INFORMATION
サービス
Apache Solr の日本語シノニム検索とハイライト 最新事情(2021年版)
はじめに
Apache Solr における日本語のシノニム検索とシノニムを考慮したハイライトの動作について、検証を行ったので報告する。検証は2021年11月上旬から開始したので、当時の最新バージョンである Solr 8.10.1 で行い、本文もその検証結果をもとに執筆されている。しかし、その後 Solr 8.11.0 で再テストを行い、その結果が Solr 8.10.1 の結果と差異がないことも確認済みである。なお、以前のバージョンでのシノニム検索とシノニムハイライトについては以下を参照されたい。
前準備
試行錯誤を経て、検証は以下の2ステップに分けて行うことにした。
- (ステップ1)正しい検索結果を返すフィールド型の選出
後述する様々なフィールド型においてシノニム検索を行い正しい検索結果を返すものを確認する。 - (ステップ2)正しいハイライトがなされるフィールド型の選出
同様に様々なフィールド型においてシノニムを考慮したハイライトが正しく行われるかを確認する。
Apache Solrは、検索に使用するフィールドとハイライト対象にするフィールドを分けることができるが、事前調査の結果、ステップ2で得られた「正しくハイライトが行われるフィールド型」が、ステップ1で得られた「検索で正しい結果を返すフィールド型」のサブセットとなることが判明した。そこで本稿では、ステップ1で得られたフィールド型のうち、さらにステップ2でハイライトが正しくなされるフィールド型は何か、という表現になっているが、あらかじめご了承いただきたい。
テストのために用意するフィールド型
日本語でシノニム検索とハイライトを考えるとき、以下に示すようにApache Solrでは多くのパラメーター設定があり、その組み合わせは多岐にわたる。本検証ではシノニム検索がうまくいかないと予想できる場合においても漏れがないように網羅的にテストを行うこととした。
以下の場合について網羅的に組み合わせたフィールド型を用意する。
- 形態素区切りかN-gram区切りか
N-gramの代表として今回の検証では2-gramを用いる。
形態素区切り:フィールド型名のtext_の後ろがjaのもの(例:text_ja_e_q_sgf)
N-gram区切り:フィールド型名のtext_の後ろが2gのもの(例:text_2g_e_i_sgffgf)
- シノニムの適用方法をnormlizeにするかexpandにするか
normalizeはシノニムをある一つの代表表記に正規化してシノニム検索を可能にする方法である。
expandはシノニム全てを展開してシノニム検索を可能にする方法である。
normalize:フィールド型名のtext_*_の後ろがnのもの(例:text_ja_n_q_sgf)
expand:フィールド型名のtext_*_の後ろがeのもの(例:text_ja_e_i_sgffgf)
※フィールド型名の後ろがnnや、en等2桁になっている場合は、1桁目が索引時、2桁目が検索時という意味である) - シノニムの適用を索引時にするか検索時にするかあるいは両方にするか
Solrは、索引時にもシノニム適用が可能であり索引時にexpandでシノニムを適用した場合には全てのシノニムについて展開が行われ索引付けが行われる。
索引時:フィールド型名のtext_*_*_の後ろがiのもの(例:text_ja_e_i_sgffgf)
検索時:フィールド型名のtext_*_*_の後ろがqのもの(例:text_ja_e_q_sgf)
両方:フィールド型名のtext_*_*_の後ろがiqのもの(例:text_ja_ne_iq_sgffgfsgf。なお、索引時はnormalize、検索時はexpand)
Filterの適用についての注意
シノニムを適用する場合、索引時と検索時では以下のようにFilterを適用することとする。
- 索引時
SynonymGraphFilterとFlattenGraphFilterを使用する。
※FlattenGraphFilterは、インデクシング時のみSynonymGraphFilterの直後に配置することが強く推奨されている。
フィールド型名の末尾が、sgffgfで終わる。
<analyzer type="index"> <tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/> <filter class="solr.SynonymGraphFilterFactory" expand="true" (or false) ignoreCase="true" synonyms="synonyms.txt" tokenizerFactory="solr.JapaneseTokenizerFactory" tokenizerFactory.mode="normal" /> <filter class="solr.FlattenGraphFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/> </analyzer> - 検索時
フィールド型名の末尾が、sgfで終わる。
