INFORMATION
テクノロジ
Lucene/Solr Revolution 2017 レポートその1
9月14日、15日の日程でUSラスベガスで開催中のLucene/Solr Revolution2017に参加していますので、初日の内容を現地よりレポート致します。(記事:中山久司)

General Session
Solr Feature Deep Dive (深い機能の説明) 主に弊社西潟が参加
Solr for Business (ビジネス現場での事例) 主に中山が参加
Solr & Machine Learning (機械学習を絡めた話)

 誰でも参加できることによる広がりと、スピード感がイノベーションを起こしているのです。
保健医療分野では新しい取組みがすぐに必要で待ちきれないユーザーも多く、
ニーズに対応すべく開発が進みますし、直接的に人の役に立つことが見えやすいため、開発者のモチベーションも高いようです。
人を助けるオープン・イノベーション組織のリーダーであるDanaさんのプレゼンに対して、スタンディングオペレーションで拍手を送る参加者も見られました。
誰でも参加できることによる広がりと、スピード感がイノベーションを起こしているのです。
保健医療分野では新しい取組みがすぐに必要で待ちきれないユーザーも多く、
ニーズに対応すべく開発が進みますし、直接的に人の役に立つことが見えやすいため、開発者のモチベーションも高いようです。
人を助けるオープン・イノベーション組織のリーダーであるDanaさんのプレゼンに対して、スタンディングオペレーションで拍手を送る参加者も見られました。
 Solr導入前には、検索に対してスケーリングやカスタムインテグレーション、
チューニングなどに課題を抱えており、昨年(2016)Solrを導入しました。
Solrによりパーソナライズ、拡張、カスタムアルゴリズム、クリックストリームを利用することが可能になり、顧客行動であるクリック履歴を利用した検索結果の最適化を繰り返し実施することが有効とのこと。
商品区分によって、ファセット(絞り込み項目)が変わるのも有効に思えました。
検索結果順位の最適化とパーソナライズは相反するケースもあり、トライ&結果比較を繰り返すとのこと。
Solr導入前には、検索に対してスケーリングやカスタムインテグレーション、
チューニングなどに課題を抱えており、昨年(2016)Solrを導入しました。
Solrによりパーソナライズ、拡張、カスタムアルゴリズム、クリックストリームを利用することが可能になり、顧客行動であるクリック履歴を利用した検索結果の最適化を繰り返し実施することが有効とのこと。
商品区分によって、ファセット(絞り込み項目)が変わるのも有効に思えました。
検索結果順位の最適化とパーソナライズは相反するケースもあり、トライ&結果比較を繰り返すとのこと。
 この取組は必ずしも短期で成果が出るものではなく失敗もあるようですが、
デジタル技術へ中長期的な投資をする必要性とメリットを社内でしっかり共通認識として持つことが重要との話でした。
この取組は必ずしも短期で成果が出るものではなく失敗もあるようですが、
