INFORMATION
テクノロジ
Solr ベンチマーク特集 第1回 インデクシング編
西潟 一生 著
はじめに
これから Solr を運用し始める人にとって,Solr が必要とするリソースはどの程度なのか,といった点は真っ先に知りたい情報の 1 つだと思います。
リソースといっても,検討すべき項目はいくつもあります。弊社でよく問い合わせを受けるのは以下の項目です。
- 必要になるサーバの台数
- CPU コア数
- メモリ
- ディスク
- 1 台で捌けるドキュメント数
- インデックスのサイズ
- インデクシングの時間
- 検索時のパフォーマンス
- レスポンスタイム
- スループット
運用にあたって検討すべき項目はもちろんこれだけではありませんが,上記の中でも更によく受ける質問は「どの程度のスペックのマシンをどれだけ用意すれば良いのか?」と言ったものです。
Solr の性質上,インデクシングする文書やスキーマ定義によって必要なマシンスペックが大きく変わるため,正確なサイジングを行うのは一筋縄にはいきません。
従って,上記の質問への回答は,検索対象の文書を実際に Solr に登録し,「1 台でどれほど捌けるのか試してからマシンスペックやマシン台数を決める」となる場合がほとんどです。
原則このような回答になるとは言え,いつもこの回答では,流石に不親切だと日々感じていました。
そこで,それでも何かの目安が欲しいという方のために,弊社では Solr のベンチマークを取った結果を Solr ユーザーの皆様に少しずつ公開していきたいと思います。
今回はその第 1 回目となります。
※ 以下に示すベンチマーク結果によって生じたあらゆる損害などについては,理由の如何を問わず,弊社は一切の責任を負わないことを予めご了承下さい。
インデクシングのベンチマーク
マシンを調達する上で,必要となるディスク容量を知ることは重要でしょう。Solr では,フィールドの数やそれらのオプション,フィールドタイプ,stored データの数などで,必要となるディスク容量は大きく異なります。
また,インデクシングの時間も大きく変わってきます。これらの設定は検索要件にも大きく関わってくるところなので,必要となる具体的なディスク容量の算出は,少なくともスキーマ設計をした後でないとできません。