<analyzer type="index"> <tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/> <filter class="solr.SynonymGraphFilterFactory" expand="true" (or false) ignoreCase="true" synonyms="synonyms.txt" tokenizerFactory="solr.JapaneseTokenizerFactory" tokenizerFactory.mode="normal" /> </analyzer> - 索引時及び検索時
フィールド型名の末尾が、sgffgfsgfで終わる。
<analyzer type="index"> <tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/> <filter class="solr.SynonymGraphFilterFactory" expand="true" (or false) ignoreCase="true" synonyms="synonyms.txt" tokenizerFactory="solr.JapaneseTokenizerFactory" tokenizerFactory.mode="normal" /> <filter class="solr.FlattenGraphFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/> <filter class="solr.SynonymGraphFilterFactory" expand="true" (or false) ignoreCase="true" synonyms="synonyms.txt" tokenizerFactory="solr.JapaneseTokenizerFactory" tokenizerFactory.mode="normal" /> </analyzer>
なお、ManagedSynonymGraphFilterという、シノニム辞書をREST APIでメンテする別バージョンのSynonymGraphFilterがあるが、動作はSynonymGraphFilterと同じはずなので、SynonymGraphFilterのみ検証した。ManagedSynonymGraphFilterについてはまた別の機会に検証したい。
フィールド名
フィールド名はわかりやすいようにフィールド型名の先頭textをcontentに置き換えたものにする。
また、「termVectors=”true” termOffsets=”true” termPositions=”true”」をつけるようにしているが、これはハイライト(fastVector)をする際に必要な指定のためである。
上記より、用意したフィールドは以下のようになる。id、contentの2つのフィールドと、その他のcontent_*という16種類の検証用に使用するフィールドを持っている。content_*はcontentフィールドをもとにしたコピーフィールドとなっている。
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="content" type="string" indexed="true" stored="true" required="true" multiValued="true" /> <dynamicField name="*_ja_n_q_sgf" type="text_ja_n_q_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_n_i_sgffgf" type="text_ja_n_i_sgffgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_nn_iq_sgffgfsgf" type="text_ja_nn_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_ne_iq_sgffgfsgf" type="text_ja_ne_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_e_q_sgf" type="text_ja_e_q_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_e_i_sgffgf" type="text_ja_e_i_sgffgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_ee_iq_sgffgfsgf" type="text_ja_ee_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_ja_en_iq_sgffgfsgf" type="text_ja_en_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_n_q_sgf" type="text_2g_n_q_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_n_i_sgffgf" type="text_2g_n_i_sgffgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_nn_iq_sgffgfsgf" type="text_2g_nn_