デジタル技術へ中長期的な投資をする必要性とメリットを社内でしっかり共通認識として持つことが重要との話でした。
 まずは、検索システムを作る時のステークホルダーを考えます。
検索を行うエンドユーザーとシステムを作成するエンジニアが大切ですが、マーケティングやビジネスマネージャーも重要です。
このカンファレンスの参加者の多くはエンジニア・プログラマーのため、マネージャー、マーケティング、ユーザーがどのような視点で検索システムに期待/評価をするかを個別にみていきました。
簡単にいえば各社の評価基準は、マネージャーは売上額であり、マーケティングはコンバージョンレートや検索されたワードと検索結果、ユーザーはレスポンスと欲しいものが表示されるかです。
彼らのニーズを把握するためにしっかりコミニュケーションをとってよい検索システムを構築・作成するのがエンジニアの仕事となります。
”バイクタイヤ”と検索した時、ロサンゼルスではロードバイク用のタイヤが、
テキサスではマウンテンバイクのタイヤがでるのがよいという例を示していました。
まずは、検索システムを作る時のステークホルダーを考えます。
検索を行うエンドユーザーとシステムを作成するエンジニアが大切ですが、マーケティングやビジネスマネージャーも重要です。
このカンファレンスの参加者の多くはエンジニア・プログラマーのため、マネージャー、マーケティング、ユーザーがどのような視点で検索システムに期待/評価をするかを個別にみていきました。
簡単にいえば各社の評価基準は、マネージャーは売上額であり、マーケティングはコンバージョンレートや検索されたワードと検索結果、ユーザーはレスポンスと欲しいものが表示されるかです。
彼らのニーズを把握するためにしっかりコミニュケーションをとってよい検索システムを構築・作成するのがエンジニアの仕事となります。
”バイクタイヤ”と検索した時、ロサンゼルスではロードバイク用のタイヤが、
テキサスではマウンテンバイクのタイヤがでるのがよいという例を示していました。
 この会社は10年のSolr利用・運用経験があり、高度にカスタマイズしています。
開発したクエリパーサーとして、Bmax Query Parser, Querqyなどがあります。
検索をコンテキストに分けたがる人やサイトも見られますが、ユーザー視点でも検索エンジン視点でもコンテキストレスがよいとのこと。
また、パーソナライズは非常に重要です。彼は大きめのTシャツとダークカラーのジーンズが好みで、それ以外が検索結果に出るのはよくないと考えているようです。
この会社は10年のSolr利用・運用経験があり、高度にカスタマイズしています。
開発したクエリパーサーとして、Bmax Query Parser, Querqyなどがあります。
検索をコンテキストに分けたがる人やサイトも見られますが、ユーザー視点でも検索エンジン視点でもコンテキストレスがよいとのこと。
また、パーソナライズは非常に重要です。彼は大きめのTシャツとダークカラーのジーンズが好みで、それ以外が検索結果に出るのはよくないと考えているようです。
 基盤はGCP(Google Cloud Platform)上で動作し、運用を極力自動化できるように配慮されています。そのためにGo言語で作成されたZookeeperのプラグインを利用し、同じくGo言語で新たに自社内でSolr向けのパッケージを作成しているとのこと。
