INFORMATION
サービス
Lucene/Solr Revolution 2017レポート その2
9月14日、15日の日程でUSラスベガスで開催中のLucene/Solr Revolution2017に参加していますので、2日目の内容を現地よりレポート致します。(記事:中山久司)


 はじめに技術担当VPのNickCaldwellが会社の紹介をしました。Redditは全米No4のアクセス数を誇るサイトです。
次にCTOのChrisSloweにバトンを渡し、実際のシステムについての話があり、
はじめに技術担当VPのNickCaldwellが会社の紹介をしました。Redditは全米No4のアクセス数を誇るサイトです。
次にCTOのChrisSloweにバトンを渡し、実際のシステムについての話があり、
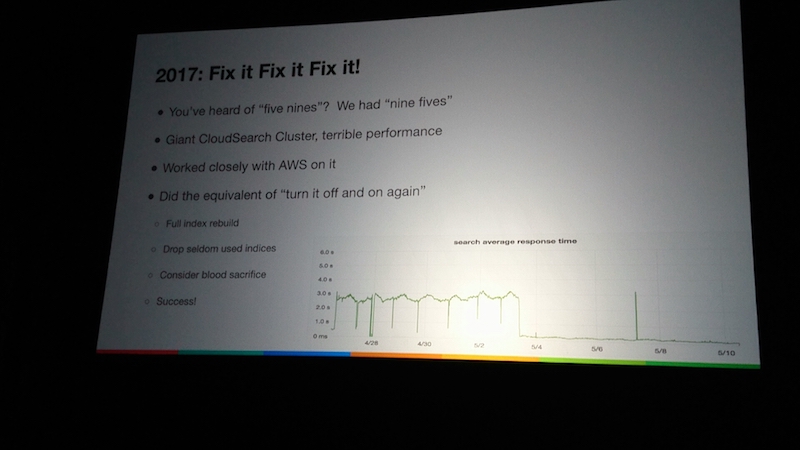 さらに検索担当シニアディレクターのLuis Bitencourt-Emilioが登壇。
検索のこれまでの課題と解決した内容を話しました。
さらに検索担当シニアディレクターのLuis Bitencourt-Emilioが登壇。
検索のこれまでの課題と解決した内容を話しました。
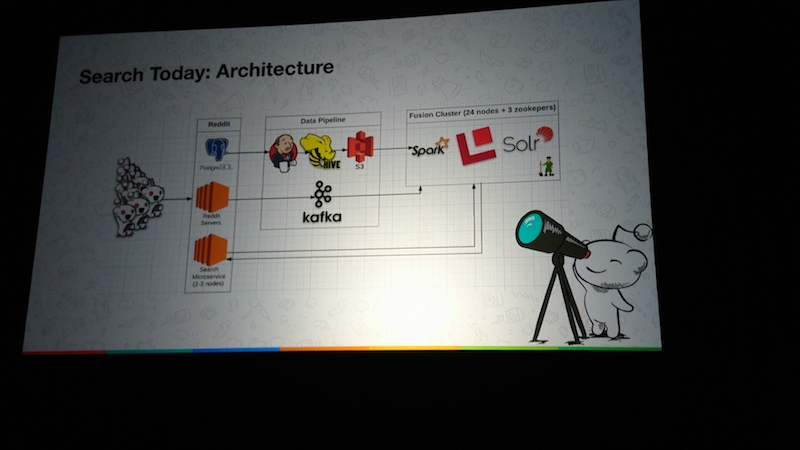 彼らの次のチャレンジはパーソナライズになりそうです。
彼らの次のチャレンジはパーソナライズになりそうです。
 beeと honeyは日本語では蜂と蜂蜜なので関連すると判断できますが、(彼女の趣味は養蜂です)英語ではどのように判断すればよいでしょうか?
基本的な考え方は beeとhoneyがよく一緒にコーパス(今回の例ではtwitterのつぶやき文)に出現することを機械学習させて利用するというものです。
beeと honeyは日本語では蜂と蜂蜜なので関連すると判断できますが、(彼女の趣味は養蜂です)英語ではどのように判断すればよいでしょうか?