以下に示すのは,Solr のインデクシングの挙動を分かりやすくするために簡便なスキーマ設定でインデクシングした結果です。
スキーマ設定は大きく分けて 3 種類用意しました。
- 形態素解析をベースとするベンチマーク
- NGram(bi-gram)をベースとするベンチマーク
- 形態素解析と NGram のハイブリッドをベースとするベンチマーク
日本語のドキュメントの検索では,主に形態素解析と NGram がよく使われるので,そのハイブリッドを含め 3 つのケースを用意しました。
それぞれのスキーマの詳細は以下で示してある「フィールド/フィールドタイプの定義」のようになっています。
以上のベンチマークで,以下の大まかな傾向が分かります。
- 本ベンチマークにおけるインデクシング時間
- stored を true にした時とそうでない時のインデックスサイズ
- 形態素解析, NGram のそれぞれのインデックスサイズの違い
- termVectors, termPosisions, termOffsets を true にした時とそうでない時のインデックスサイズ
用いたフィールド数は 3 つと非常に少ないので,実際のシステムではこれよりもインデックスサイズが大きくなったり,時間がかかったりするでしょう。
ベンチマーク環境
以下にベンチマークを実施した環境を示します。
マシンスペック
ベンチマークは AWS の EC2 を使って行いました。使用したマシンは以下の通りです。
m4.large(2 Cores, 8GB RAM)
Solr バージョン
Solr のバージョンは 6.3 を使用しました。また Solr に割り当てる JVM のヒープサイズは 6GB としました。
フィールド/フィールドタイプの定義
各ケースで使用するフィールドタイプの定義
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt" />
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt" />