Solrは安定した基盤ソフトですがニーズによって周辺を追加開発しやすいので、エンジニアにとって使いやすい製品だと思います。
基盤はGCP(Google Cloud Platform)上で動作し、運用を極力自動化できるように配慮されています。そのためにGo言語で作成されたZookeeperのプラグインを利用し、同じくGo言語で新たに自社内でSolr向けのパッケージを作成しているとのこと。
Solrは安定した基盤ソフトですがニーズによって周辺を追加開発しやすいので、エンジニアにとって使いやすい製品だと思います。
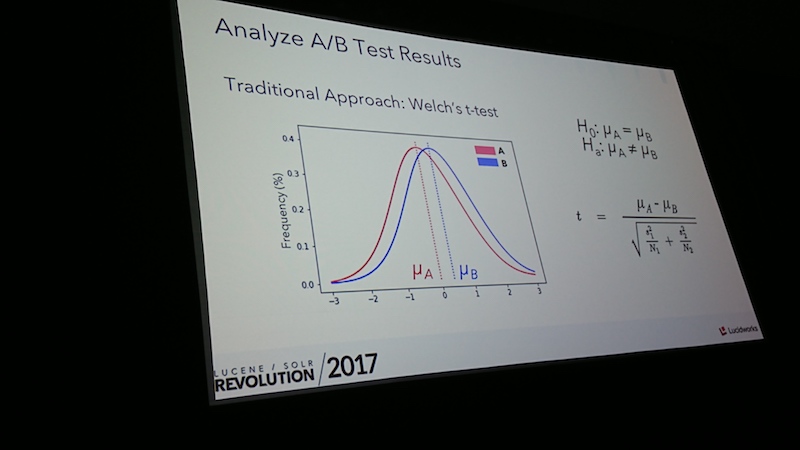
 Tracyに交代し、ABテストプログラムについて数学的見地から見直しをする話がありました。
ユーザーのクリック動作は標準分布に従わないため、広範囲なシミュレーションを行い2-4週間毎にABテストの結果を評価する地道なアプローチです。
テスト結果の評価にも数学の式がでてきます。
(100kクリックに3週間)
Tracyに交代し、ABテストプログラムについて数学的見地から見直しをする話がありました。
ユーザーのクリック動作は標準分布に従わないため、広範囲なシミュレーションを行い2-4週間毎にABテストの結果を評価する地道なアプローチです。
テスト結果の評価にも数学の式がでてきます。
(100kクリックに3週間)
 検索にもデータアナリスト(ソフトウェアやプログラミングに加えて統計の知識を持つ技術職)が必要であることがよくわかります。日本では人材不足が顕著化していると思いますので、有償でもセミナーやトレーニングへの参加を積極的に推進して人材育成が必要と思います。海外出張が難しい場合は、ぜひロンウイットのセミナー、トレーニングにご参加下さい。
検索にもデータアナリスト(ソフトウェアやプログラミングに加えて統計の知識を持つ技術職)が必要であることがよくわかります。日本では人材不足が顕著化していると思いますので、有償でもセミナーやトレーニングへの参加を積極的に推進して人材育成が必要と思います。海外出張が難しい場合は、ぜひロンウイットのセミナー、トレーニングにご参加下さい。
 次に登壇したKhalid Imamが多くの要素からなるCISCOの検索システムについて話しました。
次に登壇したKhalid Imamが多くの要素からなるCISCOの検索システムについて話しました。
会場
今回の会場はラスベガスのホテル、マンダレイ・ベイです。 ラスベガスにはイベント開催できる大きなホテルが沢山ありますが、その中でも12000人収容の屋内アリーナも持つ最大規模のホテルで、金色に輝いています。私の部屋から会場まで徒歩10分程度かかり、迷子になりそうでした。
全体構成
朝一番と最後に全体セッションがありますが、他は5つのブレークアウトセッションに分かれています。 分類は主に以下です。OpeningRemarks
開催ホストのLucidworks社CEOからAgendaの紹介と自社宣伝がありました。