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_ne_iq_sgffgfsgf" type="text_2g_ne_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_e_q_sgf" type="text_2g_e_q_sgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_e_i_sgffgf" type="text_2g_e_i_sgffgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_ee_iq_sgffgfsgf" type="text_2g_ee_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <dynamicField name="*_2g_en_iq_sgffgfsgf" type="text_2g_en_iq_sgffgfsgf" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" /> <copyField source="content" dest="content_ja_n_q_sgf" /> <copyField source="content" dest="content_ja_n_i_sgffgf" /> <copyField source="content" dest="content_ja_nn_iq_sgffgfsgf" /> <copyField source="content" dest="content_ja_ne_iq_sgffgfsgf" /> <copyField source="content" dest="content_ja_e_q_sgf" /> <copyField source="content" dest="content_ja_e_i_sgffgf" /> <copyField source="content" dest="content_ja_ee_iq_sgffgfsgf" /> <copyField source="content" dest="content_ja_en_iq_sgffgfsgf" /> <copyField source="content" dest="content_2g_n_q_sgf" /> <copyField source="content" dest="content_2g_n_i_sgffgf" /> <copyField source="content" dest="content_2g_nn_iq_sgffgfsgf" /> <copyField source="content" dest="content_2g_ne_iq_sgffgfsgf" /> <copyField source="content" dest="content_2g_e_q_sgf" /> <copyField source="content" dest="content_2g_e_i_sgffgf" /> <copyField source="content" dest="content_2g_ee_iq_sgffgfsgf" /> <copyField source="content" dest="content_2g_en_iq_sgffgfsgf" />
シノニム辞書(synonym.txt)
シノニム辞書の内容は以下の通りである。
総理大臣,首相,総理,内閣総理大臣
先に示したSynonymGraphFilterFactoryのexpandパラメータをfalseにするとnormalizeで、trueにするとexpandでのシノニム適用になる。
normalizeとexpandの違いを説明する前にシノニム辞書には”=>”を使った明示的な記述法というものが存在し、それは以下の様なものである。
aaa,bbb => ccc,ddd,eee
この意味は、”=>”の左側に書かれたそれぞれの語が、右側全部に展開される(置き換わる)というものである。
つまり上記の意味はこういうことである。
「aaa」という語が来た場合には、「ccc,ddd,eee」に展開し(置き換え)処理される
「bbb」という語が来た場合には、「ccc,ddd,eee」に展開し(置き換え)処理される
明示的に書かれたシノニム辞書の場合、SynonymGraphFilterFactoryのexpandパラメータは無視される。
・normalizeでのシノニム適用
それでは、normalizeでのシノニム適用とはどういうものか明示的に記述してみると以下のようになる。
総理大臣,首相,総理,内閣総理大臣 => 総理大臣
「総理大臣」、「首相」、「総理」、「内閣総理大臣」どの語が来ても、「総理大臣」という一つの語(代表表記)に置き換えられ処理されるということである。代表表記には一番左に書いた語が割り当てられる。
・expandでのシノニム適用
一方、expandでのシノニム適用とはどういうものか明示的に記述してみると以下のようになる。
総理大臣,首相,総理,内閣総理大臣 => 総理大臣,首相,総理,内閣総理大臣
「総理大臣」、「首相」、「総理」、「内閣総理大臣」どの語が来ても、それぞれの語が、「総理大臣」、「首相」、「総理」、「内閣総理大臣」という複数の語に展開され処理されるということである。
