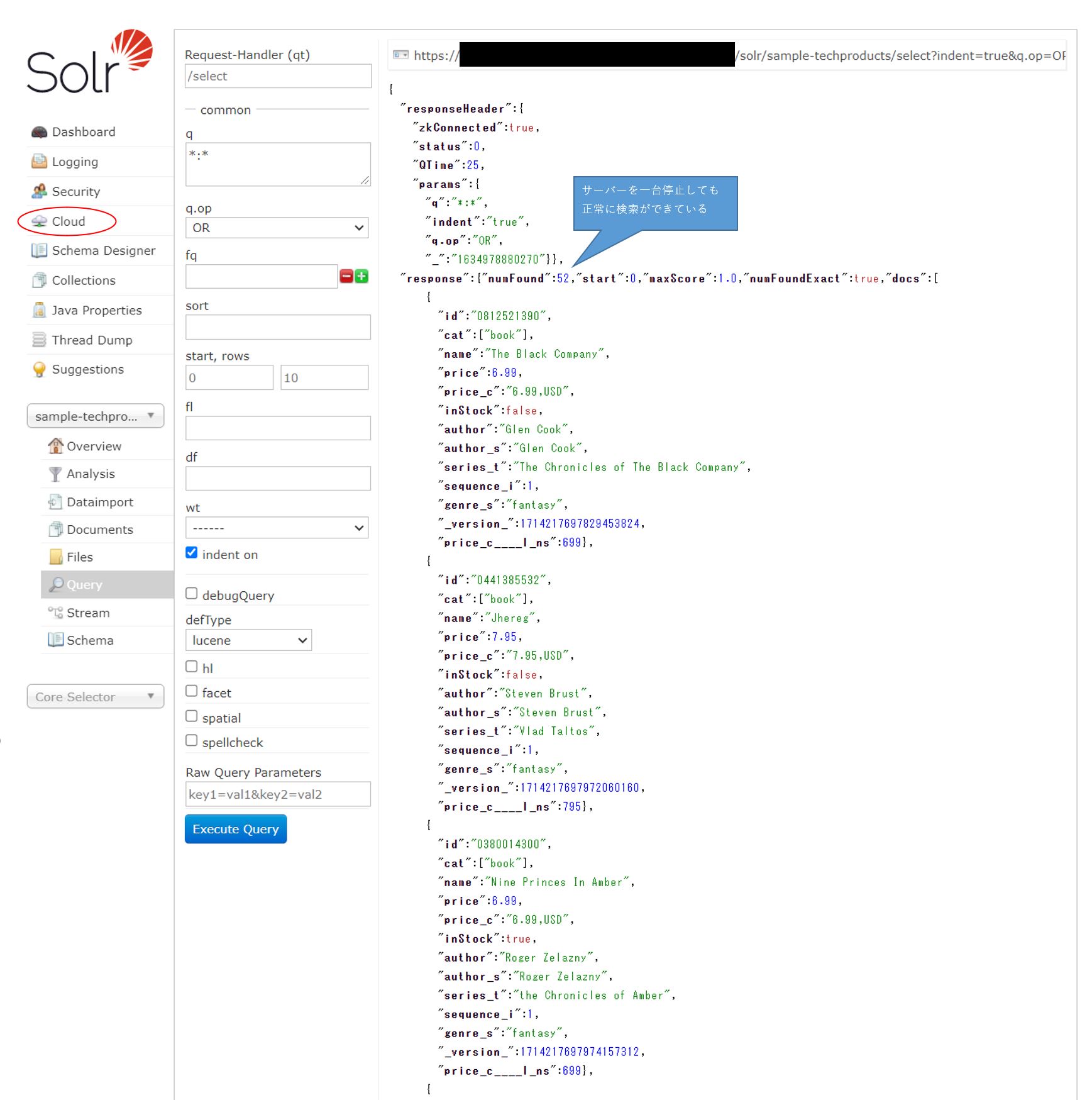
上記は全件検索の結果であるが、その他様々な検索を行ってみても、スタンドアロン構成の時と同様の結果を返すことがわかる。シャード=2、レプリケーションファクター=2のSolrCloudでは、構成サーバーが1台停止しても正常検索できることが確認できた。
なお、 インスタンスのオーバービュー画面 上に表示されているtrial2-1のSolr Admin URLを使用してSolr管理画面を立ち上げた場合にも同様の結果となる。但し、停止したtrial2-0のSolr Admin URLでは”Bad Gateway”となった。当然の結果であろう。
まとめ
今まで述べてきたように「Solrの構築が非常に簡単にできる」これがKandaSearchの特徴である。 KandaSearchは、Solrに接したことが無い人にSolrに触れることができる環境をすぐに提供する。 また、企業ユースでは必須となっているSolrCloudをほんの少しのステップで構築する事を可能とする。これは特に大きな利点である。 本来、クラウドサービス上にまっさらな状態からSolrCloudを構築するとしたら、セキュリティ設定、ネットワーク設定から始まり、SolrやZooKeeperの台数分インストール、コレクションの作成などを矛盾無きよう行わなければならない。それに加えバージョンの整合性や大部分の作業をコマンドベースで行う必要があり、SolrCloud構築作業は困難を極める。 実は、以前筆者もクラウドサービス上にSolrCloudを構築したことがあるが、その時は何回もやり直しを行う羽目になり大変な苦労を強いられた。 なお、企業ユースという点では、プロジェクト単位での管理のしやすさという事も利点の一つに挙げられるであろう。メンバーの追加/削除や本番/開発別Solr環境をプロジェクト単位で管理できることは企業ユースでは大変重宝すると思われる。 だから、初心者の方にも企業のIT部門の方にも十分なSolr環境を提供できるKandaSearchは皆様にとっても良いツールとなると感じている。
本記事がお客様の業務に少しでもお役に立てば幸いです。
著者略歴
某精密機器メーカーにてNLP業務に従事し、形態素解析器、全文検索エンジン(転置索引)、強調表示器作成を担当する。その後、音声入力による質問応答タスクの研究や多言語翻訳システムの構築等を経験。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!