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_2g" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<tokenizer class="solr.NGramTokenizerFactory" minGramSize="2" maxGramSize="2"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
形態素解析 ケース1 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="false"/> <field name="content" type="text_ja" indexed="true" stored="false"/>
形態素解析 ケース2 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="true"/> <field name="content" type="text_ja" indexed="true" stored="true"/>
形態素解析 ケース3 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="true"/> <field name="content" type="text_ja" indexed="true" stored="true" termPositions="true" termOffsets="true" termVectors="true"/>
NGram ケース1 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="false"/> <field name="content" type="text_2g" indexed="true" stored="false"/>
NGram ケース2 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="true"/> <field name="content" type="text_2g" indexed="true" stored="true"/>
NGram ケース3 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="true"/> <field name="content" type="text_2g" indexed="true" stored="true" termPositions="true" termOffsets="true" termVectors="true"/>
ハイブリッド ケース1 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="false"/> <field name="content" type="text_ja" indexed="true" stored="false"/> <field name="content_bi" type="text_2g" indexed="true" stored="false"/> <copyField source="content" dest="content_bi"/>
ハイブリッド ケース2 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="true"/> <field name="content" type="text_ja" indexed="true" stored="true"/> <field name="content_bi" type="text_2g" indexed="true" stored="false"/> <copyField source="content" dest="content_bi"/>
ハイブリッド ケース3 のフィールド定義
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="resourcename" type="string" indexed="true" stored="true"/> <field name="content" type="text_ja" indexed="true" stored="true"/> <field name="content_bi" type="text_2g" indexed="true" stored="false"/> <copyField source="content" dest="content_bi"/>
テストデータ
テストデータは 1 文書 5000 単語からなるプレーンテキスト(1ファイル辺り 80KB 前後)を1万件,5万件,10万件用意し測定しました。