テストデータ
索引付けするテストデータは以下のcsvデータであり、第1フィールドがid、第2フィールドがcontentの内容である。
1,首相でございます 2,総理でございます 3,総理大臣でございます 4,内閣総理大臣でございます 5,内閣でございます 6,大臣でございます 7,内閣大臣でございます
検索結果の判定方法
16種類の検証用フィールドについて、「首相」、「総理」、「総理大臣」、「内閣総理大臣」を検索語としてそれぞれ検索した場合、シノニムを含む検索結果だけが得られるかを検証する。 「首相」、「総理」、「総理大臣」、「内閣総理大臣」のどの検索語で検索した場合でも、結果としてid1~4だけが得られるはずである。
具体的には以下を行い検証する。
content_ja_n_q_sgfを
「首相」で検索した場合、id1~4だけが得られるか
「総理」で検索した場合、id1~4だけが得られるか
「総理大臣」で検索した場合、id1~4だけが得られるか
「内閣総理大臣」で検索した場合、id1~4だけが得られるか
content_ja_n_i_sgffgfを
「首相」で検索した場合、id1~4だけが得られるか
「総理」で検索した場合、id1~4だけが得られるか
「総理大臣」で検索した場合、id1~4だけが得られるか
「内閣総理大臣」で検索した場合、id1~4だけが得られるか
・
・
・
(ステップ1)正しい検索結果を返すフィールド型の選出
管理画面によるテストのサンプル画面
16種類の検証用フィールドを用いてのテスト実施は複雑なので、実際にはスクリプトを作成し行ったが、Solr管理画面からでも次のように設定すれば特定のパラメーターの組み合わせを試すことができる。
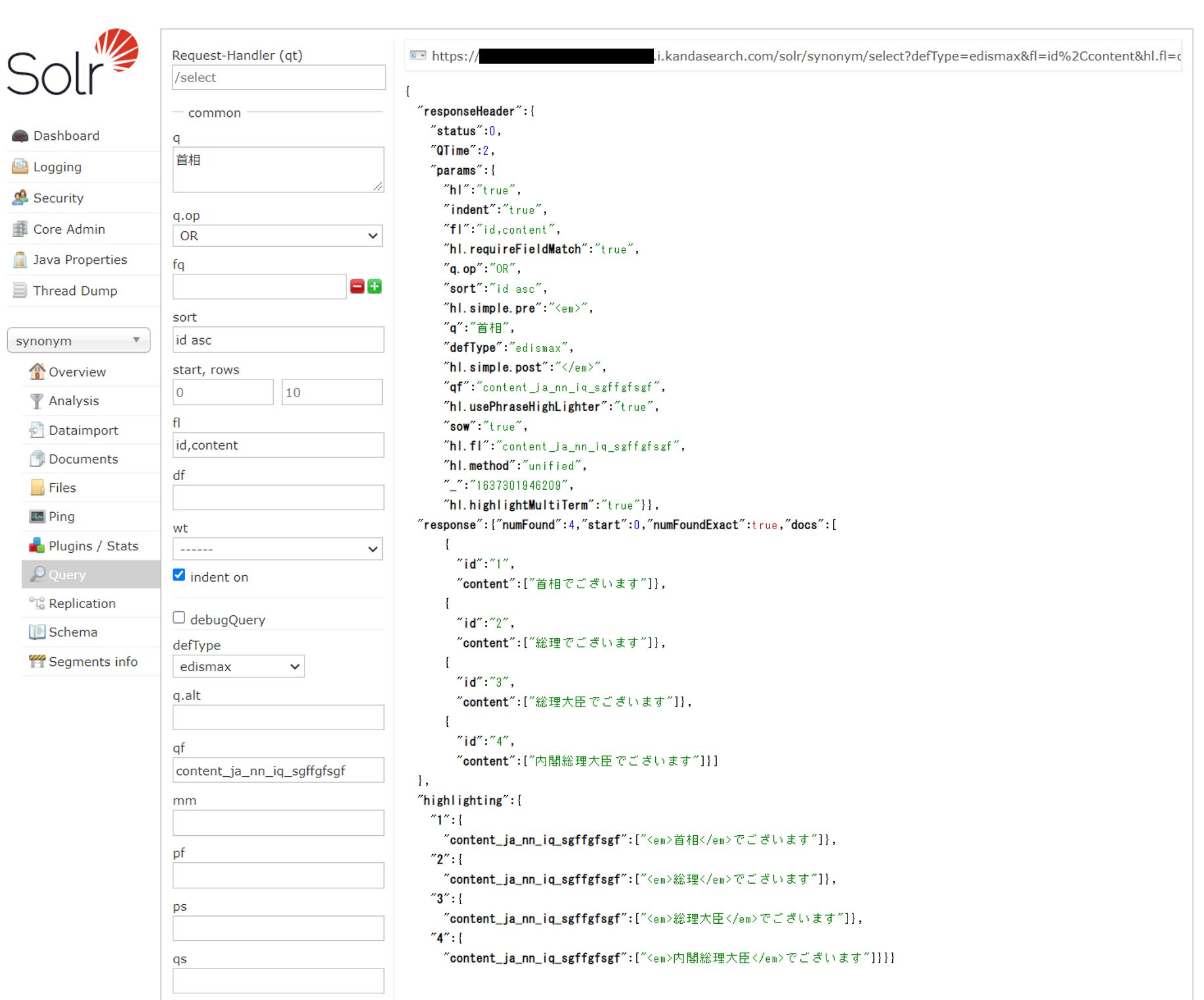
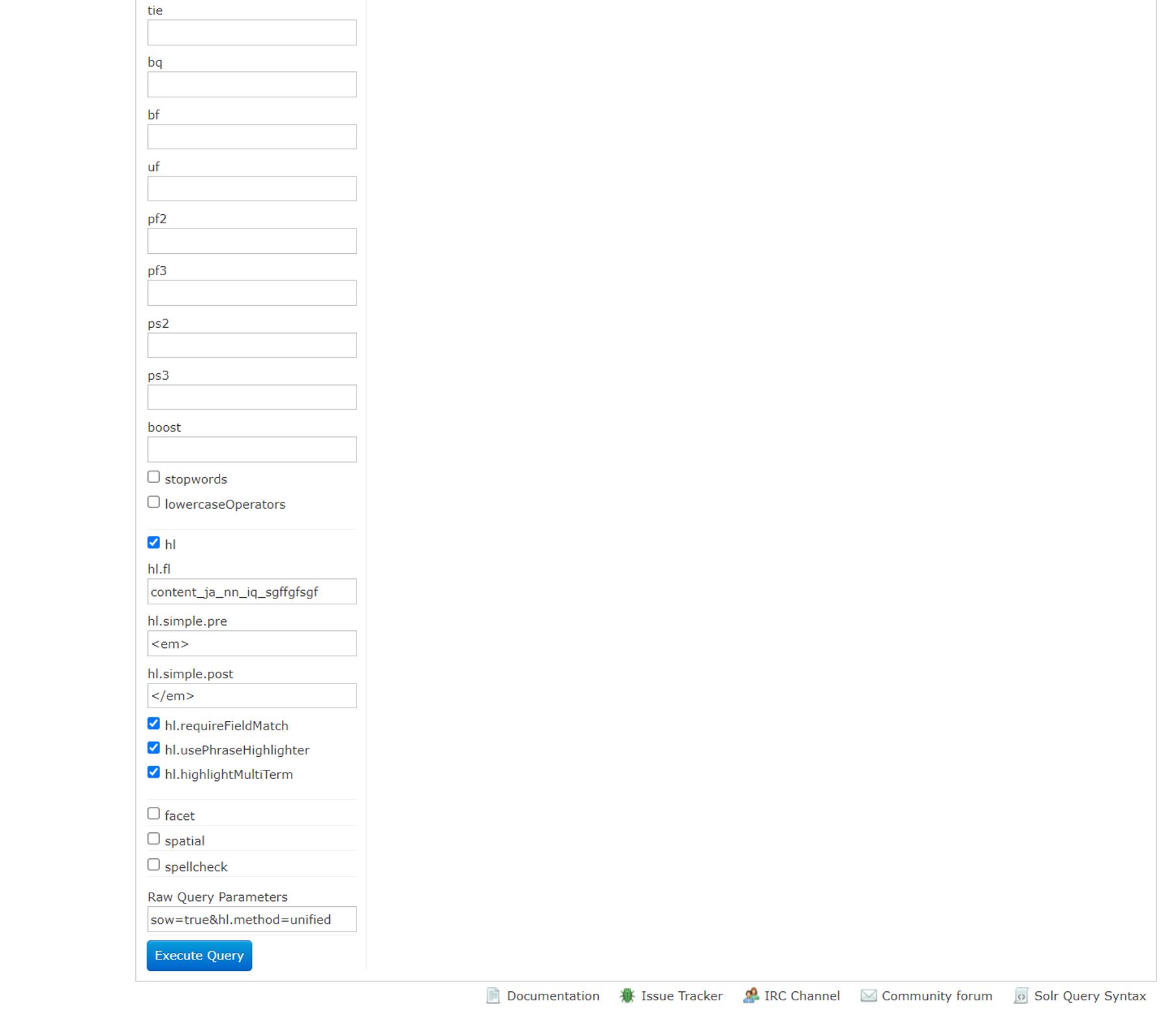
edismaxを使用しての検索の説明は、「KandaSearch ではじめる Apache Solr 入門」を参照していただくとして、
ここでは、ハイライトに関するパラメータなどについて簡単に説明する。
| hl | チェックをするとハイライトを行う | ||||||
| hl.fl | ハイライト対象のフィールド。スペースやカンマで区切ることで複数指定できる。 | ||||||
| hl.simple.pre | ハイライトされる文字列の前に出力するタグ(文字列) ※注1 | ||||||
| hl.simple.post | ハイライトされる文字列の後に出力するタグ(文字列) ※注1 | ||||||
| hl.requireFieldMatch | trueにすると、ハイライト対象のフィールドが複数存在するときにこのフィールドに関するクエリ検索語のみがハイライトされる。 例えばtitle、bodyともにハイライト対象になっており、bodyに「先生」も「学校」も存在し、「title:先生 OR body:学校」で検索を行ったとすると、bodyのハイライトは、このパラメータの値により次のようになる。 trueなら、bodyに関する検索語の「学校」しかハイライトされないが、falseならtitleに関する検索語の「先生」もハイライトされる。 |
||||||
| hl.usePhraseHighlighter | クエリにフレーズ検索が存在するときはフレーズだけをハイライトする。 なお、Solr管理画面のusePhraseHighlighterは、usePhraseHighLighter(Lが大文字)として解釈されてしまうようでうまく機能しないので注意されたい。 これを回避するためには、例えば以下のようにusePhraseHighLighterを修正したクエリ式をアドレスバーに入れる必要がある。
https://●●●●●●●●●●.i.kandasearch.com/solr/synonym/select?debugQuery=true&df=content_ja&hl.fl=content_ja&hl.usePhraseHighlighter=true&hl=true&indent=true&q.op=OR&q=XXXXXXXXXX&sow=on
| ||||||
| hl.highlightMultiTerm | ワイルドカード検索やあいまい検索等でもハイライトを行うようにする。 | ||||||
| hl.method | ハイライトの方式。unified,original,fastVectorの三つの方式がある。
| ||||||
| sow | Split On Whitespaceの略。sow=falseがデフォルト動作となっており、sow=trueを明示しないと、autoGeneratePhraseQueries=trueの設定が効かなくなってしまい、フレーズ展開されなくなるので、 日本語の検索で期待通りの動作をしなくなってしまう。したがって今回の検証は常にsow=trueとして行った。※注2 |
※注1 fastVectorの場合は検索キーワードごとにハイライトの色を変えることができるので、solrconfig.xmlに以下のように設定する。
<fragmentsBuilder name="colored"
class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre"><![CDATA[