基本的な考え方は beeとhoneyがよく一緒にコーパス(今回の例ではtwitterのつぶやき文)に出現することを機械学習させて利用するというものです。
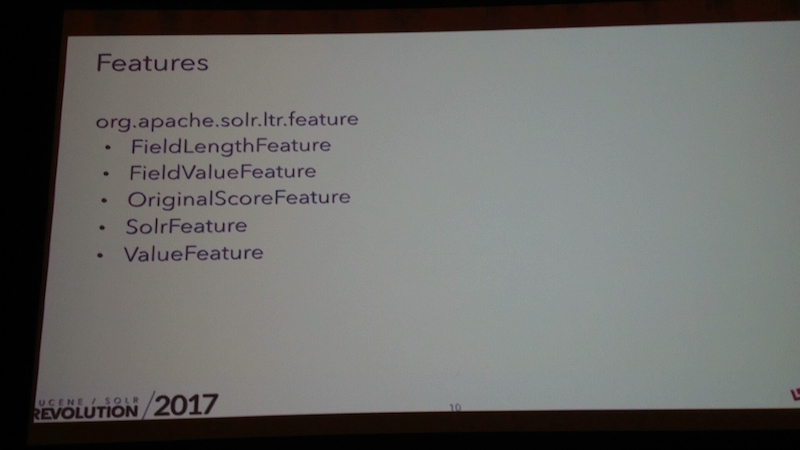 彼女が開発したLTR機能は最新のSolr6.6.1にプラグインとして含まれており、デモもGithubで公開されています。
LTR機能を活用するには、検索技術者の支援が必要になります。
ロンウイットでもLTRを独自実装したSolrサブスクリプションをサポート付きで提供していますので、ぜひお問い合わせ下さい。
彼女が開発したLTR機能は最新のSolr6.6.1にプラグインとして含まれており、デモもGithubで公開されています。
LTR機能を活用するには、検索技術者の支援が必要になります。
ロンウイットでもLTRを独自実装したSolrサブスクリプションをサポート付きで提供していますので、ぜひお問い合わせ下さい。
 このサイトでは日々追加されるインターネット上の動画や音声のコンテンツに対してレイティングやリコメンドを実施しています。
FindLectures.comではカンファレンスサイトをクロールし、出演者の名前や経歴説明文や日付などのメタデータを入手してリコメンドを試みますが、これらのデータはサイトを跨っていたり欠損していたりします。
Solrのような全文検索エンジン向けに、より洗練された方法はないものでしょうか? このセッションではクロールで蓄積された動画を利用し機械学習によって情報を取り出す仕組みを知ることができ、検索エンジンと共に利用するヒントを得ました。
このサイトでは日々追加されるインターネット上の動画や音声のコンテンツに対してレイティングやリコメンドを実施しています。
FindLectures.comではカンファレンスサイトをクロールし、出演者の名前や経歴説明文や日付などのメタデータを入手してリコメンドを試みますが、これらのデータはサイトを跨っていたり欠損していたりします。
Solrのような全文検索エンジン向けに、より洗練された方法はないものでしょうか? このセッションではクロールで蓄積された動画を利用し機械学習によって情報を取り出す仕組みを知ることができ、検索エンジンと共に利用するヒントを得ました。


 TF-IDF,norm などのSolrを含む検索の世界での基本知識となる数式の説明があり、Solr6からTF-IDFに代わってデフォルトになったBM25を解説。
Edismaxについても説明があり、 基本をわかった上でテスト環境、本番環境で実施・評価することを推奨していました。
TF-IDF,norm などのSolrを含む検索の世界での基本知識となる数式の説明があり、Solr6からTF-IDFに代わってデフォルトになったBM25を解説。
Edismaxについても説明があり、 基本をわかった上でテスト環境、本番環境で実施・評価することを推奨していました。
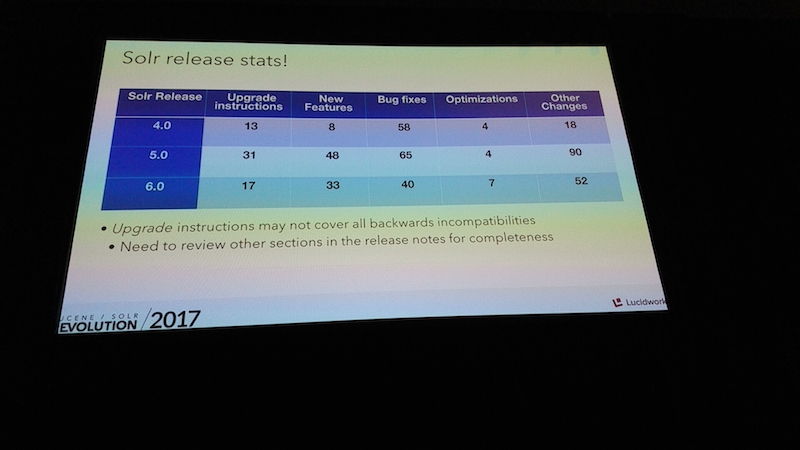
 大企業において広く使われているにも関わらず、Solrには自動バージョンアップのツールが備わっていません。ユーザー企業にとって、Solrのバージョンアップを実施することは厄介な仕事です。各バージョンのリリースノートをしっかり読み、互換性がない部分がどこかそれが自分達のシステムにどのように影響するかを予想し、実際にテスト確認をする必要があるからです。
加えて、既存のINDEXデータを新しいバージョンに適応させる必要がありますが、index upgradeを行うか生データから再度indexingするかの選択も必要です。
Solrに限らず、安定稼働しているシステムのバージョンアップは新機能が有効とみなされない限りなかなか踏み切れない企業もあるようです。実際にバージョンアップ作業は煩わしくミスも発生しやすいものです。
このセッションでは、典型的なバージョンアップ作業でよく見られる課題と解決策について議論されました。