この文書群は 2017 年 1 月時点の日本語 Wikipedia から形態素解析器 Mecab(IPAdic) によって抽出した形態素を助詞と助詞でないものを交互にランダムに出力し
1 文書 5000 単語(形態素)となるプログラムから出力されたものです。
従って,それぞれの文書は意味をなさない文章で構成されることになりますが
このテストにおいては特に測定を阻害するものではないと考えられるため,このような方法を取りました。
また,1 万件,5 万件,10 万件の文書は独立した文書群ではなく,5 万件の文書は 1 万件の文書を内包し,同様に 10 万件の文書は 1 万件,5 万件の文書を内包しています。
| 文書数 | テキストデータサイズ(GB) |
|---|---|
| 10000 | 1.16 |
| 50000 | 5.82 |
| 100000 | 11.63 |
測定方法
Solr への登録方法は Solr 付属の Post Tool を使用しました。 以下は 1 万件のテキストデータを Solr に登録する時に使用したコマンドです。 ${SOLR} は Solr のインストールディレクトリ,${EXAMPLE_DIR} はテストデータが含まれているディレクトリを指します。
$ ${SOLR}/bin/post -c collection1 ${EXAMPLE_DIR}/10000
Solr はシングルサーバー構成としました。
測定結果
測定結果を以下に示します。結果はそれぞれ上記の「フィールド/フィールドタイプの定義」で示した定義と対応しています。その他の設定については Solr のデフォルト設定を使用しています。従って,オートコミットの間隔や compression mode を変更することでまた結果は変わってくるでしょう。その結果については次回以降,機会がありましたら改めてお知らせしたいと思います。
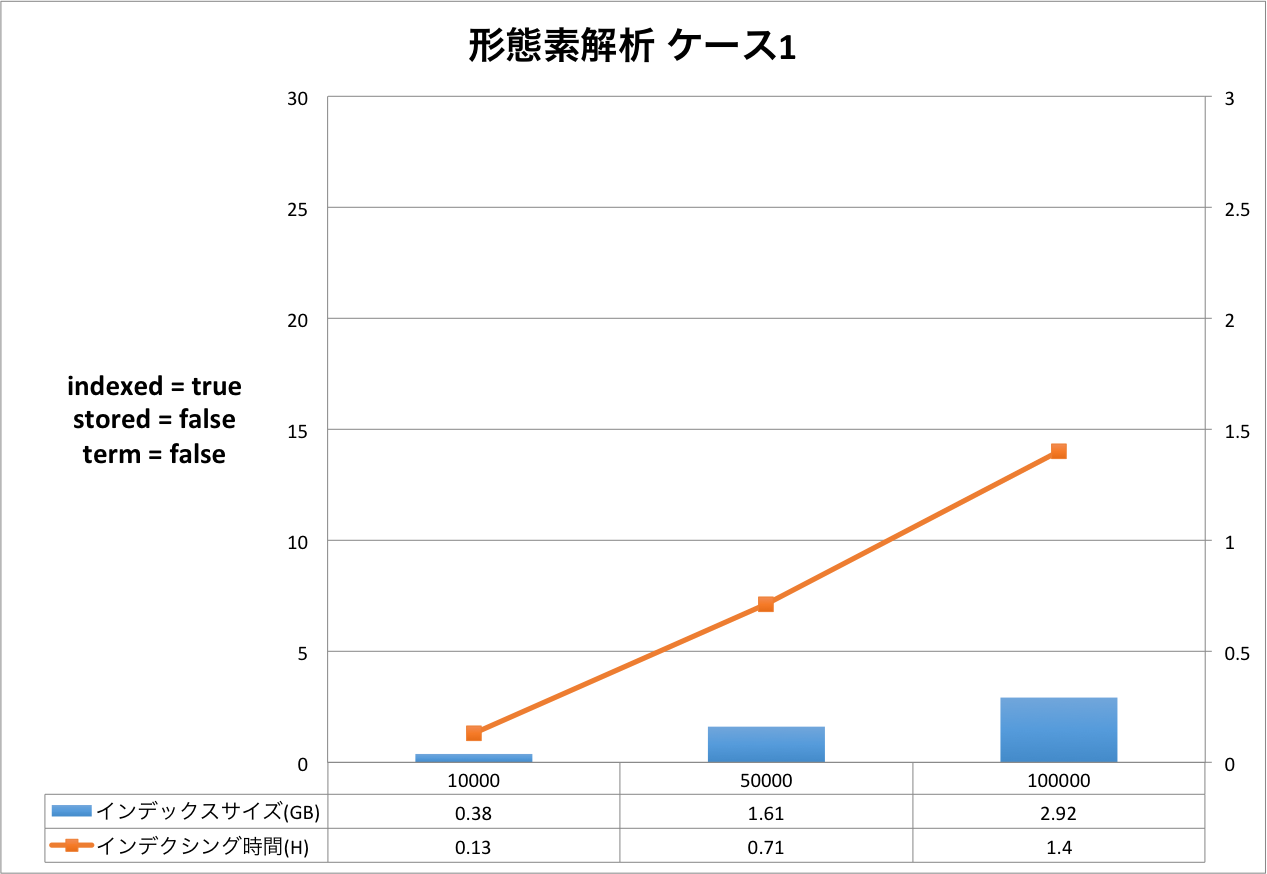
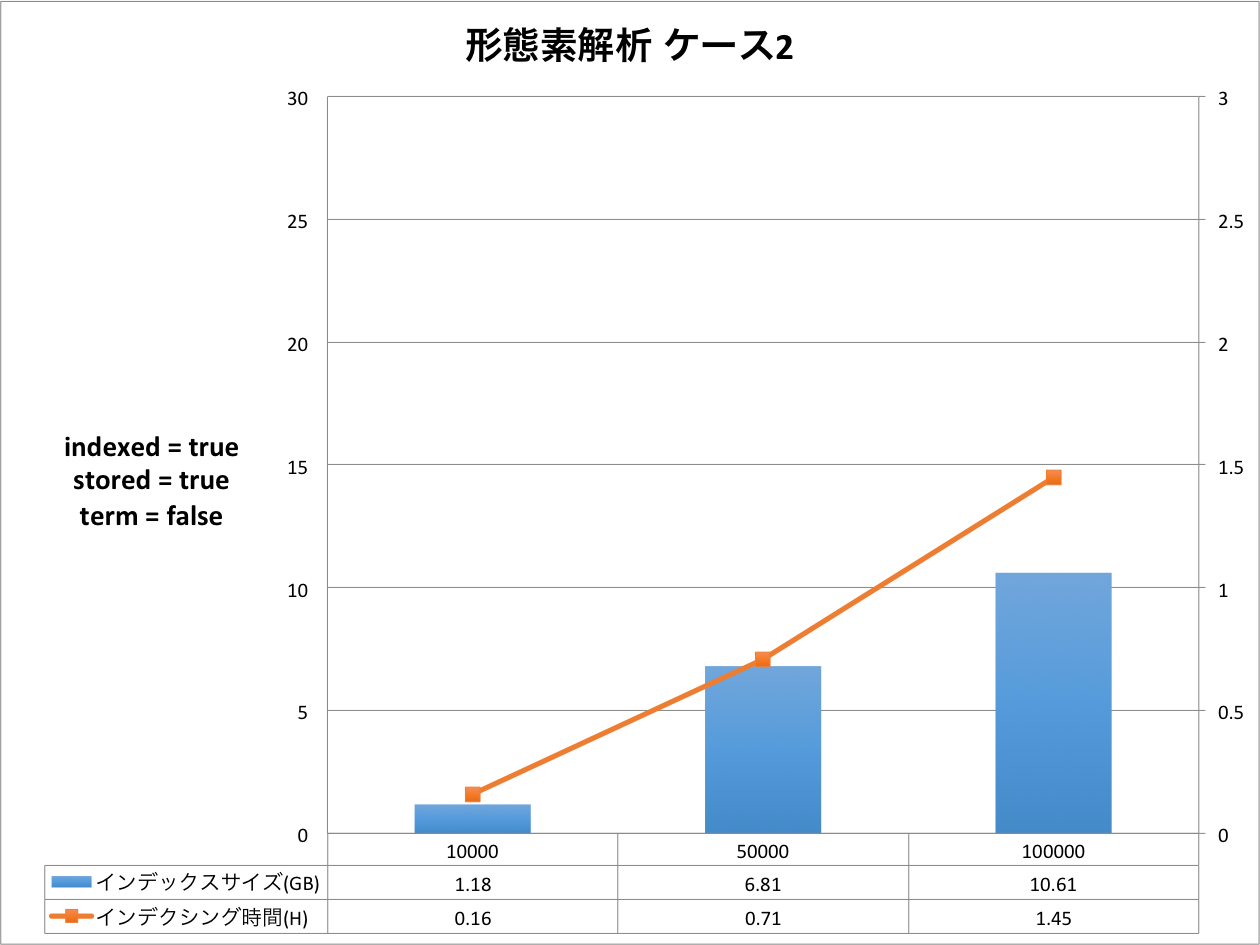
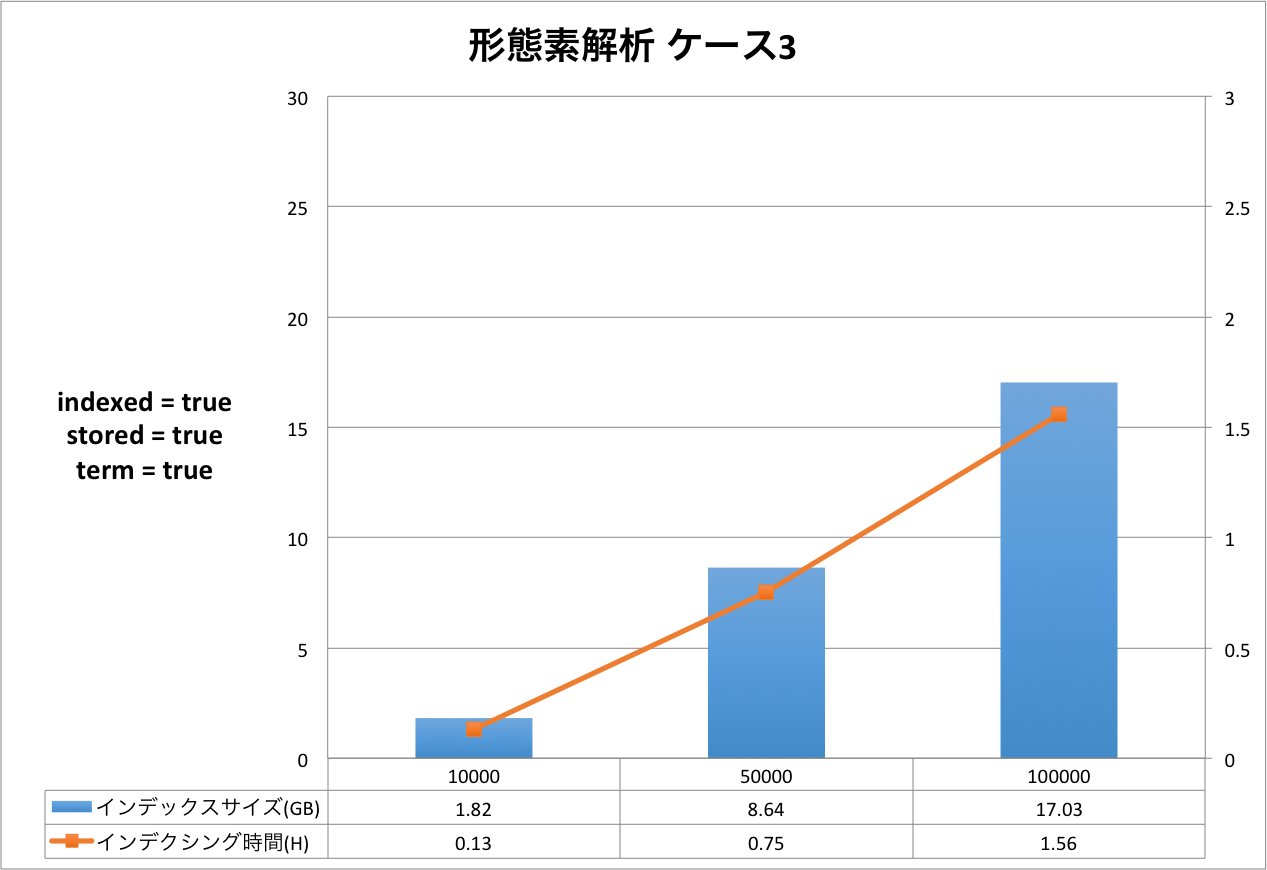