<b style="background:yellow">,<b style="background:lawgreen">,
<b style="background:aquamarine">,<b style="background:magenta">,
<b style="background:palegreen">,<b style="background:coral">,
<b style="background:wheat">,<b style="background:khaki">,
<b style="background:lime">,<b style="background:deepskyblue">]]></str>
<str name="hl.tag.post"><![CDATA[</b>]]></str>
</lst>
</fragmentsBuilder>
※注2 sowについてはdebugQueryをonにして、作成されるクエリを確認すると以下の様に違いがあることがわかる。
sow=trueの場合
"parsedquery":"+DisjunctionMaxQuery((content_ja_nn_iq_sgffgfsgf:\"総理 大臣\"))" "parsedquery_toString":"+(content_ja_nn_iq_sgffgfsgf:\"総理 大臣\")"
このクエリによる検索結果は以下のようになる。
| id | 結果 |
|---|---|
| 1 | 首相でございます |
| 2 | 総理でございます |
| 3 | 総理大臣でございます |
| 4 | 内閣総理大臣でございます |
"parsedquery":"+DisjunctionMaxQuery(((content_ja_nn_iq_sgffgfsgf:総理 content_ja_nn_iq_sgffgfsgf:大臣))) "parsedquery_toString":"+((content_ja_nn_iq_sgffgfsgf:総理 content_ja_nn_iq_sgffgfsgf:大臣))"
このクエリによる検索結果は以下のようになる。id6、7がノイズとして検索されてしまっている。
| id | 結果 |
|---|---|
| 1 | 首相でございます |
| 2 | 総理でございます |
| 3 | 総理大臣でございます |
| 4 | 内閣総理大臣でございます |
| 6 | 大臣でございます |
| 7 | 内閣大臣でございます |
(ステップ1)正しい検索結果を返すフィールド型の選出結果
以下のフィールド型による検索が正しい検索結果を返した。
text_ja_nn_iq_sgffgfsgf text_ja_ne_iq_sgffgfsgf text_ja_e_q_sgf text_ja_e_i_sgffgf text_ja_ee_iq_sgffgfsgf text_ja_en_iq_sgffgfsgf
但しexpandでシノニム適用する場合は、索引時か検索時の片方だけに使用すればよいはずなのでtext_ja_ne_iq_sgffgfsgf、text_ja_ee_iq_sgffgfsgf、text_ja_en_iq_sgffgfsgfは無駄である。 したがって以下が「(ステップ2)正しいハイライトがなされるフィールド型の選出」候補として残る。
text_ja_nn_iq_sgffgfsgf text_ja_e_q_sgf text_ja_e_i_sgffgf
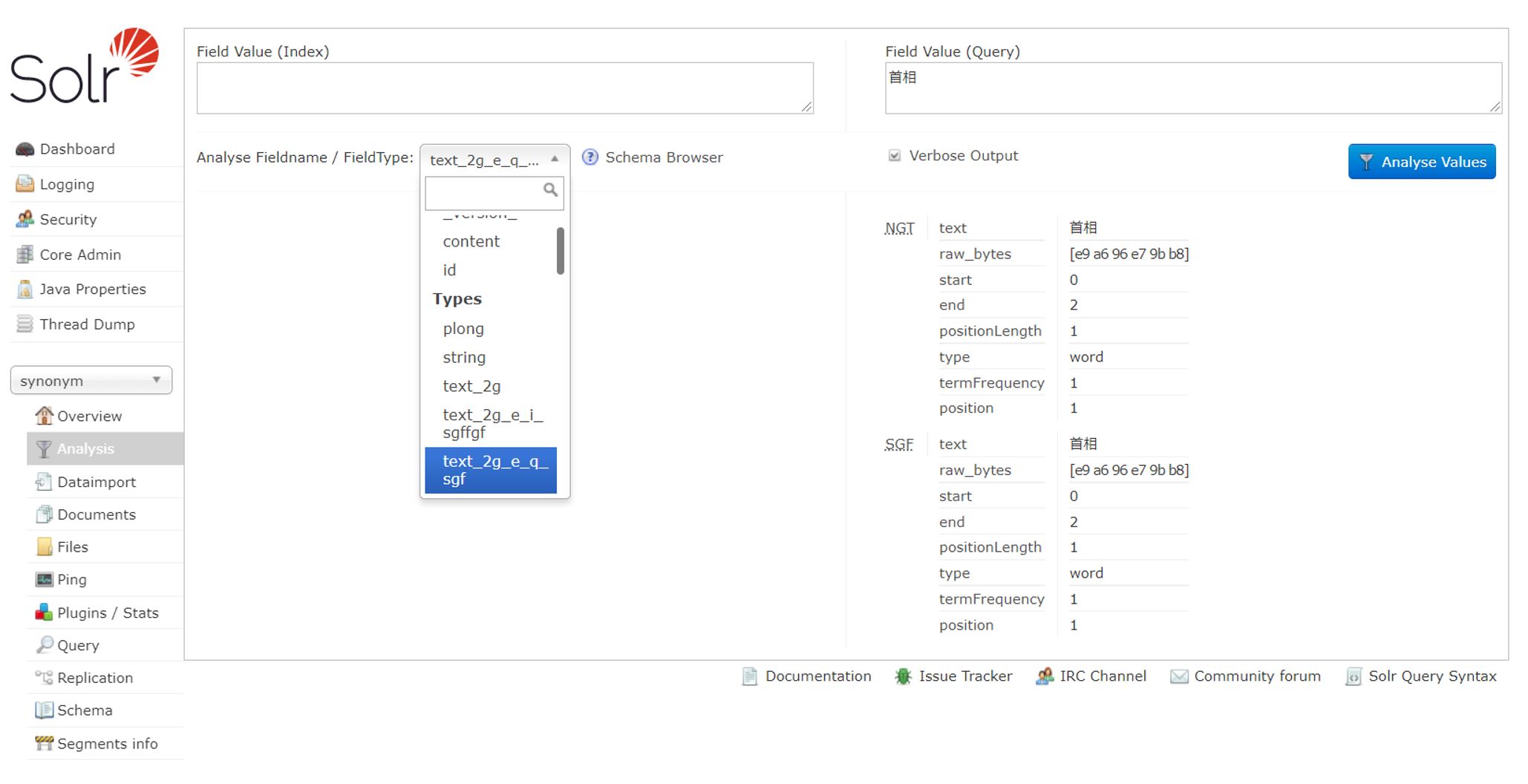
N-gram系はシノニム展開がなされない様であった。 一例として、Analysisでtext_2g_e_q_sgfのフィールド型をアナライズしてみると、首相という検索語に対しシノニムが全く適用されてないのが見て取れる。
N-gram系についてのシノニム適用は別の方法で行うことができるが、それは一番最後に述べることとする。
(ステップ2)正しいハイライトがなされるフィールド型の選出
正しい検索結果を返した上記3候補のフィールド型のうちハイライトについてテストを行う。
unified,original,fastVectorの3つの方式でテストを行った。 なお、fastVectorを使用するには、フィールドの定義で「termVectors=”true” termOffsets=”true” termPositions=”true” 」が必要になる。 これがないフィールドをfastVectorでハイライトしようとした場合は、Solrは自動的にoriginalでハイライトを行う。 fastVectorで検証する際には、お節介とも思われる仕様である。fastVectorのハイライトがうまくいったと思っていてもその実originalでハイライトされていたという事になりかねないからだ。 fastVectorがoriginalで動いたかどうかはログファイルもしくは管理画面のLoggingを見て確認する必要がある。
・ログファイル
2021-11-21 19:22:46.578 WARN (qtp307488715-50) [ x:synonym] o.a.s.h.DefaultSolrHighlighter Solr will use the standard Highlighter instead of FastVectorHighlighter because the does not store TermVectors with TermPositions and TermOffsets. field content_ja_nn_iq_sgffgfsgf_noterm