大企業において広く使われているにも関わらず、Solrには自動バージョンアップのツールが備わっていません。ユーザー企業にとって、Solrのバージョンアップを実施することは厄介な仕事です。各バージョンのリリースノートをしっかり読み、互換性がない部分がどこかそれが自分達のシステムにどのように影響するかを予想し、実際にテスト確認をする必要があるからです。
加えて、既存のINDEXデータを新しいバージョンに適応させる必要がありますが、index upgradeを行うか生データから再度indexingするかの選択も必要です。
Solrに限らず、安定稼働しているシステムのバージョンアップは新機能が有効とみなされない限りなかなか踏み切れない企業もあるようです。実際にバージョンアップ作業は煩わしくミスも発生しやすいものです。
このセッションでは、典型的なバージョンアップ作業でよく見られる課題と解決策について議論されました。
 基本的にはデータはきっちりバックアップしリカバーできるように常に実施しておき、メジャーバージョンアップには追従するのがおすすめで、2つ遅れたら再構築がよさそうです。
実施時はリリースノートやJIRAの情報に気を配り、可能であれば経験者の支援を受けるのがよいでしょう。
最後に彼が作成しているツールのデモも行われました。
(Githubに公開されているので、参加して欲しいとのこと)
基本的にはデータはきっちりバックアップしリカバーできるように常に実施しておき、メジャーバージョンアップには追従するのがおすすめで、2つ遅れたら再構築がよさそうです。
実施時はリリースノートやJIRAの情報に気を配り、可能であれば経験者の支援を受けるのがよいでしょう。
最後に彼が作成しているツールのデモも行われました。
(Githubに公開されているので、参加して欲しいとのこと)

 プロダクトマネージャーのMayank Gupta検索担当エンジニアリングマネージャーのGopal Patwaが登壇。
機械学習の力によってユーザーがいかに自分の希望にあったイベントを見つけやすくなったか、NLPやランキングアルゴリズムの話を行っていました。
プロダクトマネージャーのMayank Gupta検索担当エンジニアリングマネージャーのGopal Patwaが登壇。
機械学習の力によってユーザーがいかに自分の希望にあったイベントを見つけやすくなったか、NLPやランキングアルゴリズムの話を行っていました。
 彼がエンジニア達に熱く語ったメッセージの一部は以下です。
彼がエンジニア達に熱く語ったメッセージの一部は以下です。
Easy to Use
5分でダウンロードしてサンプルを使えて動くのを見せられるように、1時間で自分のデータを入れられるように、1日でより深く理解し、1週間でテストや検証を終えられるようにすることが製品選定に残るために必要
ドキュメントも絶対必要、重要
うまく構成し、図や表などを含めましょう
大変なこともあるけど、パッションを持って取り組む
 一方で、10年でハードもRDBもNoSQLもSolrも進化したので、複雑化かつ高機能化してどれを選んでソリューションを組むのかは難しくなってるかもしれません。
ただ、大規模Webサイトや先端企業は今回の事例のようにSolrを選んでいますし、多くのエンジニアを世界中から集めるLucene/Solrはこれからも成長を続けると感じました。
一方で、10年でハードもRDBもNoSQLもSolrも進化したので、複雑化かつ高機能化してどれを選んでソリューションを組むのかは難しくなってるかもしれません。
ただ、大規模Webサイトや先端企業は今回の事例のようにSolrを選んでいますし、多くのエンジニアを世界中から集めるLucene/Solrはこれからも成長を続けると感じました。
 写真では表現できない絶景で、行って良かった世界遺産ランキングのトップになるだけのことはありますネ。
毎年海外出張に行けて、オフも取りやすいのが弊社の特徴です!
写真では表現できない絶景で、行って良かった世界遺産ランキングのトップになるだけのことはありますネ。
毎年海外出張に行けて、オフも取りやすいのが弊社の特徴です!