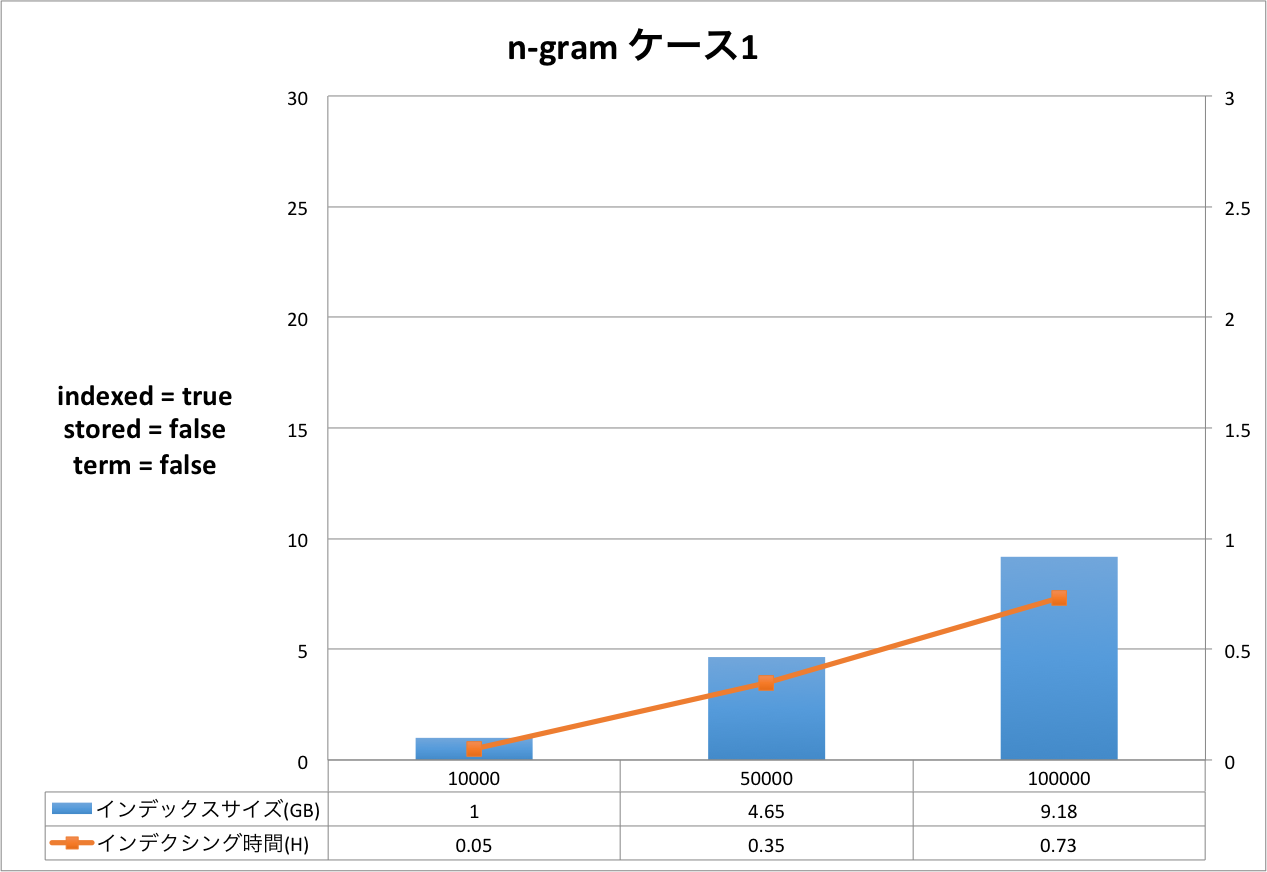
結果の表は,右側のX軸がインデクシング時間を表し,左側のX軸はインデックスサイズを表しています。Y軸はドキュメントの量を表しています。グラフだと細かい部分が分かりづらいため,表をグラフの下に表示しています。
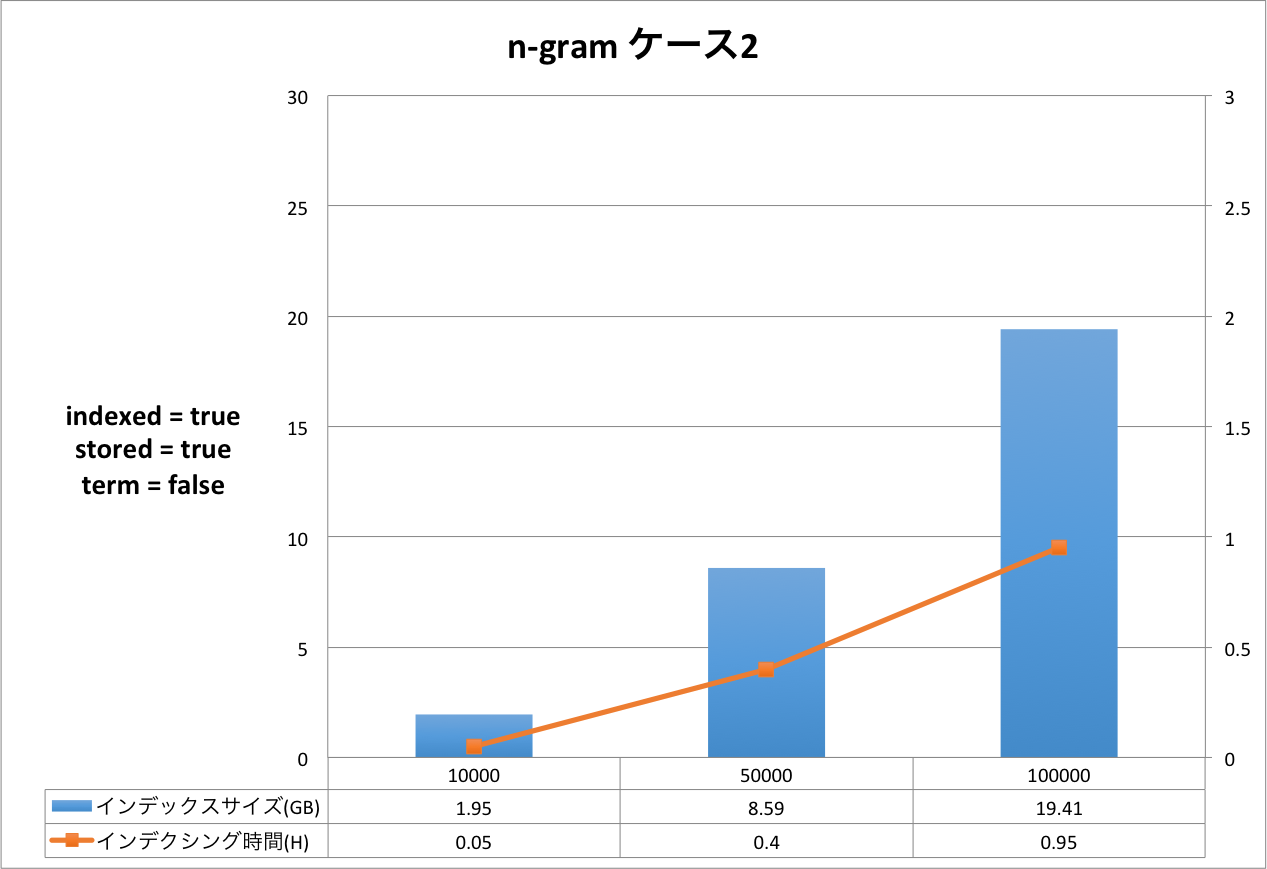
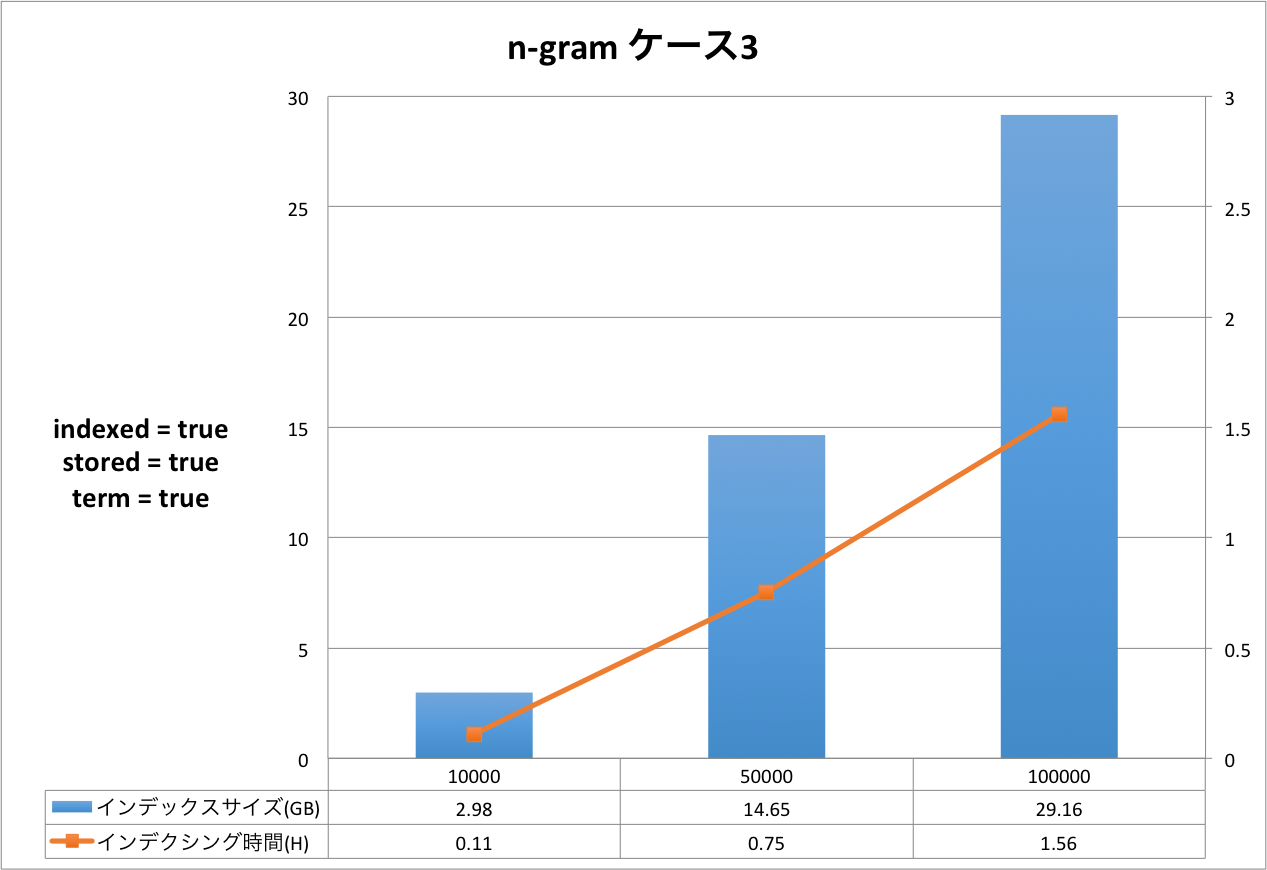
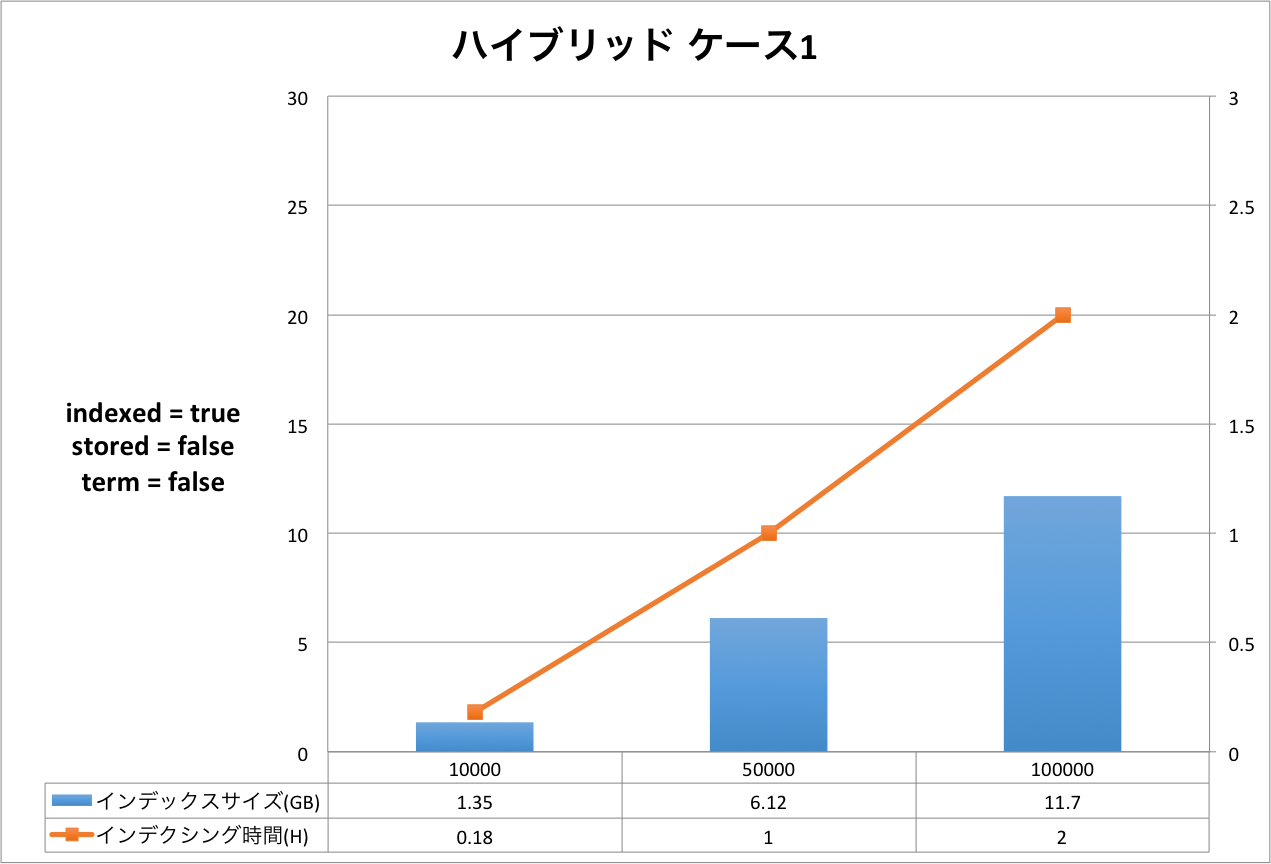
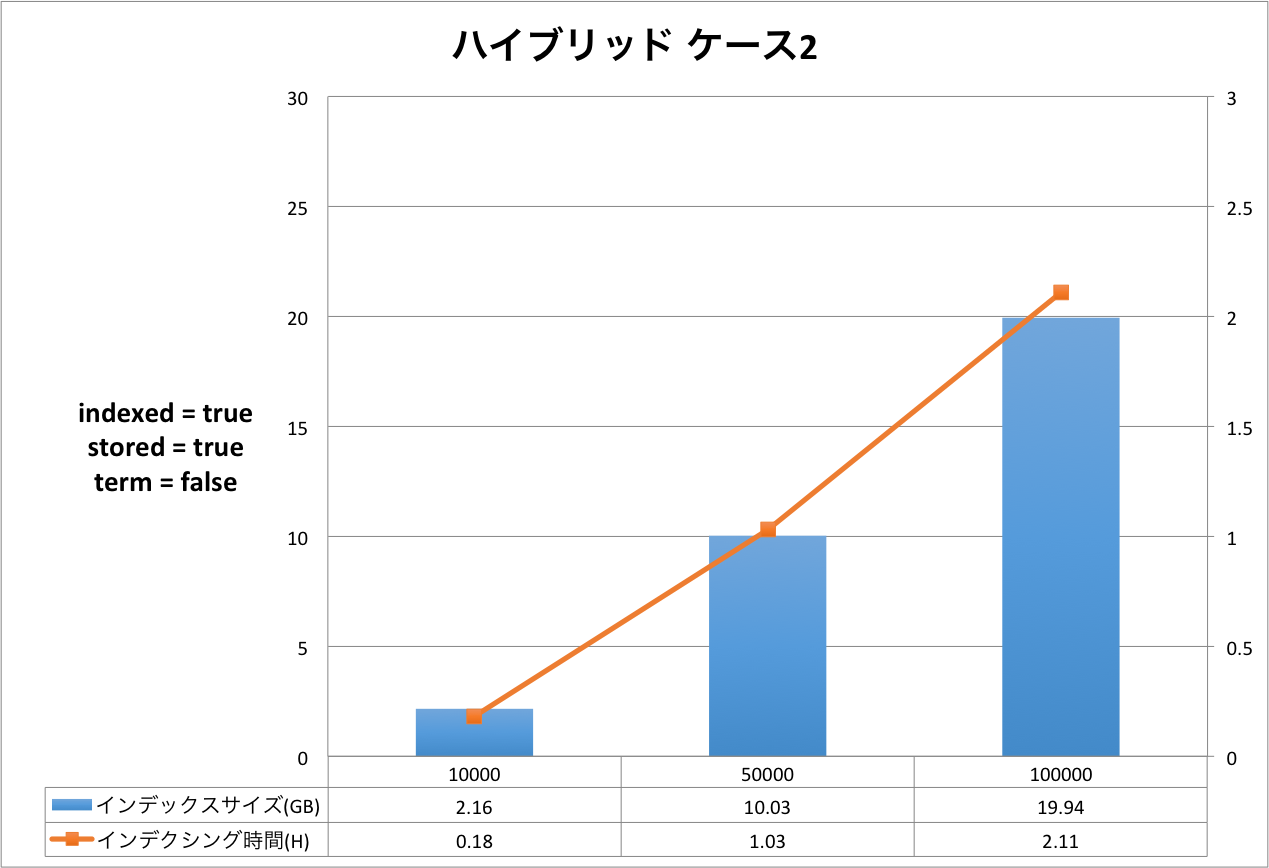
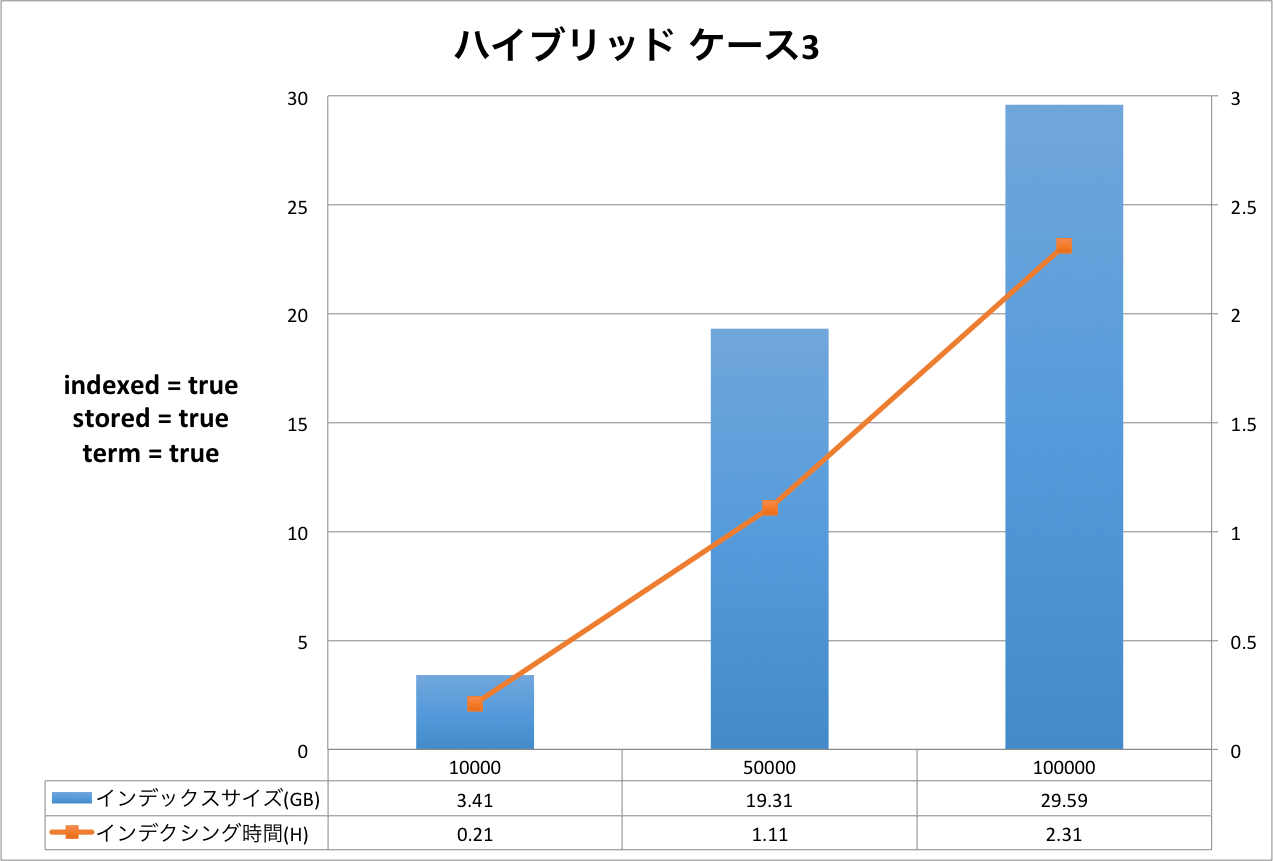
評価・考察
ケース1からケース3まで順にインデックスサイズ,インデクシング時間が大きくなっていることが分かります。定義をリッチにすればインデックスサイズもインデクシング時間も増えるという,素直な結果となったと思います。
今回のケースにおいては,インデックスサイズが最小になるケースと最大になるケースを比較すると,ドキュメント数10万件の時,2.92GB(形態素解析 ケース1)と29.59GB(ハイブリッド ケース3)なので,同じドキュメントを登録したとしても10倍の差が出るということになります。 もちろんこれらのケースは実運用に即したスキーマ定義ではないため,10倍という値自体は何の意味も持ちません。ここで知っておいていただきたいのは,簡便なスキーマ定義の違いでも10倍も差が発生する場合があるということです。
インデクシング時間についても同様です。最小が0.73時間(約44分),最大が2.31時間(約2時間19分)なので,約3倍の差が発生しています。
それぞれのケースについてもう少し詳しく見てみましょう。以下は,元データと Solr のインデックスのサイズ比を示した表です。 全ての結果において,文書数が増えると,サイズ比が小さくなっていることが分かります。今回は文書数が最大で 10 万と非常に少ないので,このデータから確かなことは言えませんが Solr がかかえているタームの異なり数が減少していくため,サイズ比が小さくなっていくと考えられます。 この傾向はハイブリッドでも同様でした。