・Solr管理画面のLogging

(ステップ2)正しいハイライトがなされるフィールド型の選出結果
ほとんどの場合において正常にハイライトされた。
| id | 結果 |
|---|---|
| 1 | 首相でございます |
| 2 | 総理でございます |
| 3 | 総理大臣でございます |
| 4 | 内閣総理大臣でございます |
正常にハイライトされてないのは、以下の場合であった。
①text_ja_e_q_sgfのfastVectorによるハイライトが全くされない(結果は空文字である)
②text_ja_e_i_sgffgfを「総理」で検索した場合に、unified、fastVectorによるハイライトが以下となる。
unified方式の時
| id | 結果 |
|---|---|
| 4 | 内閣総理大臣でございます(「内閣総理」がハイライト対象になっている) |
fastVector方式の時
| id | 結果 |
|---|---|
| 4 | 内閣総理大臣でございます(「内閣」と「総理」が個別にハイライト対象になっている) |
fastVectorはTermQueryとPhraseQueryとBooleanQueryのみサポートしている。クエリ時シノニム展開するとSpanQueryになってしまうSynonymGraphはサポートできない。
text_ja_e_q_sgfの首相による検索時のクエリ式をdebugQuery=onとして見てみると以下のようになっている。
parsedquery_toString":"+(spanOr([spanNear([content_ja_e_q_sgf:総理, content_ja_e_q_sgf:大臣], 0, true), content_ja_e_q_sgf:総理, spanNear([content_ja_e_q_sgf:内閣, content_ja_e_q_sgf:総理, content_ja_e_q_sgf:大臣], 0, true), content_ja_e_q_sgf:首相]))
なお、content_ja_e_q_sgfの正常動作では、「総理大臣」、「内閣総理大臣」のハイライトは以下のようにトークン単位で行われるが、これは仕様である。
| id | 結果 |
|---|---|
| 3 | <em>総理</em><em>大臣</em>でございます |
| 4 | <em>内閣</em><em>総理</em><em>大臣</em>でございます |
結論
シノニムを適用しハイライトを行う場合には、以下が良いように思える。
- text_ja_nn_iq_sgffgfsgfのunified、original、fastVectorによるハイライト
- text_ja_e_q_sgfのunified、originalによるハイライト
- text_ja_e_i_sgffgfのoriginalによるハイライト
但し、正常にハイライトを行うという以外にも、以下①②のような注意が必要である。
①索引時のシノニム適用には以下のような特徴がある。
・シノニム辞書に変更があった場合に再インデックスが必要である。
・expandでシノニムを適用する場合には索引の肥大に繋がる。また文書長が長くなることでスコアが不当に低減する
②fastVectorに必要な「termVectors=”true” termOffsets=”true” termPositions=”true” 」も索引の肥大に繋がるので可能ならfastVector方式でのハイライトは避ける。
※unified又はoriginal方式で正確にハイライトができるのであれば、fastVectorによるハイライトは出来なくてもよい。
①②をかんがみると、シノニム展開を適用した場合の検索・ハイライト表示には、以下のフィールド型を使用するのがもっともよいように考えられる。
フィールド型text_ja_e_q_sgfのunified又はoriginal方式によるハイライト
<fieldType name="text_ja_e_q_sgf" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100" >
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/>
<filter class="solr.SynonymGraphFilterFactory"
expand="true"
ignoreCase="true"
synonyms="synonyms.txt"
tokenizerFactory="solr.JapaneseTokenizerFactory"
tokenizerFactory.mode="normal" />
</analyzer>
</fieldType>
以上、Apache Solrでシノニムを考慮した日本語の検索とハイライトにおけるベストプラクティスを得たわけであるが、このままでは日本語検索でほぼ必須とも言えるN-gramフィールドでシノニム検索ができない、ということになってしまう。そこでLUCENE-5252で提案されたこともあるNGramSynonymTokenizerを使って日本語シノニム検索とハイライトを追加検証してみよう。