KeyNote: #WeAreNotWaiting: Using Open Source to Change Healthcare Dana Lewis, OpenAPS
Open APSは保健医療分野でオープンソースソフトウェアを活用する取組みを行っている非営利組織です。 もちろんこの分野でも様々な企業が独自製品を展開しているのですが、オープンソースによってコアとなるソフトウェアができると、各種のデバイスに接続したり機能追加するモジュールを開発する人がでてきます。
誰でも参加できることによる広がりと、スピード感がイノベーションを起こしているのです。
保健医療分野では新しい取組みがすぐに必要で待ちきれないユーザーも多く、
ニーズに対応すべく開発が進みますし、直接的に人の役に立つことが見えやすいため、開発者のモチベーションも高いようです。
人を助けるオープン・イノベーション組織のリーダーであるDanaさんのプレゼンに対して、スタンディングオペレーションで拍手を送る参加者も見られました。
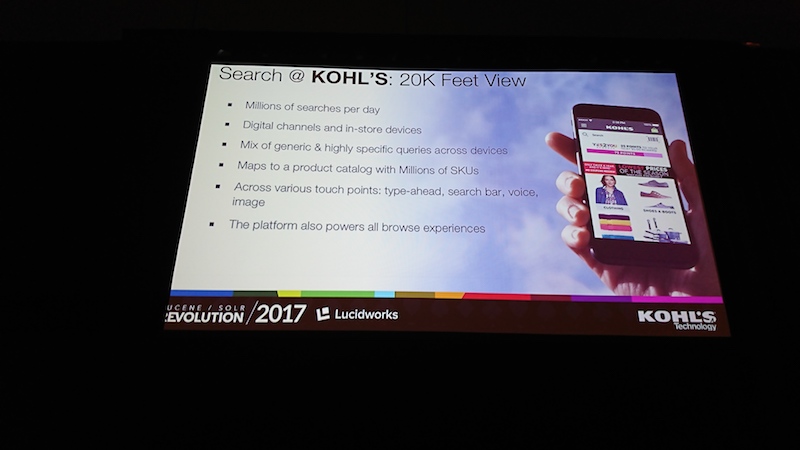
Search Evolution at Kohl’s – Machine Learning and Personalization
kohls社は全米で1,000店舗以上展開し、リーズナブルな価格が魅力のアパレルやインテリアなどを扱うデパートで、IT組織はシリコンバレーに250名のスタッフがいます。パーソナライゼーション(個人毎に履歴や行動を分析して、好みの商品をお奨めするなど)に力をいれてWebのトップページから顧客ごとに変わるという最新の試みで注目を集める企業です。
Solr導入前には、検索に対してスケーリングやカスタムインテグレーション、
チューニングなどに課題を抱えており、昨年(2016)Solrを導入しました。
Solrによりパーソナライズ、拡張、カスタムアルゴリズム、クリックストリームを利用することが可能になり、顧客行動であるクリック履歴を利用した検索結果の最適化を繰り返し実施することが有効とのこと。
商品区分によって、ファセット(絞り込み項目)が変わるのも有効に思えました。
検索結果順位の最適化とパーソナライズは相反するケースもあり、トライ&結果比較を繰り返すとのこと。
この取組は必ずしも短期で成果が出るものではなく失敗もあるようですが、
デジタル技術へ中長期的な投資をする必要性とメリットを社内でしっかり共通認識として持つことが重要との話でした。
Search as a Force Multiplier: Measuring Search Success for Key Stakeholders
RedHatの検索担当マネージャーJP Shermanは検索、検出や競合分析に15年の経験を持ち、RedHat社の顧客ポータルサイトを担当しています。 自社サイトの検索とGoogleとの違いをユーザーセグメントごとに認識し、よりよい検索とは何かを追求しています。
まずは、検索システムを作る時のステークホルダーを考えます。
検索を行うエンドユーザーとシステムを作成するエンジニアが大切ですが、マーケティングやビジネスマネージャーも重要です。