| ケース | テキストデータサイズ(GB) | インデックスサイズ(GB) | サイズ比(%) |
|---|---|---|---|
| 形態素解析 ケース1 | 1.16 | 0.38 | 32.76 |
| 5.82 | 1.61 | 27.66 | |
| 11.63 | 2.92 | 25.11 | |
| 形態素解析 ケース2 | 1.16 | 1.18 | 101.72 |
| 5.82 | 6.81 | 117.01 | |
| 11.63 | 10.61 | 91.23 | |
| 形態素解析 ケース3 | 1.16 | 1.82 | 156.90 |
| 5.82 | 8.64 | 148.45 | |
| 11.63 | 17.03 | 146.43 |
| ケース | テキストデータサイズ(GB) | インデックスサイズ(GB) | サイズ比(%) |
|---|---|---|---|
| NGram ケース1 | 1.16 | 1.00 | 86.21 |
| 5.82 | 4.65 | 79.90 | |
| 11.63 | 9.18 | 78.93 | |
| NGram ケース2 | 1.16 | 1.95 | 168.10 |
| 5.82 | 8.59 | 147.59 | |
| 11.63 | 19.41 | 166.90 | |
| NGram ケース3 | 1.16 | 2.98 | 256.90 |
| 5.82 | 14.65 | 251.72 | |
| 11.63 | 29.16 | 250.73 |
| ケース | テキストデータサイズ(GB) | インデックスサイズ(GB) | サイズ比(%) |
|---|---|---|---|
| ハイブリッド ケース1 | 1.16 | 1.00 | 86.21 |
| 5.82 | 6.12 | 105.15 | |
| 11.63 | 11.7 | 100.60 | |
| ハイブリッド ケース2 | 1.16 | 2.16 | 186.21 |
| 5.82 | 10.03 | 172.34 | |
| 11.63 | 19.94 | 171.45 | |
| ハイブリッド ケース3 | 1.16 | 3.41 | 293.97 |
| 5.82 | 19.31 | 331.79 | |