NGramSynonymTokenizerを使ったN-gram系フィールドの日本語シノニム検索とハイライト
NGramSynonymTokenizerはロンウイットのSolrサブスクリプションやKandaSearchで利用できる。先頃リリースされたKandaSearch v1.2は開発コード名をSudaといい小規模ながらマーケットプレイス機能が導入され、NGramSynonymTokenizerはそのマーケットプレイスから無料配布されている。そこで以下ではKandaSearch上でNGramSynonymTokenizerを使って検証を行うことにしよう。
なお、Sudaというのは神田須田町から来ている。神田須田町にはその昔、神田青果市場が存在したことからv1.2で導入されたマーケットプレイスにちなんで付けられたらしい。
KandaSearchの基本的な使用方法については、以下の記事を参照されたい。
KandaSearch ではじめる Apache Solr 入門
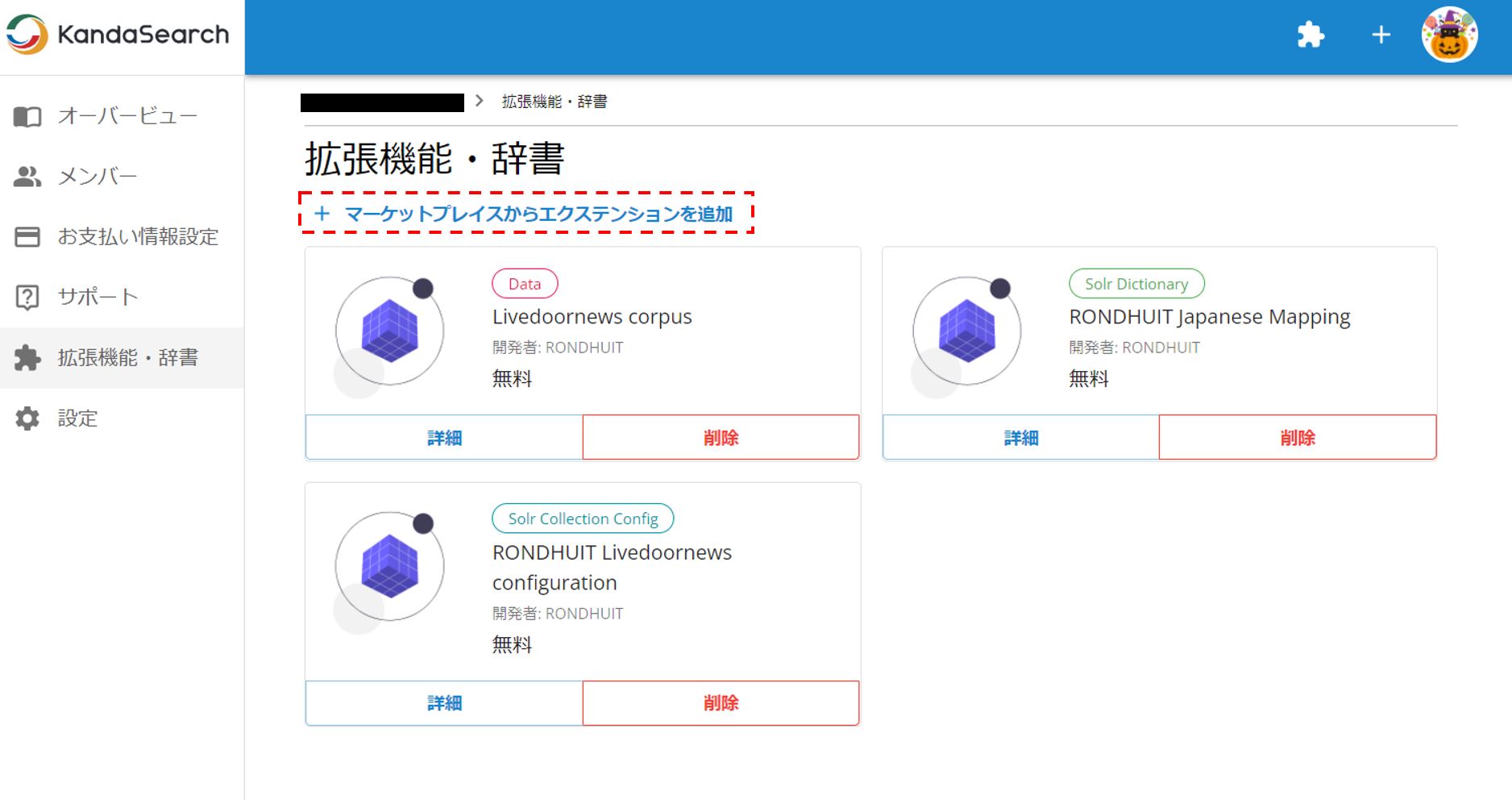
プロジェクトのオーバービュー画面の左にあるメニューバーから拡張機能・辞書を選択する。
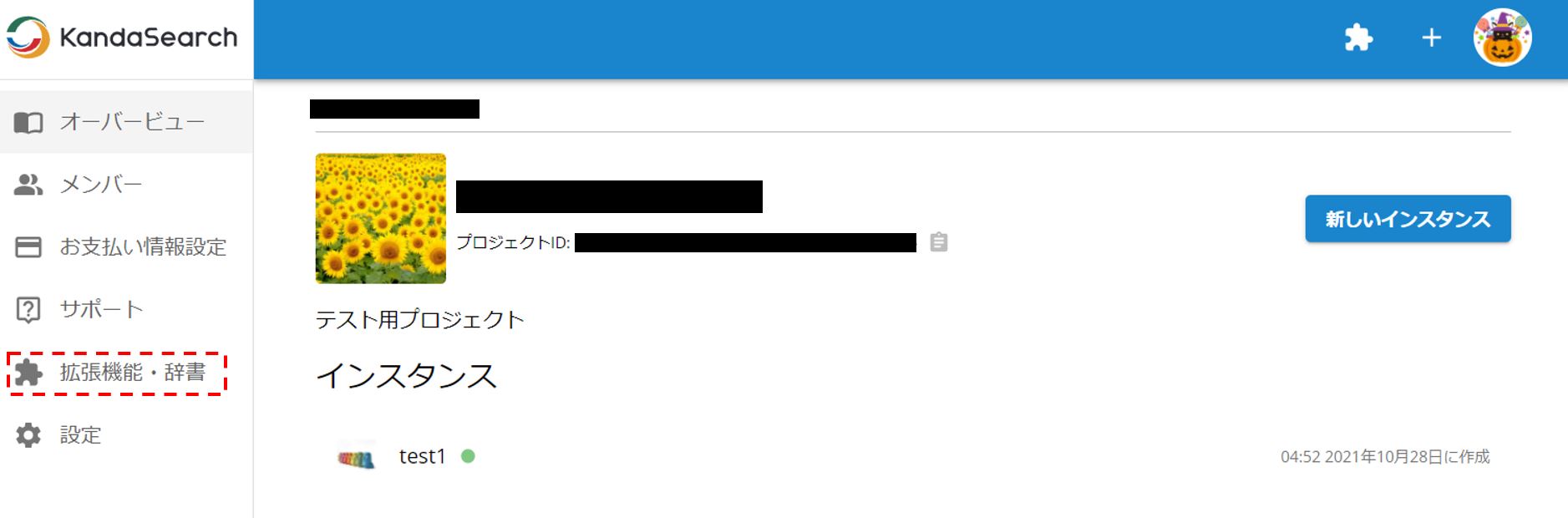
マーケットプレイスからエクステンションを追加する。
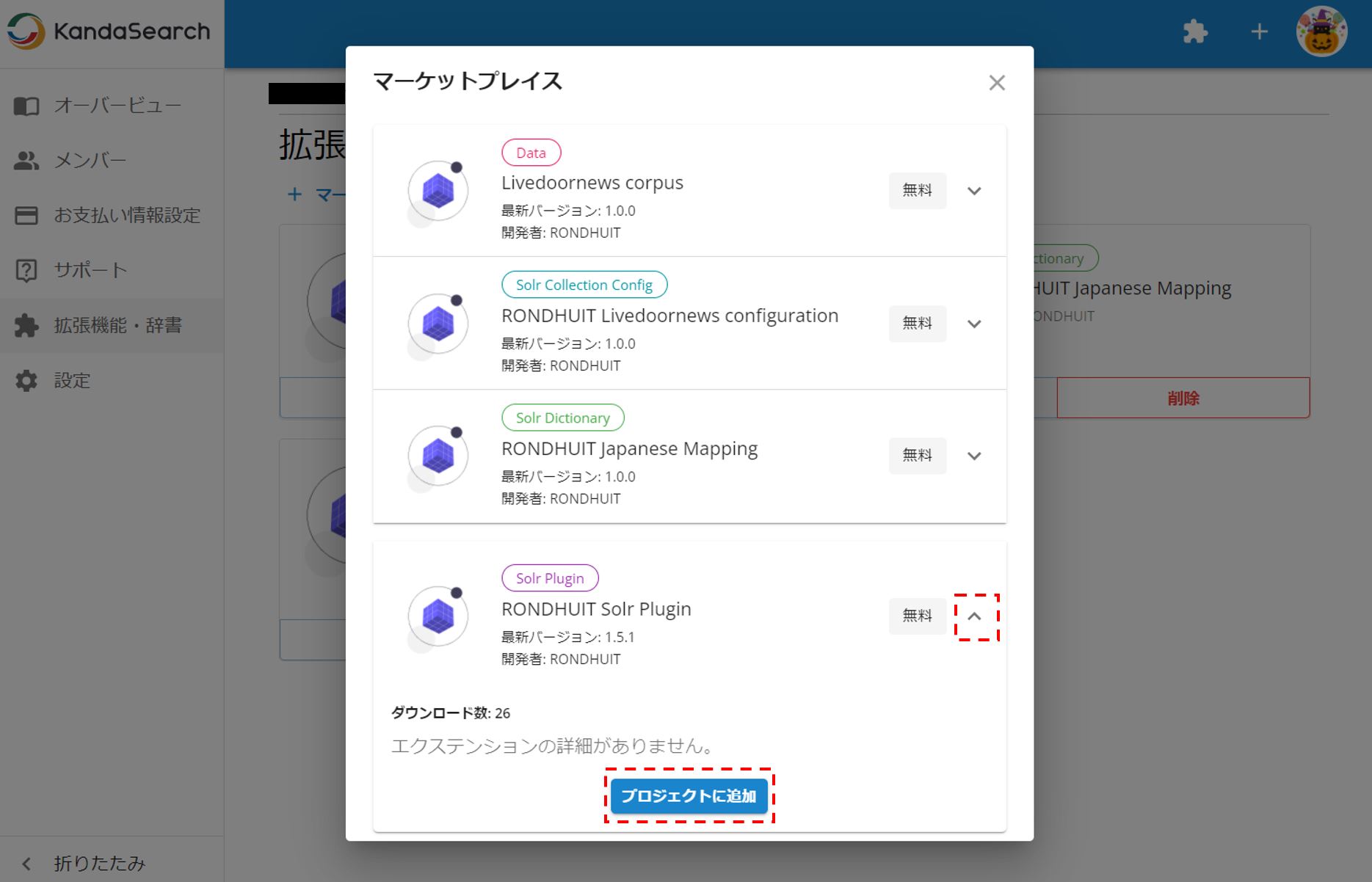
RONDHUIT Solr Pluginをプロジェクトに追加する。
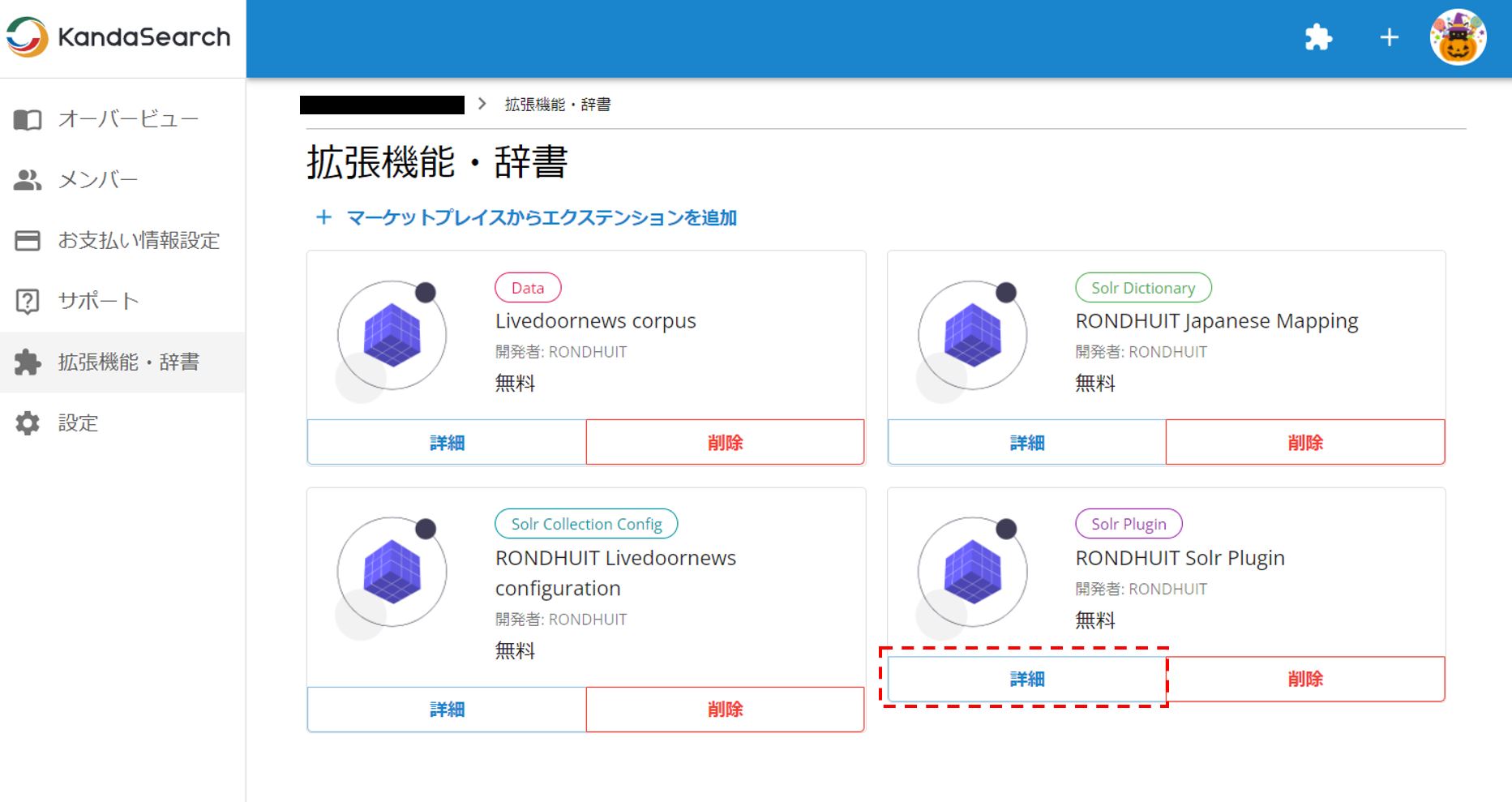
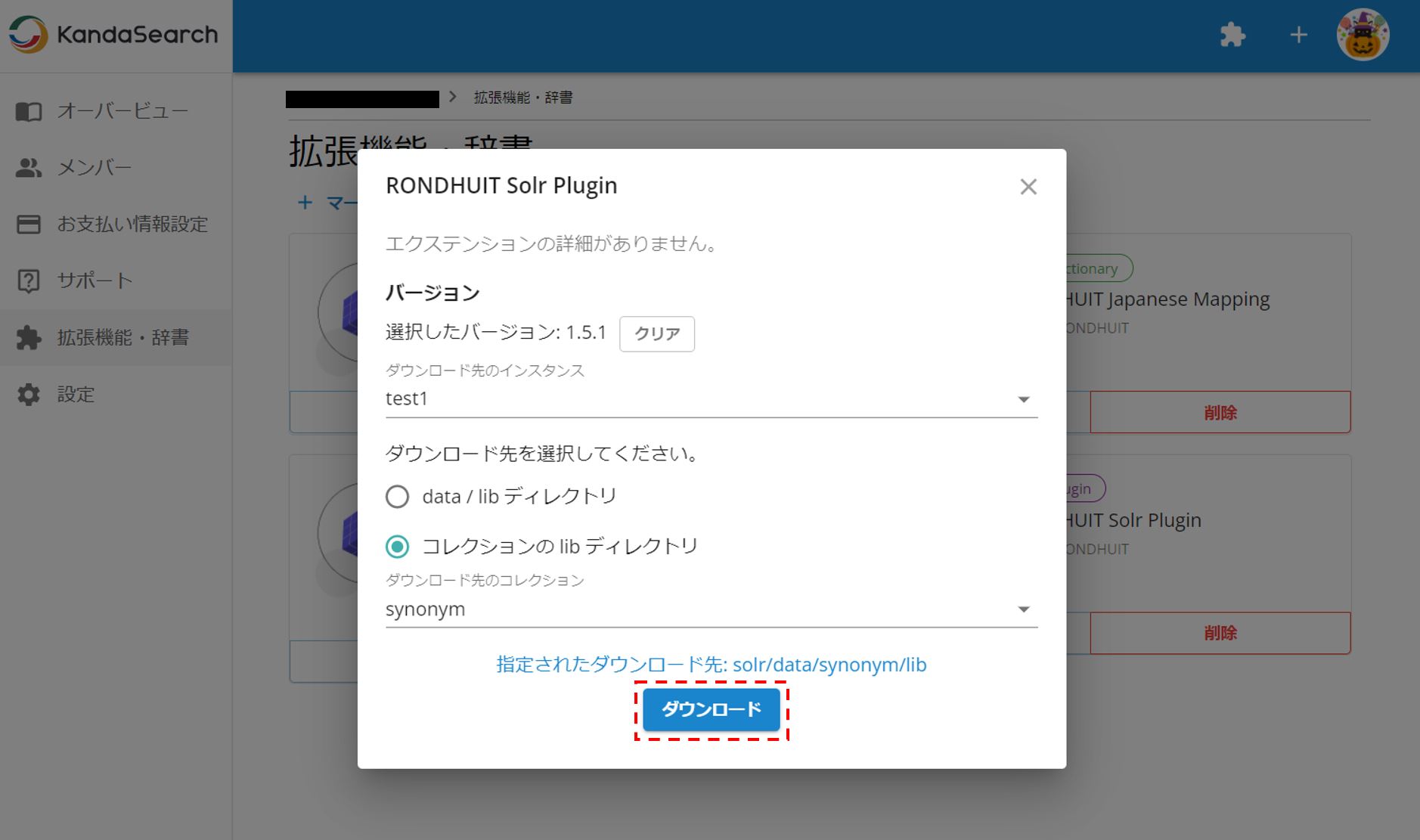
RONDHUIT Solr Pluginの詳細をクリックし、インスタンスにダウンロードする。
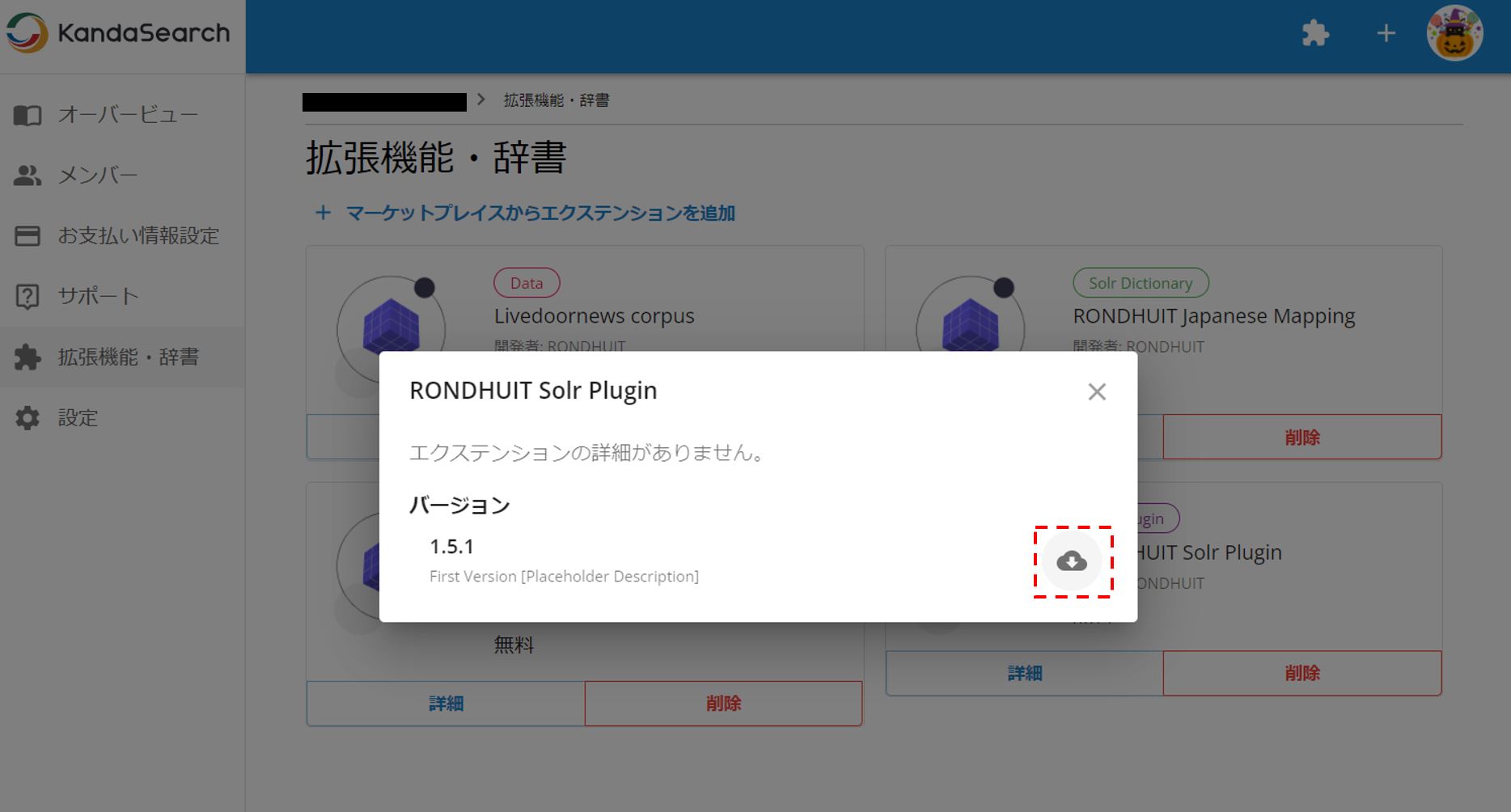
ダウンロード先のインスタンスとコレクションを指定し、ダウンロードする。
なお、全てのコレクションでこの機能を有効にする場合には、ダウンロード先をコレクションのlibディレクトリにするのではなく、data/libディレクトリにすればよい。
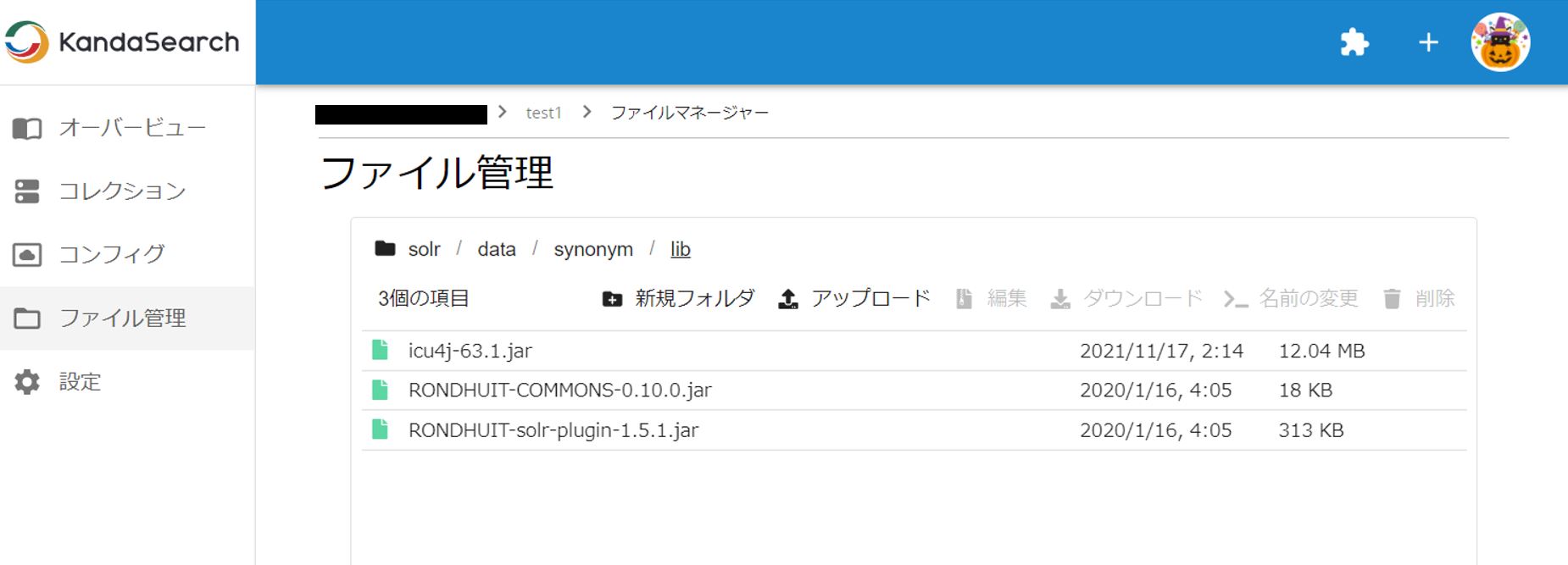
ファイル管理で確認すると、プラグインが追加されているのがわかる。
新しいフィールド型としてNGramSynonymTokenizerを使用したフィールド型を追加してテストしてみる。
なお、synonym適用をしていないtext_2gも追加しているのは、入力した検索語が(シノニム展開はされずとも)ちゃんとハイライトされるのかどうかを検証するためである。
<dynamicField name="*_2gs_nn_iq" type="text_2gs_nn_iq" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" />
<dynamicField name="*_2gs_en_iq" type="text_2gs_en_iq" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" />
<dynamicField name="*_2g" type="text_2g" indexed="true" stored="true" required="false" multiValued="true" termVectors="true" termOffsets="true" termPositions="true" />
<copyField source="content" dest="content_2gs_nn_iq" />
<copyField source="content" dest="content_2gs_en_iq" />
<copyField source="content" dest="content_2g" />
<fieldType name="text_2gs_nn_iq" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="false" synonyms="synonyms.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="false" synonyms="synonyms.txt"/>
</analyzer>
</fieldType>
<fieldType name="text_2gs_en_iq" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="true" synonyms="synonyms.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="false" synonyms="synonyms.txt"/>
</analyzer>
</fieldType>
<fieldType name="text_2g" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100" >
<analyzer>
<tokenizer class="solr.NGramTokenizerFactory" minGramSize="2" maxGramSize="2" />
</analyzer>
</fieldType>