OpeningRemarks
開催ホストのLucidworks社エンジニアリングSVPのから本日のAgendaの紹介とSolr7や自社製品Fusionの紹介がありました。
KeyNote1:Vegas.com
ラスベガスを紹介する旅行サイトであるVegas.comのディレクターで18年の経験を持つPaulMelloがWebサイト開発やマーケティング、製品ベンダー選択について話しました。
KeyNote2:The Search for Better Search at Reddit
Redditはウェブサイトへのリンクを収集・公開するソーシャルブックマークサイトであり、ニュース記事、画像などの紹介や感想募集のトピックを誰でも立てられるソーシャルニュースサイトであり、電子掲示板で、会社は2005年に設立されました。 コンテンツはユーザーの投票によってランク付けが行われ、表示はランク順となります。
はじめに技術担当VPのNickCaldwellが会社の紹介をしました。Redditは全米No4のアクセス数を誇るサイトです。
次にCTOのChrisSloweにバトンを渡し、実際のシステムについての話があり、
さらに検索担当シニアディレクターのLuis Bitencourt-Emilioが登壇。
検索のこれまでの課題と解決した内容を話しました。
彼らの次のチャレンジはパーソナライズになりそうです。
Learning-to-Rank with Apache Solr and Bees
ドイツ出身、UK在住のBloombergの検索インフラチームに所属するソフトウェア開発者でありLucene/Solrコミッター&PMCのChristine Poerschke(PhD)が機械学習を利用したSolrのランキング学習について話します。
beeと honeyは日本語では蜂と蜂蜜なので関連すると判断できますが、(彼女の趣味は養蜂です)英語ではどのように判断すればよいでしょうか?
基本的な考え方は beeとhoneyがよく一緒にコーパス(今回の例ではtwitterのつぶやき文)に出現することを機械学習させて利用するというものです。
彼女が開発したLTR機能は最新のSolr6.6.1にプラグインとして含まれており、デモもGithubで公開されています。
LTR機能を活用するには、検索技術者の支援が必要になります。
ロンウイットでもLTRを独自実装したSolrサブスクリプションをサポート付きで提供していますので、ぜひお問い合わせ下さい。
Indexing Videos in Solr
FindLectures.comは技術や歴史の話題、学術系講義を提供するサイトで、発表者のGary SielingはWingspan Technologyのソフトウェアアーキテクトです。
このサイトでは日々追加されるインターネット上の動画や音声のコンテンツに対してレイティングやリコメンドを実施しています。
FindLectures.comではカンファレンスサイトをクロールし、出演者の名前や経歴説明文や日付などのメタデータを入手してリコメンドを試みますが、これらのデータはサイトを跨っていたり欠損していたりします。
Solrのような全文検索エンジン向けに、より洗練された方法はないものでしょうか? このセッションではクロールで蓄積された動画を利用し機械学習によって情報を取り出す仕組みを知ることができ、検索エンジンと共に利用するヒントを得ました。
ランチ
ランチは昨日と同じ形式でサラダとチキンという内容です。 美味しく頂きました。(食べかけの写真ですみません)
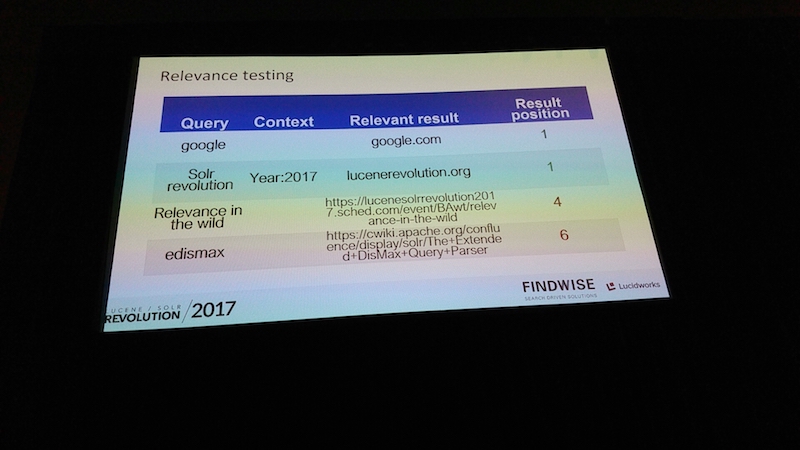
Relevance in the Wild
ストックホルムから来たコンサルティング会社FindwiseのDaniel Gomez Villanuevaが検索結果の妥当性の話をしました。
TF-IDF,norm などのSolrを含む検索の世界での基本知識となる数式の説明があり、Solr6からTF-IDFに代わってデフォルトになったBM25を解説。