| 11.63 | 29.59 | 254.43 |
また,この結果から,形態素解析と NGram では NGram の方がインデックスサイズが大きくなることが分かります。 このケースに限って言えば,形態素解析のみを使用すれば,元のテキストとほぼ同じか少なめのインデックスサイズになるのに対し,NGram では70%弱程多くディスクが必要になりそうです。 これは,Solr のタームが抱えているポスティングリストの数が形態素解析と NGram で異なるためと考えられます。 ハイブリッドとなると70%強程多くディスクが必要になる結果となりましたが,思ったほどのインデックスサイズ増加とはなりませんでした。これはハイブリッドのスキーマ定義で NGram フィールドを stored=false としているためと言えそうです。
全体として,stored=true の設定は元データをそのまま保存することになるので,ディスクの増加には大きく影響すると言えるでしょう。また,termVector,termOffsets,termPositions を true にするとハイブリッドにおいては インデックスサイズが元データに対し,3倍以上必要になるケースがあることも分かりました。今回のスキーマ定義は非常に簡便なものなので,実運用環境ではインデックスサイズがこれよりも大きくなることが想定されるでしょう。
実際の環境では,形態素解析と NGram のハイブリッド構成(ケース2 もしくは ケース3)を取る場合が多いので,この結果を持って 10 万文書のインデクシングに必要なディスクサイズは最低限
元データの約 1 〜 2.5 倍必要である,というのはあまりに乱暴な結論ですが 1 つの目安になるかとは思います。
今後の課題(次回予告)
今回のケースでは,かなり簡便な方法でのベンチマークを行いました。次回はもう少しベンチマークのケースを増やして計測を行なっていきたいと思います。主に以下のようなベンチマークを予定しています。
- バイナリファイルのインデクシング
- 複数サーバーでのインデクシング(スループットへの効果計測)
- オートコミットや compression mode を変更した時のインデクシング結果
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!