N-gram系へのシノニム適用の結果
text_2gs_nn_iqは、正確な検索結果を返さなかったが、text_2gs_en_iqは、正確な検索結果を返し、ハイライトも全ての方式で正しくなされていた。
これは、シノニムに対しては、N-Gram分割はなされずにシノニム全体を一つのトークンとしてトークナイズするためである。 Solr管理画面のAnalysisを使用し、シノニムが適用された場合にどのようにトークナイズされるかを確認してみよう。
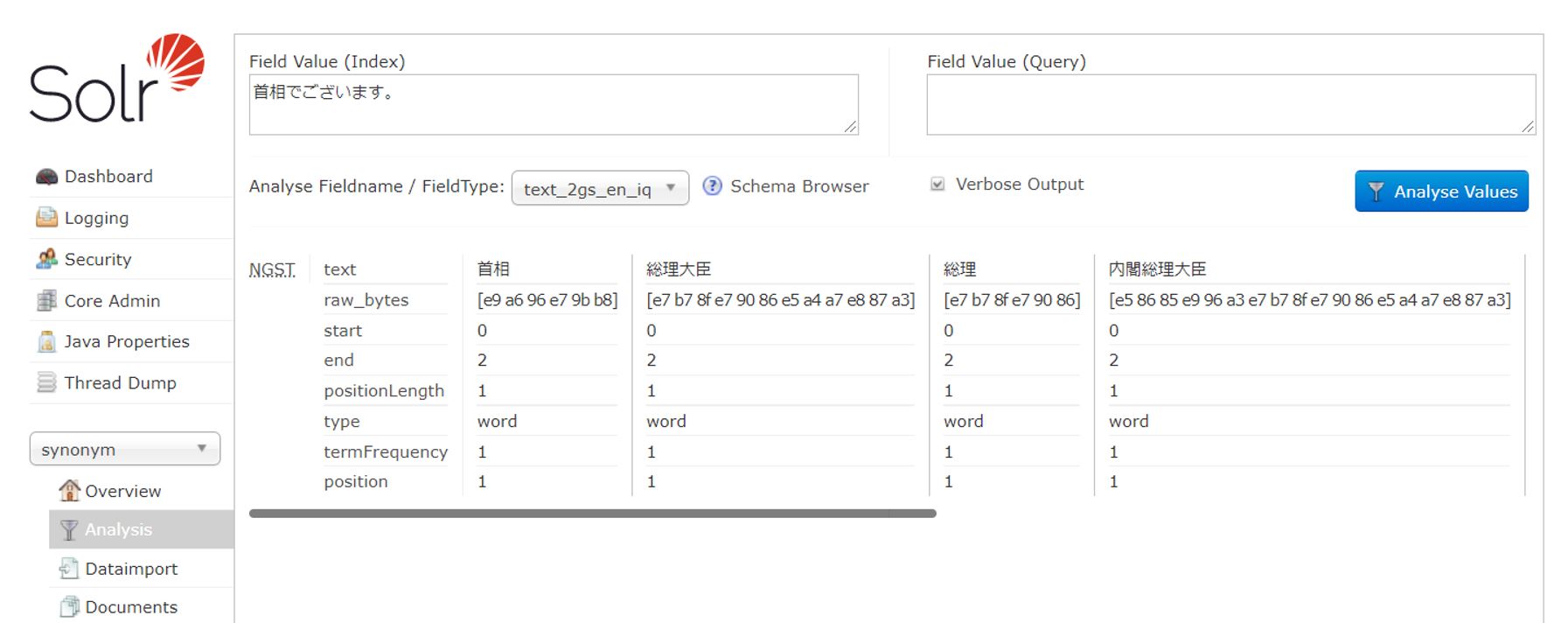
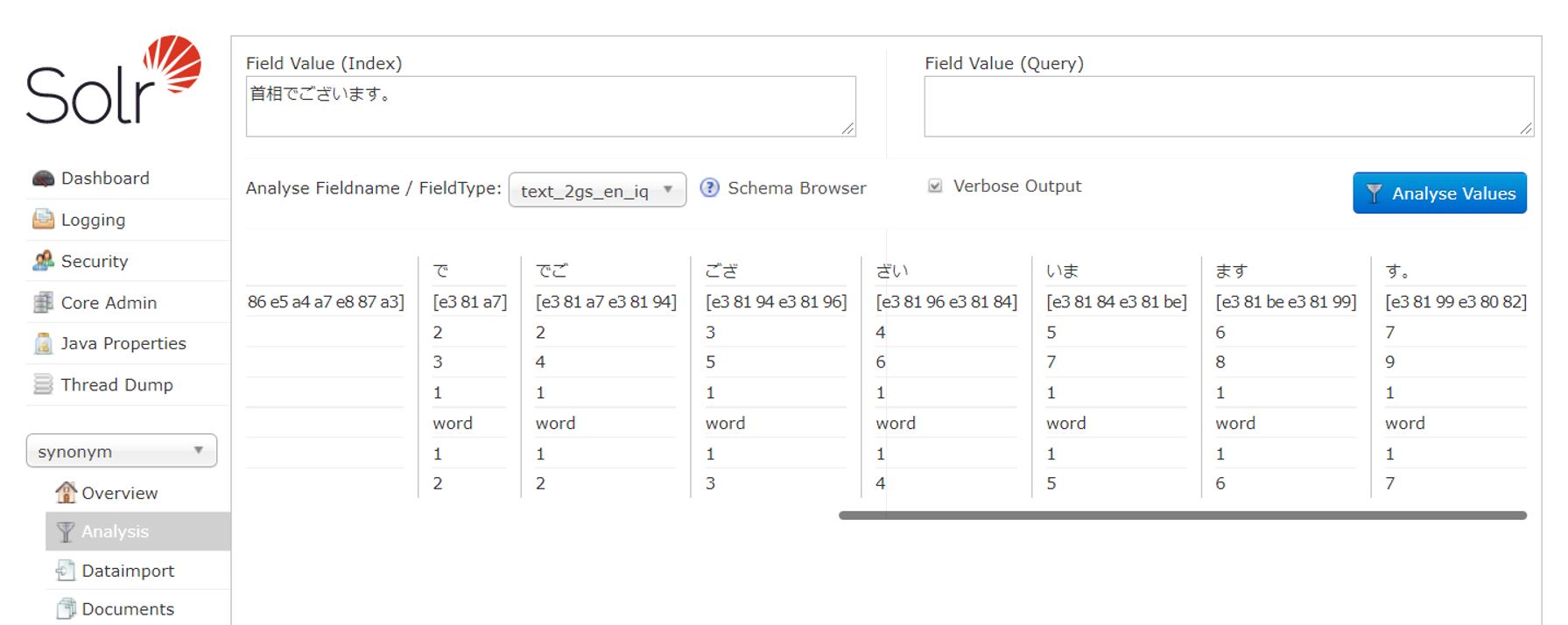
索引時にシノニム適用した場合は、シノニムがそのまま1つのトークンとして出力されている。
「首相」や「総理」はもともと2文字であるので確認しづらいが、「総理大臣」や「内閣総理大臣」が2-gram分割されずにそのまま出力されているので確認できるだろう。
また、シノニム以外の部分(「でございます。」)では、ちゃんと2-gramに分割されて出力されている。
一方、クエリ時にはシノニムの部分が以下のように展開される。
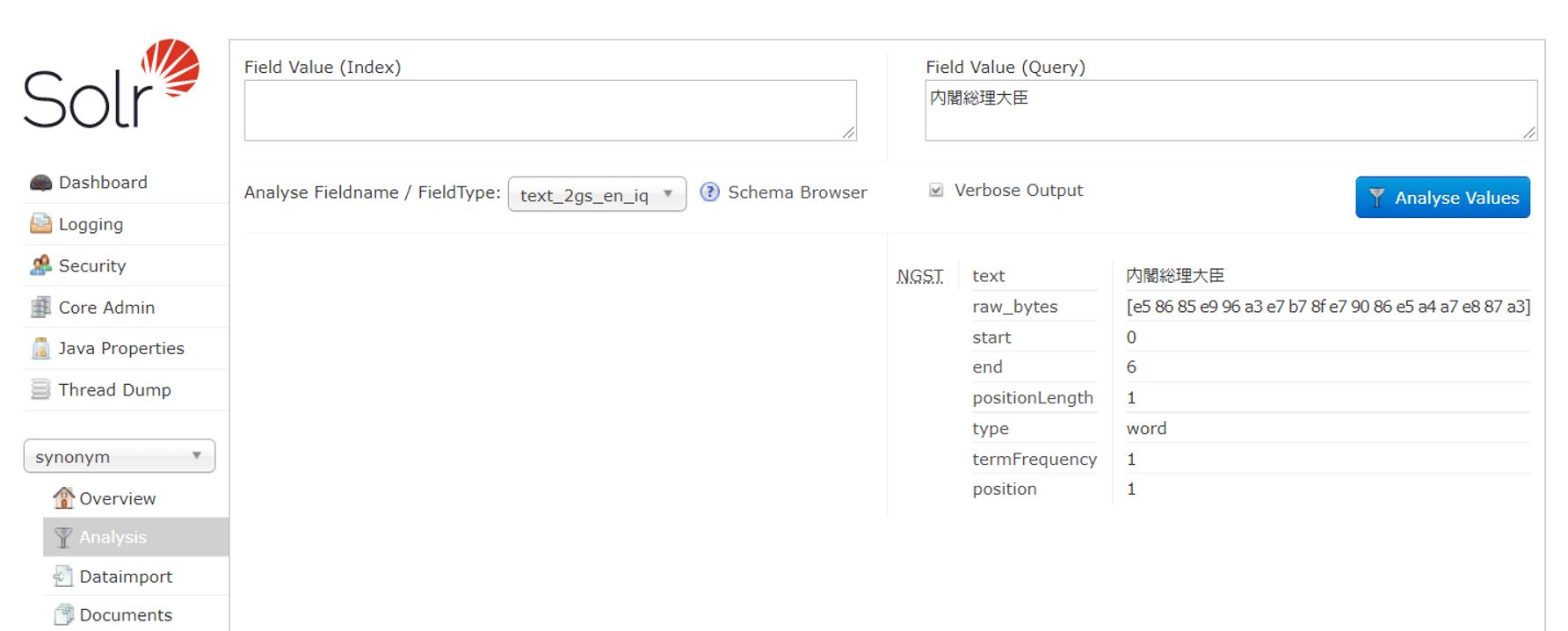
索引時同様2-gram分割はされていない。但し、注意していただきたいのは検索語が他の表記に正規化されていないということである。
expand=falseなら、「総理大臣」として出力されていいようなものであるが、NGramSynonymTokenizerの場合には正規化は行われずに単に、単一トークンとして出力される仕様のようである。
但し、索引がexpand=trueなら索引の方に「内閣総理大臣」は存在するので、検索結果となりうるというわけである。
なお、expand=falseの意味が正規化を行わないで単にシノニムを単一トークンとして出力するという仕様ならば、text_jaのフィールド型では無駄なので考える必要のない、ne(シノニムをインデックス時は代表表記に正規化、クエリ時は全展開)というのがtext_2gsでは意味を持つことになるのではと思い追加してみた。
つまり以下のようなフィールド型である。neであるがその意味は、インデックス時は代表表記に正規化せずに単一トークンとして出力、クエリ時は全展開という意味である。
<fieldType name="text_2gs_ne_iq" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="false" synonyms="synonyms.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="true" synonyms="synonyms.txt"/>
</analyzer>
</fieldType>
クエリを用いてこのフィールド型での検索を行ったところ、予想通りシノニム検索もハイライトも正常に行われた。
しかし、NGramSynonymTokenizerはインデックス側でexpand=true、検索側でexpand=falseで使うことだけを考えて作られているという事なので、このフィールド型を使用するのはもっと使用実績を積んでからの方がよろしいかもしれない。
それに、このフィールド型が使えたとしてもシノニム辞書を変更した場合に再インデックスが必要なことを忘れてはならない。
また、text_2gにおいてはシノニム展開こそされなかったものの入力した検索語に関しては検索結果に対し過不足なくハイライトがなされ以下のような結果になった。(どのハイライト方式の場合でも結果は同じ)
検索語が「首相」の場合
首相でございます
検索語が「総理」の場合
総理でございます 総理大臣でございます 内閣総理大臣でございます
検索語が「総理大臣」の場合
総理大臣でございます 内閣総理大臣でございます
検索語が「内閣総理大臣」の場合
内閣総理大臣でございます
N-gram系へのシノニム適用の結論
上記の結果より、N-gram系でシノニム展開を適用した場合の検索・ハイライト表示には、NGramSynonymTokenizerを使用した以下のフィールド型を使用するのがもっともよいように考えられる。
フィールド型text_2gs_en_iqのunified、original、fastVectorによるハイライト
<fieldType name="text_2gs_en_iq" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="true" synonyms="synonyms.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.rondhuit.solr.analysis.NGramSynonymTokenizerFactory" n="2" expand="false" synonyms="synonyms.txt"/>
</analyzer>
</fieldType>
本記事がお客様の業務に少しでもお役に立てば幸いです。
著者略歴
某精密機器メーカーにてNLP業務に従事し、形態素解析器、全文検索エンジン(転置索引)、強調表示器作成を担当する。その後、音声入力による質問応答タスクの研究や多言語翻訳システムの構築等を経験。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!