このカンファレンスの参加者の多くはエンジニア・プログラマーのため、マネージャー、マーケティング、ユーザーがどのような視点で検索システムに期待/評価をするかを個別にみていきました。
簡単にいえば各社の評価基準は、マネージャーは売上額であり、マーケティングはコンバージョンレートや検索されたワードと検索結果、ユーザーはレスポンスと欲しいものが表示されるかです。
彼らのニーズを把握するためにしっかりコミニュケーションをとってよい検索システムを構築・作成するのがエンジニアの仕事となります。
”バイクタイヤ”と検索した時、ロサンゼルスではロードバイク用のタイヤが、
テキサスではマウンテンバイクのタイヤがでるのがよいという例を示していました。
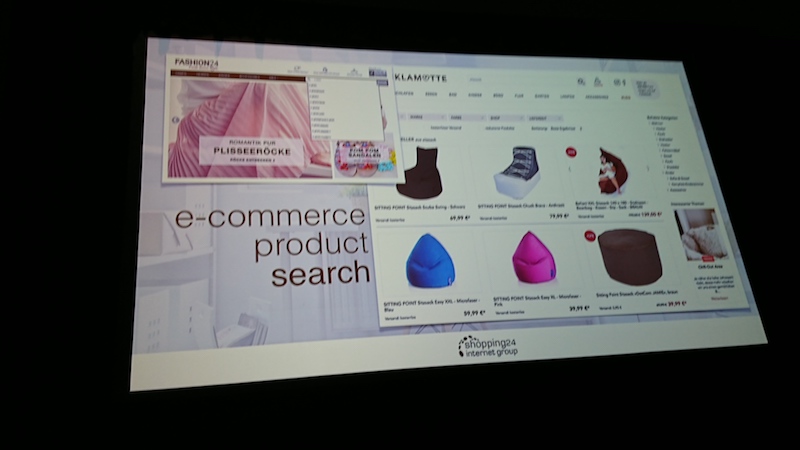
Context Driven Search Ranking and Faceting
ECサイトShopping24でCTOを務めるドイツから参加したTorsten Bøgh Kösterがコンテキストドリブンのランキングとファセットについて語りました。 彼はいくつかのSolrのプラグインを開発保守しており、ECサイトは商品数6千万点以上です。
この会社は10年のSolr利用・運用経験があり、高度にカスタマイズしています。
開発したクエリパーサーとして、Bmax Query Parser, Querqyなどがあります。
検索をコンテキストに分けたがる人やサイトも見られますが、ユーザー視点でも検索エンジン視点でもコンテキストレスがよいとのこと。
また、パーソナライズは非常に重要です。彼は大きめのTシャツとダークカラーのジーンズが好みで、それ以外が検索結果に出るのはよくないと考えているようです。
ランチ
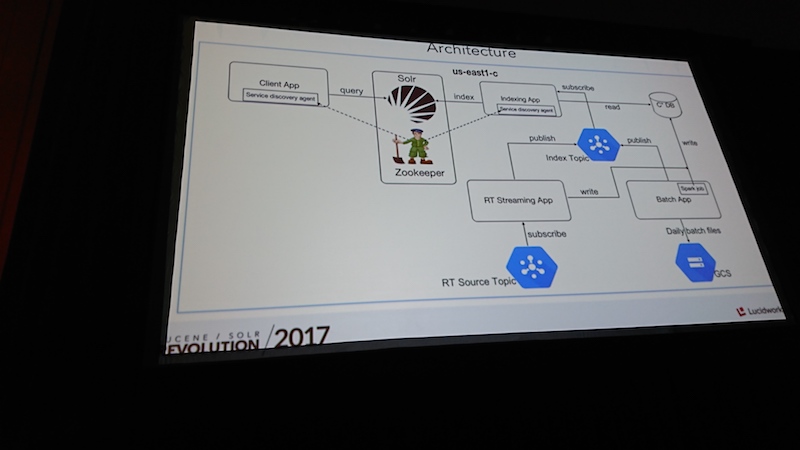
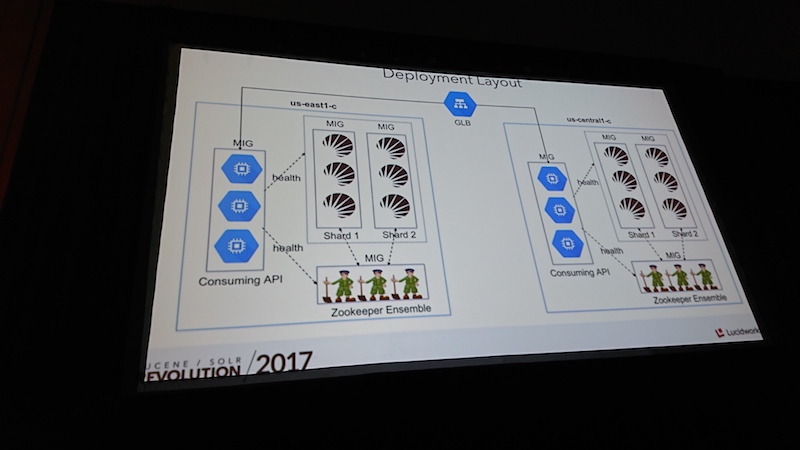
イベントでは定番となっているバイキング形式で、好きなものを自分でピックアップすればよいのでわかりやすいですネ。 チキンが美味しかったです。Running a Highly Available and Scalable Solr Platform in the Cloud at The Home Depot
The Home Depotはジョージア州に本社を持つアメリカ最大の住宅リフォーム・建設資材・サービスの小売チェーンで、アメリカ、カナダ、メキシコ、中国に2100店舗以上を展開しています。 登壇したNavin AnandarajとIlamgumaran Velayuthan Karunanithiは検索プラットホームを担当し、Solrを高可用性かつスケーラブルな構成にすべく取り組んできました。
基盤はGCP(Google Cloud Platform)上で動作し、運用を極力自動化できるように配慮されています。そのためにGo言語で作成されたZookeeperのプラグインを利用し、同じくGo言語で新たに自社内でSolr向けのパッケージを作成しているとのこと。
Solrは安定した基盤ソフトですがニーズによって周辺を追加開発しやすいので、エンジニアにとって使いやすい製品だと思います。