Edismaxについても説明があり、 基本をわかった上でテスト環境、本番環境で実施・評価することを推奨していました。
Apache Solr: Upgrading Your Upgrade Experience
Cloudera社のエンジニアHrishikesh GadreがSolrのバージョンアップについて話しました。
大企業において広く使われているにも関わらず、Solrには自動バージョンアップのツールが備わっていません。ユーザー企業にとって、Solrのバージョンアップを実施することは厄介な仕事です。各バージョンのリリースノートをしっかり読み、互換性がない部分がどこかそれが自分達のシステムにどのように影響するかを予想し、実際にテスト確認をする必要があるからです。
加えて、既存のINDEXデータを新しいバージョンに適応させる必要がありますが、index upgradeを行うか生データから再度indexingするかの選択も必要です。
Solrに限らず、安定稼働しているシステムのバージョンアップは新機能が有効とみなされない限りなかなか踏み切れない企業もあるようです。実際にバージョンアップ作業は煩わしくミスも発生しやすいものです。
このセッションでは、典型的なバージョンアップ作業でよく見られる課題と解決策について議論されました。
基本的にはデータはきっちりバックアップしリカバーできるように常に実施しておき、メジャーバージョンアップには追従するのがおすすめで、2つ遅れたら再構築がよさそうです。
実施時はリリースノートやJIRAの情報に気を配り、可能であれば経験者の支援を受けるのがよいでしょう。
最後に彼が作成しているツールのデモも行われました。
(Githubに公開されているので、参加して欲しいとのこと)
日本語で技術支援サービスをご希望の方は、ロンウイットにご相談下さい。
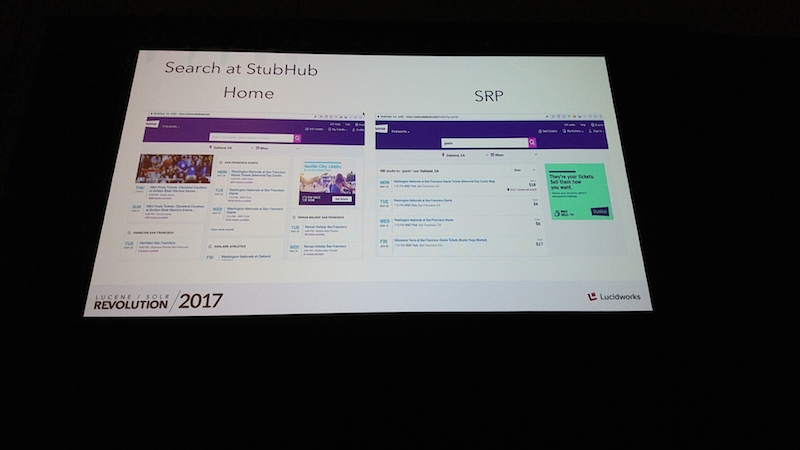
Event Search at Stubhub
StubHubはアメリカ最大のオンラインチケット販売サイトです。 売りたい人と買いたい人をうまくマッチングするために、StubHubはこの2-3年で大きく進化を遂げました。 以下の例では、左が改善後でGolden State Warriorsを重視しています。
プロダクトマネージャーのMayank Gupta検索担当エンジニアリングマネージャーのGopal Patwaが登壇。
機械学習の力によってユーザーがいかに自分の希望にあったイベントを見つけやすくなったか、NLPやランキングアルゴリズムの話を行っていました。
Closing
最後は全体セッションでLucidWorks創業者兼CTOのGrant Ingersollが登壇。 日本で先月夕食を共にしたこともあり、Apacheコミッターとして活躍し創業10年記念となった彼のメッセージに感動しました。 一流プログラマーであり、プレゼンスキルとグローバルなコミニュケーション力をお持ちの方がリードされ、コミュニティーも会社も大きく成長されたことは本当にすばらしいです。
彼がエンジニア達に熱く語ったメッセージの一部は以下です。
一方で、10年でハードもRDBもNoSQLもSolrも進化したので、複雑化かつ高機能化してどれを選んでソリューションを組むのかは難しくなってるかもしれません。
ただ、大規模Webサイトや先端企業は今回の事例のようにSolrを選んでいますし、多くのエンジニアを世界中から集めるLucene/Solrはこれからも成長を続けると感じました。
Off Time
せっかくラスベガスに出張で来たので、1泊オフをとってグランド・キャニオンに行きました。
写真では表現できない絶景で、行って良かった世界遺産ランキングのトップになるだけのことはありますネ。
毎年海外出張に行けて、オフも取りやすいのが弊社の特徴です!
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!