Learning to Rank from Clicks
Salesforce.comのサービス&サーチチームに所属するデータサイエンティスト Zach AlexanderとTracy BackesがSlaesforceの機械学習を利用した検索機能向上の裏で動く仕組みについて話しました。 Salesforceは1日に10億回以上の検索をSolrで捌いています。 信頼性が一番重要です。 はじめに、検索結果順位付けに対する新しいアプローチ方法について。 これまでは大量のラベル付データを基にしていましたが、人が検索で入力した値(とSolrが返す結果)を重視する必要がありました。 Salesforceでは新しい機械学習のアプローチを開発し、ラベル付データを不要としました。 特定フィールドをブーストしたりはしていません。RMRRを利用しています。 クリックされた結果がより必要とされたと判断し、計算式を設定してrelevanceのモデルをつくります。オフライン検証を行い有効性を確認しました。
Tracyに交代し、ABテストプログラムについて数学的見地から見直しをする話がありました。
ユーザーのクリック動作は標準分布に従わないため、広範囲なシミュレーションを行い2-4週間毎にABテストの結果を評価する地道なアプローチです。
テスト結果の評価にも数学の式がでてきます。
(100kクリックに3週間)
検索にもデータアナリスト(ソフトウェアやプログラミングに加えて統計の知識を持つ技術職)が必要であることがよくわかります。日本では人材不足が顕著化していると思いますので、有償でもセミナーやトレーニングへの参加を積極的に推進して人材育成が必要と思います。海外出張が難しい場合は、ぜひロンウイットのセミナー、トレーニングにご参加下さい。
Solr for Enterprise Channels Business
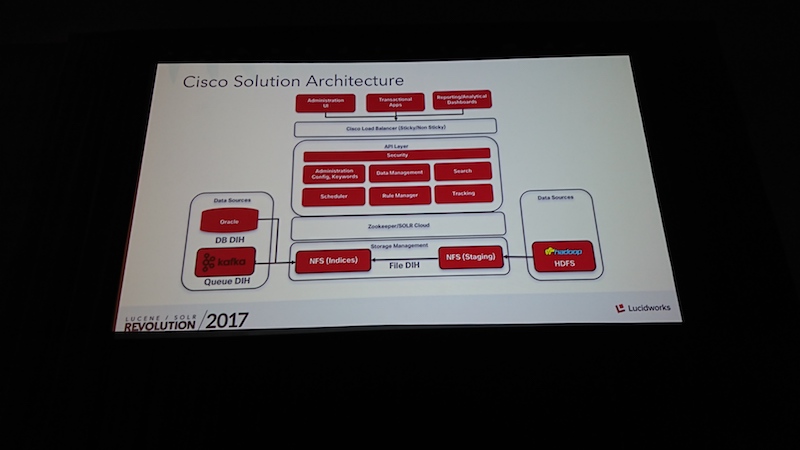
時間、スピード、パフォーマンス、フレームワーク、 現代の世の中で重要な要素はいろいろあります。 このセッションでは、CISCOが利用している複雑に絡み合うテクノロジー(Hadoop,java,solr,oracle)をどのように活用していくのかについて、話が進めていました。最初に登壇したSrini Samudralaは基盤担当のシニアアーキテクト。CISCOのビジネスの80%は代理店モデルでWebサイトも代理店モデルを考慮して検索を考える必要があります。
次に登壇したKhalid Imamが多くの要素からなるCISCOの検索システムについて話しました。
全体の印象
登壇者はインド系エンジニアが多いです。アジア系は参加者も少なめですが、YahooJapanとHitachiSolutionsの二社がスポンサーになっているのが頼もしかったです。 日本では他社様向けにSolrのトレーニングやコンサルティングをビジネスで実施している会社はとても少ないですが、ご要望がありましたらぜひロンウイットまでお知らせ下さい。 2日目のレポートも発信させて頂きますので、よろしければご参照下さい。INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!